




This blog was written in collaboration with Amit Goren, Group Product Marketing Manager at Arize
Using Arize and OpenAI together can help organizations better build unstructured models and monitor and troubleshoot those models in production, lowering costs and maximizing performance.
NLP Models Are Tough To Get Out Into the Real World and Monitor Once Deployed
According to multiple analyst estimates, over 80% of data is unstructured information like text, images, video, or audio. Leveraging this data for deep learning is time and resource-intensive. Unstructured data such as text requires some human labeling or annotation for teams to be able to group the data and find trends and insights. Given the difficulty in finding similarities, generating embeddings can help lower the dimensions and enable teams to better understand and visualize unstructured data.
When an unstructured model such as a natural language processing (NLP) model is ready to be deployed to production, teams frequently lack adequate tools to monitor and troubleshoot issues that may exist or emerge after deployment.
OpenAI Helps You Build Unstructured Models
OpenAI is an AI research and deployment company. Their mission is to ensure that artificial general intelligence — highly autonomous systems that outperform humans at most economically valuable work — benefits all of humanity. With AI systems like GPT-3, Codex and DALL-E, OpenAI provides the AI building blocks to power the next generation of products. Given a simple text-based instruction in natural language, GPT-3 and Codex returns a text or code completion. Given a text-based prompt, DALL-E renders photorealistic images or art. Together, these generative models open up a new world of use cases and applications.
Earlier this year, OpenAI released three families of embedding models for different functionalities: text similarity, text search and code search.
- Text Similarity: Text similarity models provide embeddings that capture the semantic similarity of pieces of text.
- Text Search: Text search models provide embeddings that enable large-scale search tasks, like finding a relevant document among a collection of documents given a text query.
- Code Search: Code search models provide code and text embeddings for code search tasks.
Arize Helps You Monitor and Improve Your Unstructured Models
Arize is an ML observability platform that enables teams to log both structured and unstructured data to detect, root cause, and resolve model performance issues faster. With Arize’s purpose-built workflows for root cause analysis, teams can reduce time-to-resolution for even the most complex models.
Arize’s latest release includes support for embeddings to monitor and troubleshoot unstructured data models. By monitoring embeddings of their unstructured data, teams can proactively identify when their data is drifting and troubleshoot using Arize’s interactive UMAP visualization to identify new patterns or export segments for high-value labeling.
Example With Code
Here is an example of how to use OpenAI and Arize AI together for an NLP use case.
OpenAI
First, we need a vector representation or embedding of our input text. OpenAI offers a variety of models that can extract said embedding using just a couple lines of code.
Arize AI
Once we have our data, including the embeddings associated with the input text, the first step is to set up the Arize client. We will log the data afterward. Copy the Arize API_KEY and SPACE_KEY from your Arize Space Settings page to the variables in the cell below. We will also be setting up some metadata to use across all logging.
Next, we set up the Schema. A Schema instance specifies the column names for corresponding data in the dataframe. While we could define different Schemas for training and production datasets, the dataframes have the same column names, so the Schema will be the same.
Arize allows you to ingest not only the embedding vector, but the raw data associated with that embedding, or a URL link to that raw data. Therefore, up to three columns can be associated to the same embedding object*. To be able to do this, Arize’s SDK provides the EmbeddingColumnNames class, used below.
*NOTE: This is how we refer to the 3 possible pieces of information that can be sent as embedding objects:
- Embedding
vector(required) - Embedding
data(optional): raw text associated with the embedding vector - Embedding
link_to_data(optional): link to the data file (image, audio, …) associated with the embedding vector. Not represented in this example, learn more here.
Finally, we can send our data to Arize by using the log()method.
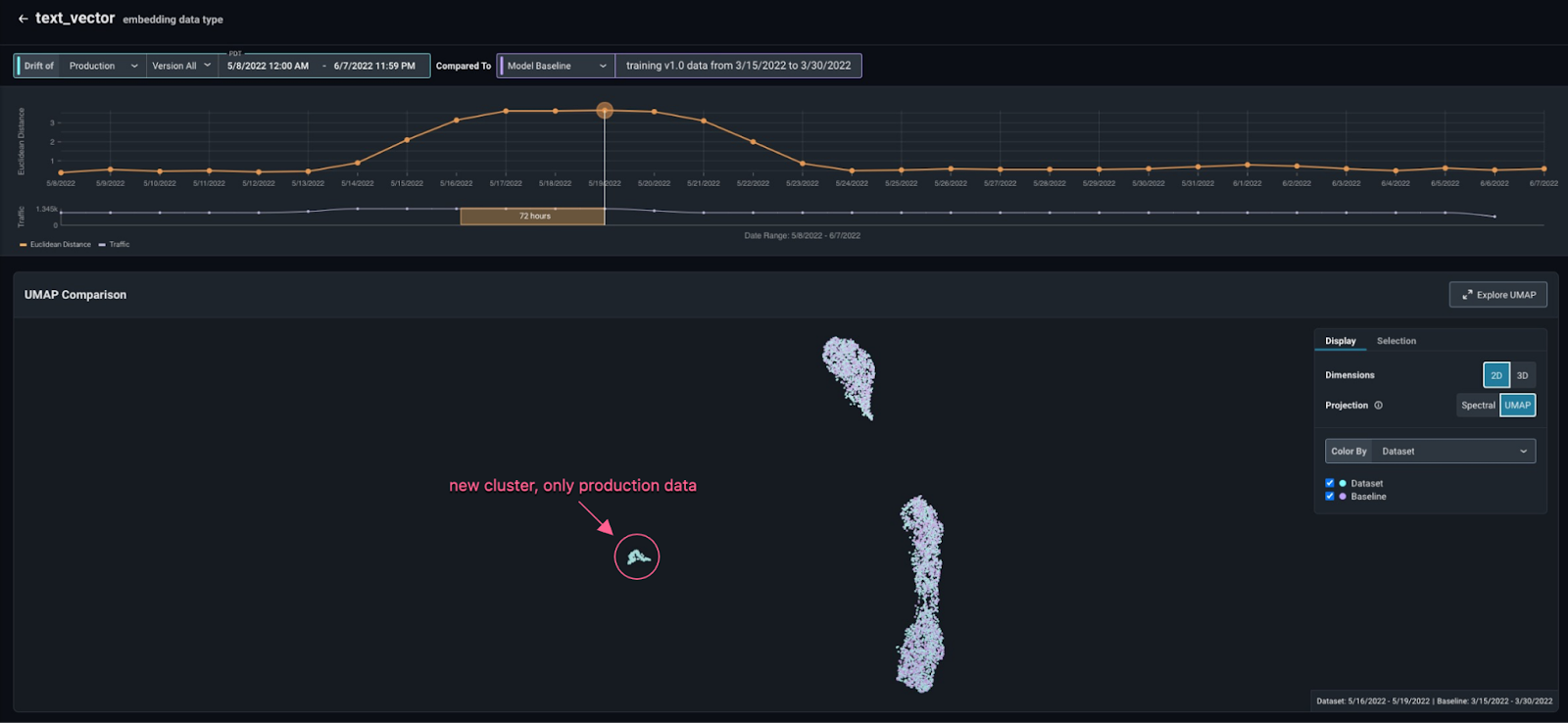
Once the data is in Arize and you set a baseline (i.e. training data), you can begin to troubleshoot. Here is an example of a drift tracking plot and a UMAP visualization of the data. In this case, both training and production data are superimposed, but another cluster of production data has appeared. This indicates that the model sees data in production qualitatively different from the data it was trained on, causing performance degradation.
Start Your Journey
Check out the full Colab on multi-class sentiment classification using OpenAI here and get started by signing up for your free Arize account.
Questions? Join the Arize community to learn from peers and get notified about workshops and events.