The Evaluator
Your go-to blog for insights on AI observability and evaluation.
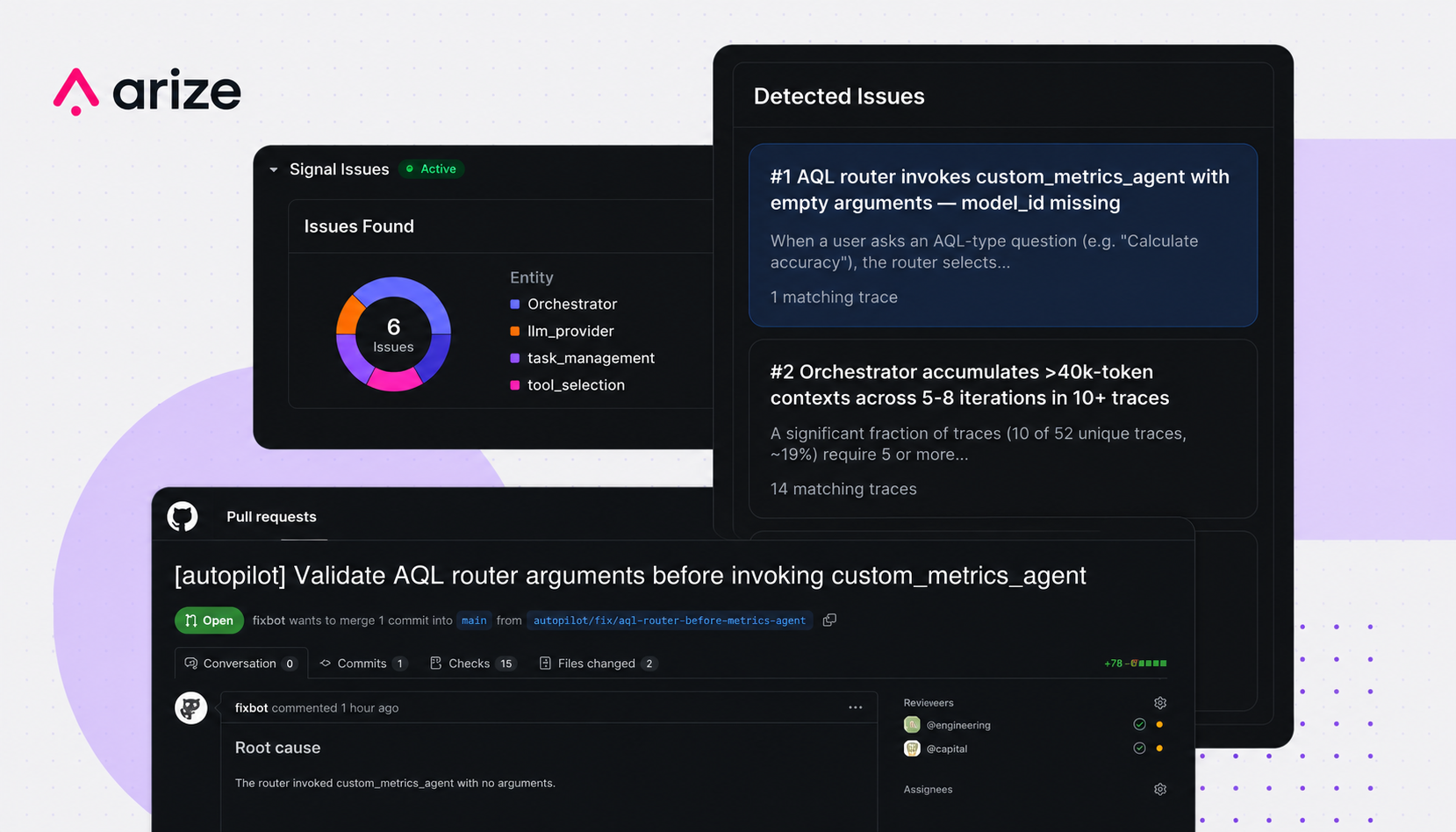
From Signal to PR: What if your agents got better every time they failed?
Signal, a managed agent built into Arize AX, continuously reviews production traces, surfaces ranked issues with evidence and proposed fixes, and — with Managed Agents — can carry investigations into your codebase and open pull requests.
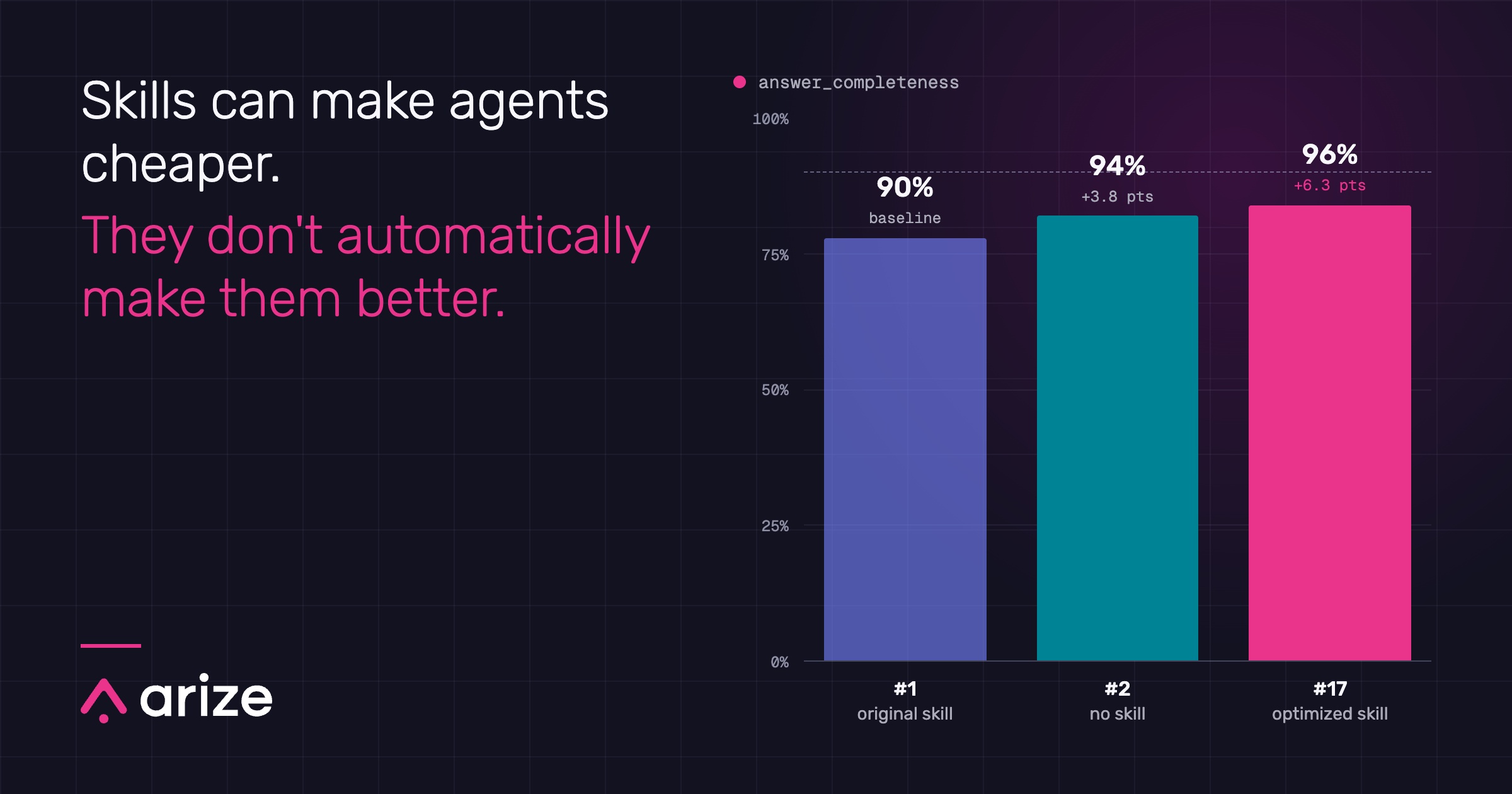
How to improve agent skills with tracing and evals
A skill cut agent costs by 44% and latency by 56%, but also reduced answer completeness. Here’s how tracing, evals, and a long-running agent exposed and corrected the regression.

AI agent evaluation: Tips from Anthropic on building evals you can trust
Learn how to build trustworthy AI agent evals using regression tests, capability evals, production traces, LLM judges, and reproducible environments.
Sign up for our newsletter, The Evaluator — and stay in the know with updates and new resources:

How Booking.com scales AI observability with Arize
How Booking.com built a unified AI observability stack with Arize for agentic GenAI workflows and traditional ML — from telemetry collection and PII redaction to latency monitors and evaluations.

How to write effective AI agent skills: 6 data-backed practices
Three recent studies show what actually makes an AI agent skill effective: human expertise, compact procedures, tight routing, harness-specific testing, and eval-gated changes—not longer Markdown.
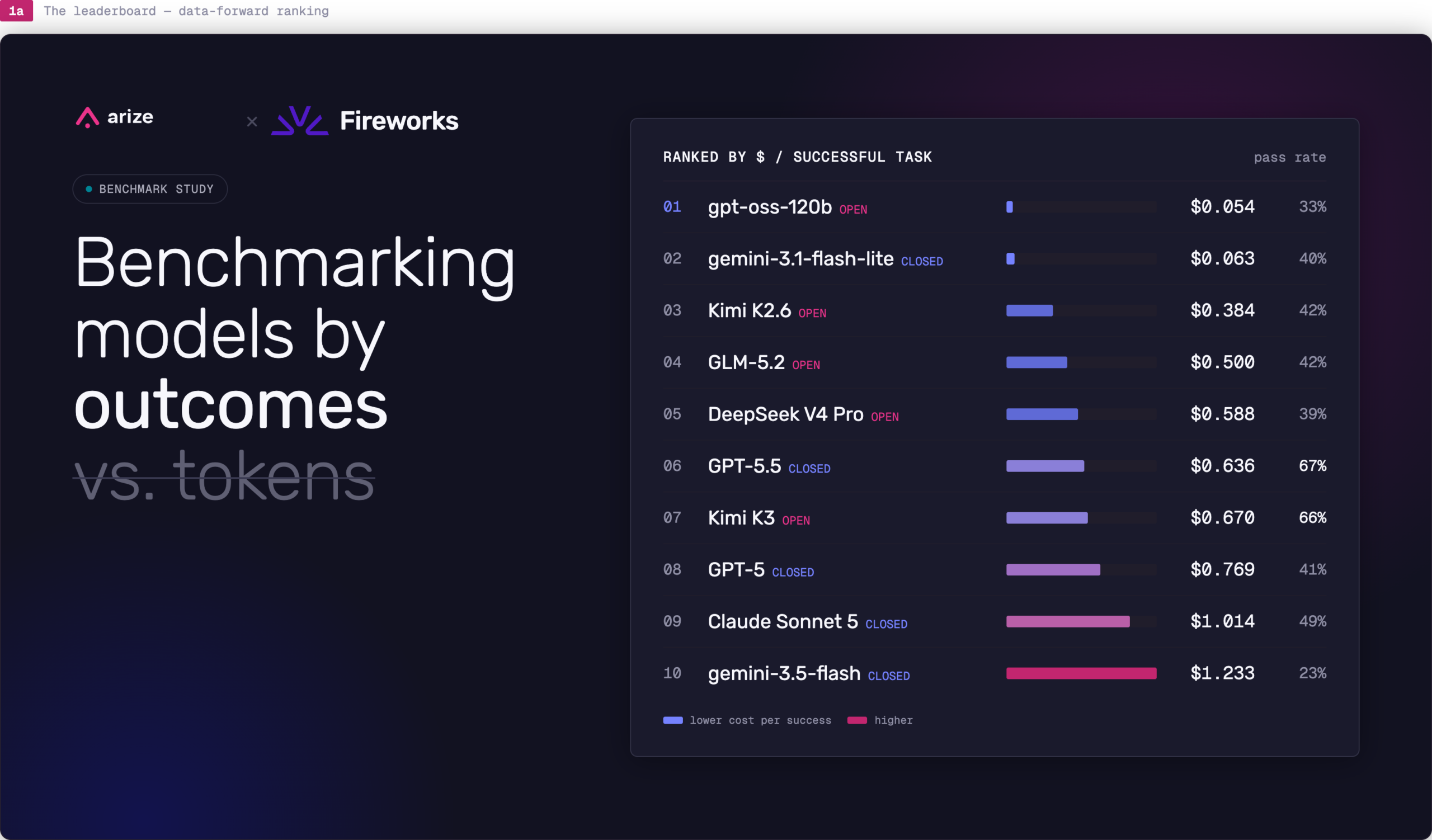
Cost per successful task: Benchmarking Kimi K3, GPT-5.5, and 8 more AI models
Arize and Fireworks benchmarked 10 AI models across 2,400 agent runs. Learn why cost per successful task beats token price for model evaluation and routing.

How to measure human-LLM judge alignment
No single metric proves an LLM judge is trustworthy. This field guide shows how to measure human–human agreement, compare it to LLM–human agreement, and diagnose errors with precision, recall, and F1.

How OpenAI uses human feedback to evaluate and improve LLMs
At ChatGPT scale, user frustration arrives as support tickets, ratings, social posts, and corrections buried inside conversations. OpenAI built a feedback system that can find the pattern behind a complaint, retrieve the evidence around it, and send an agent toward the code.

Inside Cursor’s agent factory: how it verifies AI-written code
As background agents take on more implementation work, Cursor is rebuilding the software development lifecycle around risk scores, developer-like environments, video evidence, and review systems that learn from every human correction.

Kiro CLI observability: trace and evaluate agent changes with Arize Skills
Use Arize Skills with Kiro CLI to trace coding-agent changes, build datasets from failures, run experiments, and validate prompts before shipping.


