

The Death of Central ML Is Greatly Exaggerated

Claire Longo
Customer Success Lead
Don’t throw in the towel on centralized machine learning (ML) teams yet; here’s how to get it right
Over the last decade, the industry has gone from celebrating the rise of the “central ML team” to questioning whether it should exist. I can’t help but feel like I’m watching Rome burn. It doesn’t have to be this way.
Why It’s Becoming Trendy To Bash Central ML
As the emerging field of machine learning operations (MLOps) continues to grow rapidly and new tools and techniques proliferate, the potential for confusion and discord – even among sophisticated data scientists and machine learning (ML) engineers – is high.
One area where this is on full display: debates on the ideal team structure for machine learning organizations are heating up. In conferences and technical communities alike, a theme is emerging: centralized ML teams – once hailed internally as AI centers of excellence – appear to be falling out of favor. A recent blog published by Tecton on “Why Centralized Machine Learning Teams Fail,” for example, argues in favor of disbanding traditional centralized data science teams that rely on IT to productionize models, instead “embedding data scientists and data engineers onto the product teams that are using machine learning.”
While embedding machine learning engineers and data scientists into the businesses they serve is worthwhile for certain companies – and, indeed, is part of a big revamp underway at Meta and other companies like Kohl’s – it is actually is only part of a potential solution and does not directly address the bigger and more interesting question of whether, when, and how you might still use a central ML team in tandem.
This is an important question to answer. If the industry does not start talking about how and whether to centralize ML the right way, it may miss out on an elegant solution to the biggest ML and data problems out there.
Why listen to me on this subject? My career has been spent building and scaling ML teams, including at Opendoor and Twilio. My experience as both a data scientist and ML engineer at companies with and without a centralized machine learning strategy also gives me a unique window into the pain points from which this solution grew. Today, in my role at ML observability company Arize AI, I have the privilege of working with dozens of leading central ML teams and learning from their pitfalls and successes along the way. This piece on how to do centralized machine learning the right way is informed by that experience.
A Working Definition of Central ML
First things first; what is “central ML” exactly? While there is some equivocation on the term, generally a “central ML” team – also called an “ML platform” or “ML infrastructure” team – is a platform engineering group responsible for designing, building, and curating the suite of tooling for data scientists at a company. In short, its purpose is to provide a unified and standardized experience for ML application development.
Like other core engineering teams, the central ML team was born out of pain – specifically, the painful process of creating new tools and processes from scratch to build and deploy ML models. By providing tools ready for a variety of use cases, central ML frees data scientists to quickly and efficiently integrate ML models while adhering to some standard MLOps and software engineering best practices that ensure the quality of the model is maintainable.
How Are Typical Teams Structured and What Are the Alternatives To Central ML?
Central ML teams did not emerge overnight; they evolved over time to meet a need. To illustrate why that need emerged, here are three composites of typical machine learning organization team structures.
Structure One: The Traditional Approach
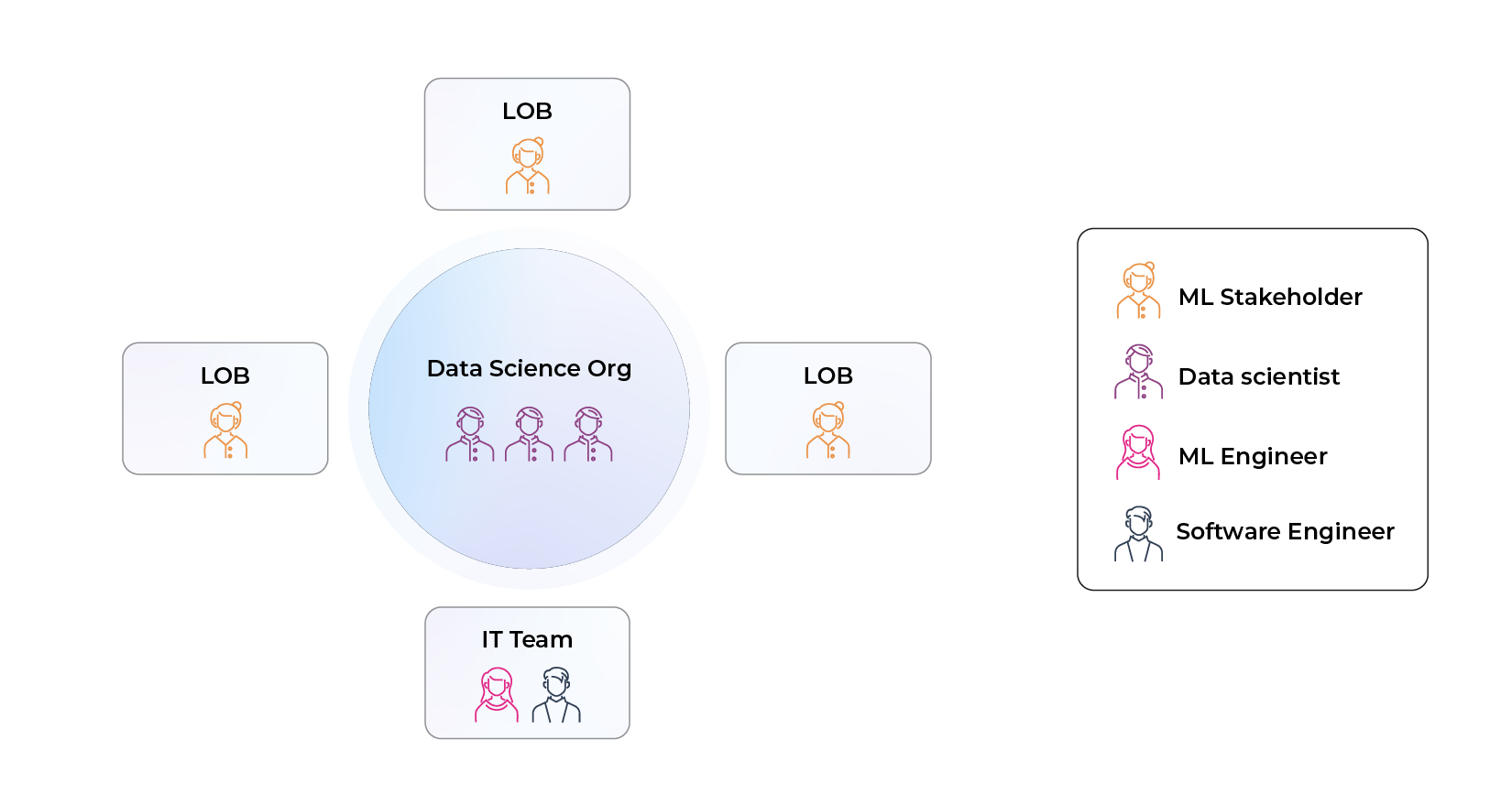
In this structure, a team of data scientists acts as an internal consulting group that builds out new ML use cases and trains models. They then rely on existing IT or engineering teams to productionize these models and deploy them into the real world.
While this can work in a small organization with clearly articulated business needs and ML use cases, it often frays at scale. As companies grow, the gap between the data scientists who train new models and the engineers who deploy and maintain them in production become chasms that slow down model velocity, impact model performance (i.e. training-serving skew), and lead to breakdowns in retraining regimens. Similarly, the divide between the lines of business who know the product and customer needs best and ML practitioners can mean lots gets lost in translation.
Structure Two: Decentralized ML
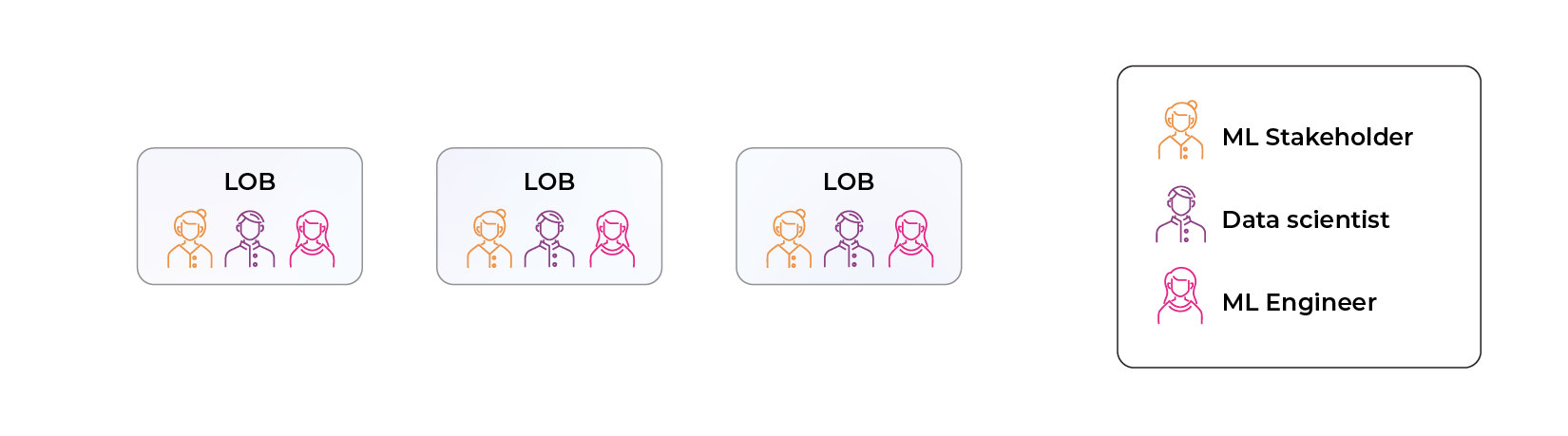
In this structure, data scientists and machine learning teams are reunited and embedded into the individual lines of business for easier collaboration. By teaming up with product managers and business executives, ML practitioners are ultimately in a better position to train models that consistently drive results.
This approach isn’t without its challenges however. Why? Individual teams choosing their own technology can be a recipe for chaos. Each new data science model project becomes a startup of its own, and it takes a while to start a new ML company from the ground up – especially one that spans the full ML lifecycle from data preparation to model building, deployment, serving, monitoring, and retraining. Many lack the skill set to do this – a team of skilled data scientists, for example, might have expertise in choosing and training the best ML model but lack the background in MLOps or software engineering to integrate those models – and most don’t have the luxury to wait a year or more for their first model in production.
One other limitation of this approach is that it sometimes turns individual lines of business into islands, each with different ways of working, different technology deployed, and different metrics for success. With everyone distributed into individual lines of business, an organization might miss out on macro-level insights and economies of scale.
Structure Three: Central ML
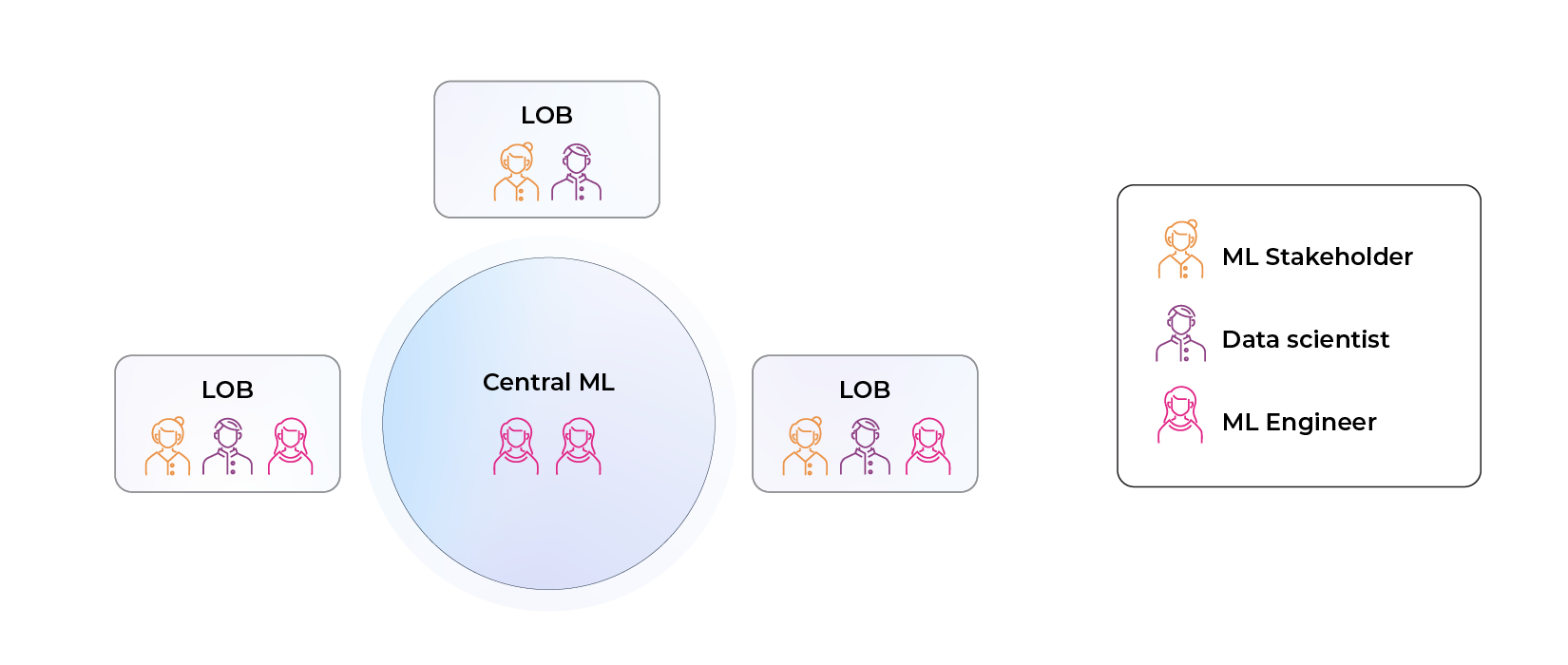
There are different variations of central ML organizations that work. One such structure is a central ML hybrid that blends what is great about decentralized ML while also providing a dedicated team for building, buying, integrating, and maintaining new tools (central ML). Many companies start off with platform engineers in central ML and data scientists embedded into the line of business, adding additional machine learning engineers into the lines of business over time. Done well, this is the ideal team structure for most mature enterprises and mature data organizations.
Of course, it’s not without its challenges (more on that below).
The Challenges of Central ML
Delivering effective end-to-end ML solutions at scale is hard. Here are a few things that go wrong with even the best central ML teams.
The Tooling Lock
- Problem: When individual data teams are required to rely on the ML infrastructure provided by central ML, they lose the autonomy to choose their own technology.
- Solution: Central ML should never be a dictatorship. With the goal of supporting ML efforts across the organization, central ML teams can implement processes to align tooling needs to business objectives and carefully evaluate tradeoffs. They can also have flexibility to adapt as new use cases arise.
The Fight To Get On the Roadmap
- Problem: It can be challenging for data scientists to get their projects on a central ML team’s roadmap in an environment where there is a finite set of expertise, resources, and time. At its worst, tech-obsessed ML platform engineers might build a state-of-the-art feature store that few wanted while not prioritizing what might be more pressing issues to the business.
- Solution: A hybrid organizational structure, where you have data scientists and machine learning engineers embedded into the businesses collaborating directly with a central ML team, helps to overcome this challenge by bridging gaps and spreading out specialized knowledge.
The Fence
- Problem: Central ML can create a fence where data scientists have to throw their ML models to an engineering team to deploy, resulting in a lack of end-to-end ownership of the project.
- Solution: The best ML platform teams remove fences by reducing direct reliance on them for any given project, instead empowering stakeholders through self-serve oriented tooling, solutions, and best practices.
Central ML Done Right
No team is flawless, but there are many central ML teams getting this right. They tend to share a few characteristics:
- They have a centralized component as well as individual engineers on customer teams
- They build preemptively – by practitioners, for practitioners – to anticipate future needs
- They understand and look for ways to overcome customer pain points
While these are all important things to keep in mind, optimal approaches vary.
Org Structure Matters
Especially as a company grows, organization structures really matter. What the right ML team looks like is going to evolve over time and scale with the company through the different growth phases. Meta moving key central ML groups into product organizations, for example, might just be them reaping the benefits of having built everything they need – data scientists can deploy their models in a low-code environment, efficiently adjusting some configurations and getting their model up and running in a matter of a simple effort. That’s the ultimate goal for everyone, but how do we get there?

Startups
In this phase, teams must stay scrappy. Frequently, they begin an ML journey with one or a few full stack data scientists capable of spinning a lot of plates at once. One way to think about the “full stack data scientist” is as a data, ML, and software engineering generalist who can both train and deploy ML models. These team of fixers stand up scrappy minimum viable products (MVPs) while designing a vision for the long term ML strategy for the company.
Fast-Growth Companies and Enterprises
When a company is growing quickly or an enterprise is investing in ML for the first time, it’s critical to get a good foundation in place. Before bringing in an army of data scientists, it’s worth considering setting up a central ML. Ultimately, it’s easier to build good ML infrastructure and then ramp up model velocity than vice versa. When data scientists join the organization and get embedded into each line of business, they will find themselves supported with access to clean and maintained data and easy-to-use tooling to perform research, experimentation, and deploy their models. Don’t make the mistake of centralizing ML too late!
Mature ML Companies
Large companies with mature data organizations and solid infrastructure can now afford the luxury of letting people specialize. Maintaining a large central ML team while embedding ML engineers on product teams to work alongside data scientists creates a wonderful synergy. Data scientists and machine learning engineers can focus on what they do best – training state-of-the art ML models and productionizing them, respectively – while software engineers and machine learning platform engineers can keep their focus on building and maintaining ML infrastructure to support those efforts.
People Matter
Of course, organizational structure alone isn’t everything. For central ML to succeed, it needs a leader with a strong voice and vision who will drive a coherent ML strategy company-wide. This leader should:
- Have a vision for the future of ML infrastructure
- Intrinsically understand the business problems and underlying reasons behind requests
- Have a deep understanding of ML and MLOps (not just software engineering)
- Not live in a bubble; rather, they are passionate both about the frontiers of technology AND adding value to the business
- Be measured on whether they accelerate model velocity and whether models are delivering business value
Central ML also requires a unique team. ML platform engineers need to have a deep knowledge of the fundamentals of machine learning and/or core concepts around data science modeling. The engineers should know their audience and know their pain; without that foundation, building tools to solve these problems is difficult.
How You Build Matters
The organizational culture and mindset with which a central ML team approaches projects will influence the team’s success. Great central ML teams all often have a few key things in common:
- They build with a focus on automation and standardization. As true engineers, they are looking to optimize and improve efficiency and quality.
- They don’t build in a silo. They understand the use cases and the data they are working with in-depth. Rather than building in an ivory tower, they dig into the data with subject matter experts and understand the business objectives and requirements.
Long Live Central ML
Instead of doing away with central ML teams, let’s start a new conversation. How are we making our central ML teams successful? What do customers of central ML hate about it, and how do we fix it? I would love to hear your experience; please reach out in the Arize community!