


In June 2025, Andrej Karpathy introduced Software 3.0: the notion that software development is shifting from programming through code to prompting through natural language.
When building programs, the goal is to define exactly who, what, where, when, and why for your architecture. One reason agents are powerful is because we can use prompts, in natural language, to more easily define these constraints. Prompts define most of these dimensions: when a tool should be called and with what arguments, what the final response should look like, when different reasoning paths should be taken, and which subagents should be involved. Prompts define the core governance of an agent’s logic.
Most high-performing agents today are built on large, detailed system prompts:
| Agent | System Prompt Length |
| Claude (LLM) | 24k tokens / 18k words |
| Claude Code | 8.3k words |
| Cursor | 6.4k words |
| Cline | 8.3k words |
| Perplexity | 1.5k words |
To design stronger agents and LLM applications, detailed and well-structured prompts are essential.
Unlike Anthropic or Perplexity, not everyone has the headcount, time, and skills to perfectly tune these massive prompts for their agents. Instead of manually refining prompts through intuition, can we optimize them automatically using feedback from real application traces? Can detailed prompts be iteratively generated based on prior versions, improving over time?
We introduced Prompt Learning on July 18, 2025 — an approach that builds simple feedback loops for optimizing LLM applications. A week later, DSPy released GEPA, another powerful prompt optimizer built around similar principles.
This post compares Prompt Learning and GEPA, diving into the overall optimization philosophy, usability, and benchmarking.
GEPA + Prompt Learning: Key Similarities
Core Feedback Loop
Prompt Learning and GEPA share the same core philosophy – applying a RL style optimization framework to Prompts. Here’s the core loop for both:
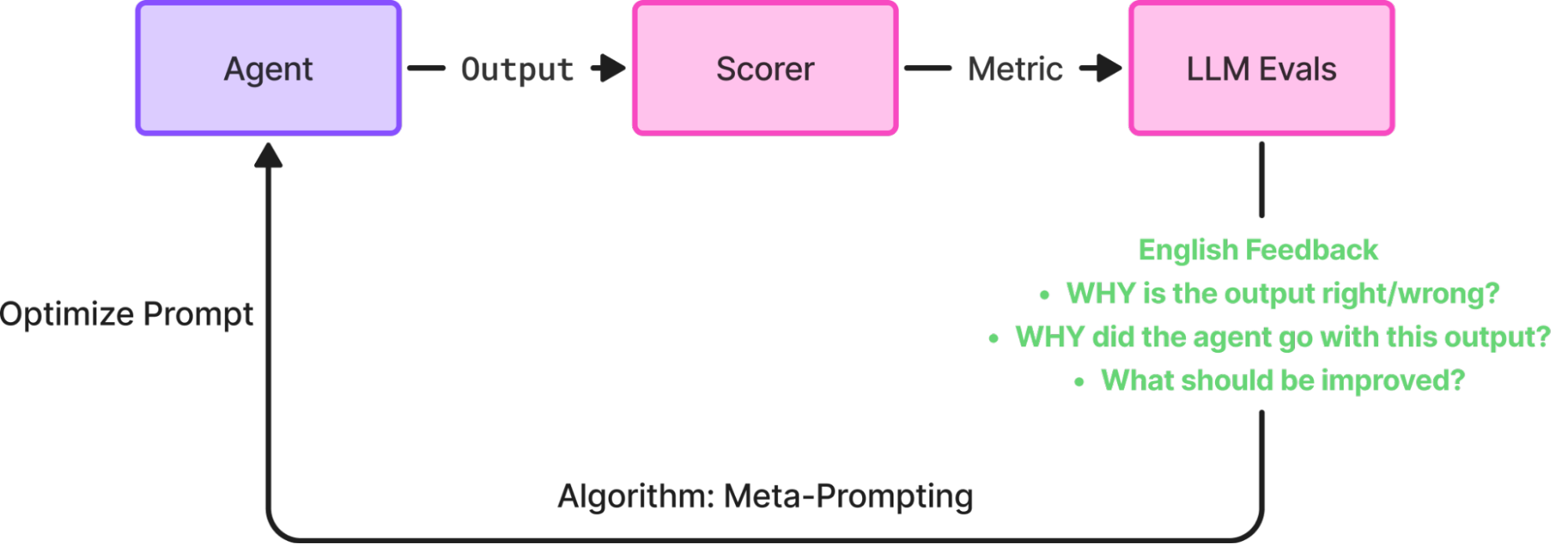
Each optimization loop follows the following steps:
- Run your application with your current prompts. Generate outputs/traces based on their execution.
- Evaluate Results. Generate scalar metrics and/or natural language feedback on those outputs/traces, measuring the success of the application.
- Optimize Prompt: Use feedback to generate an improved prompt
- Iterate: Repeat until performance meets your criteria
The optimization step uses meta-prompting to generate new prompts. Meta-prompting is the simple action of asking an LLM to improve your prompt. In both prompt learning and GEPA, meta prompt looks something like this:

Note:
- This is an example meta prompt for visualization purposes. Prompt Learning and GEPA use more detailed meta prompts.
- We used Claude Code here for visualization as well. If you want to see how we applied Prompt Learning to optimize coding agents like Claude Code, check out the Prompt Learning repo or our other blog posts.
Trace Level Reflection
Both Prompt Learning and GEPA support the idea of trace level reflection – or allowing the meta prompt LLM to reflect upon the outputs/trajectory taken by the application in order to improve it.
LLM tracing records the paths taken by requests as they propagate through multiple steps or components of an LLM application. For example, when a user interacts with an LLM application, tracing can capture the sequence of operations, such as document retrieval, embedding generation, language model invocation, and response generation to provide a detailed timeline of the request’s execution.
Traces can serve as valuable context for optimization. It helps the meta prompt see all the steps taken to reach the final output, and optimize prompts with the full scope of your programs.
Prompt Learning is developed by Arize AI, who has built one of the most popular trace generators for LLM applications today (see openinference, open source tracing library). It is used heavily in Phoenix (developed by Arize), an open source observability and evals platform with over 7k stars on Github. Therefore, when using Prompt Learning, you can natively generate traces and plumb those through the optimization.
Since GEPA requires you to define your entire application in DSPy format, it natively generates traces from there. We explore this more deeply below (see: “Prompt Learning does not lock you into DSPy to optimize your application“).
GEPA + Prompt Learning: Key Differences
Eval Engineering vs Programmatic Features
GEPA adds a few clever engineering mechanisms on top of prompt‐feedback loops. Its evolutionary optimization framework generates and tests many small prompt variations, letting better ones naturally rise to the top. The Pareto-based candidate selection keeps a diverse set of promising prompts instead of converging too quickly on a single style, which helps avoid getting stuck in narrow failure modes. And the merge step can combine strong components from different candidates, letting GEPA reuse partial successes rather than treating each prompt as a monolithic unit.
At Arize, we believe the power of these feedback loops lies much more in your feedback, rather than these programmatic features. Engineering evals that deliver higher dimensional information content to the meta prompt stage, we believe, correlates more strongly with the effectiveness of your prompt optimization.
Something else we believe in is the customization of the meta prompt itself. While GEPA recommends using the base meta prompt in most cases, we believe heavily in the value of customizing your meta prompt to your case.
This will be explored in depth in the benchmarks section.
No-Code Optimization
Arize has the option of running Prompt Learning through the Arize AX platform, no-code.
See prompt optimization through UI here.
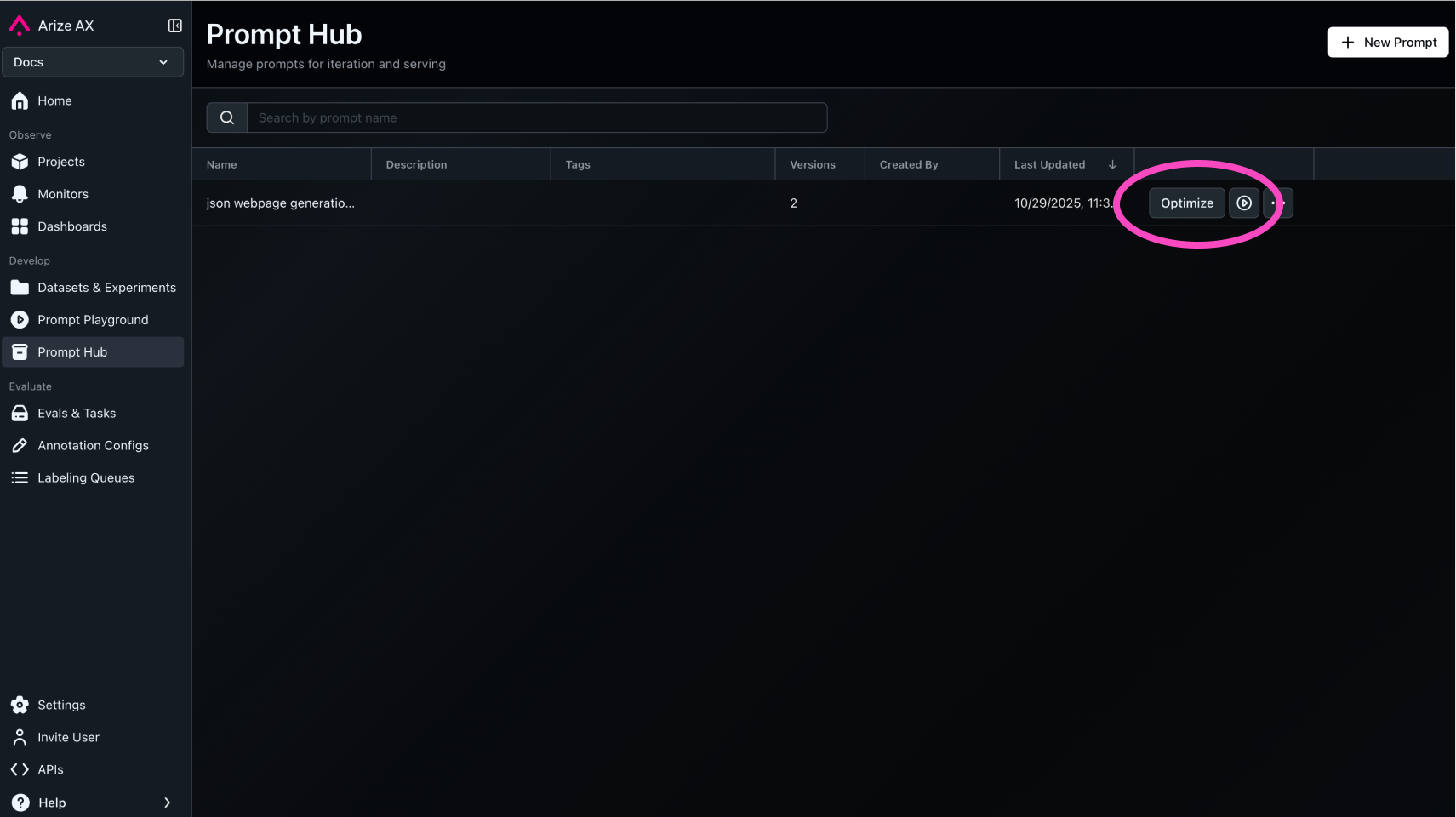
Store Versions in the Prompt Hub
As you optimize prompts, versions will be stored in the Prompt Hub.
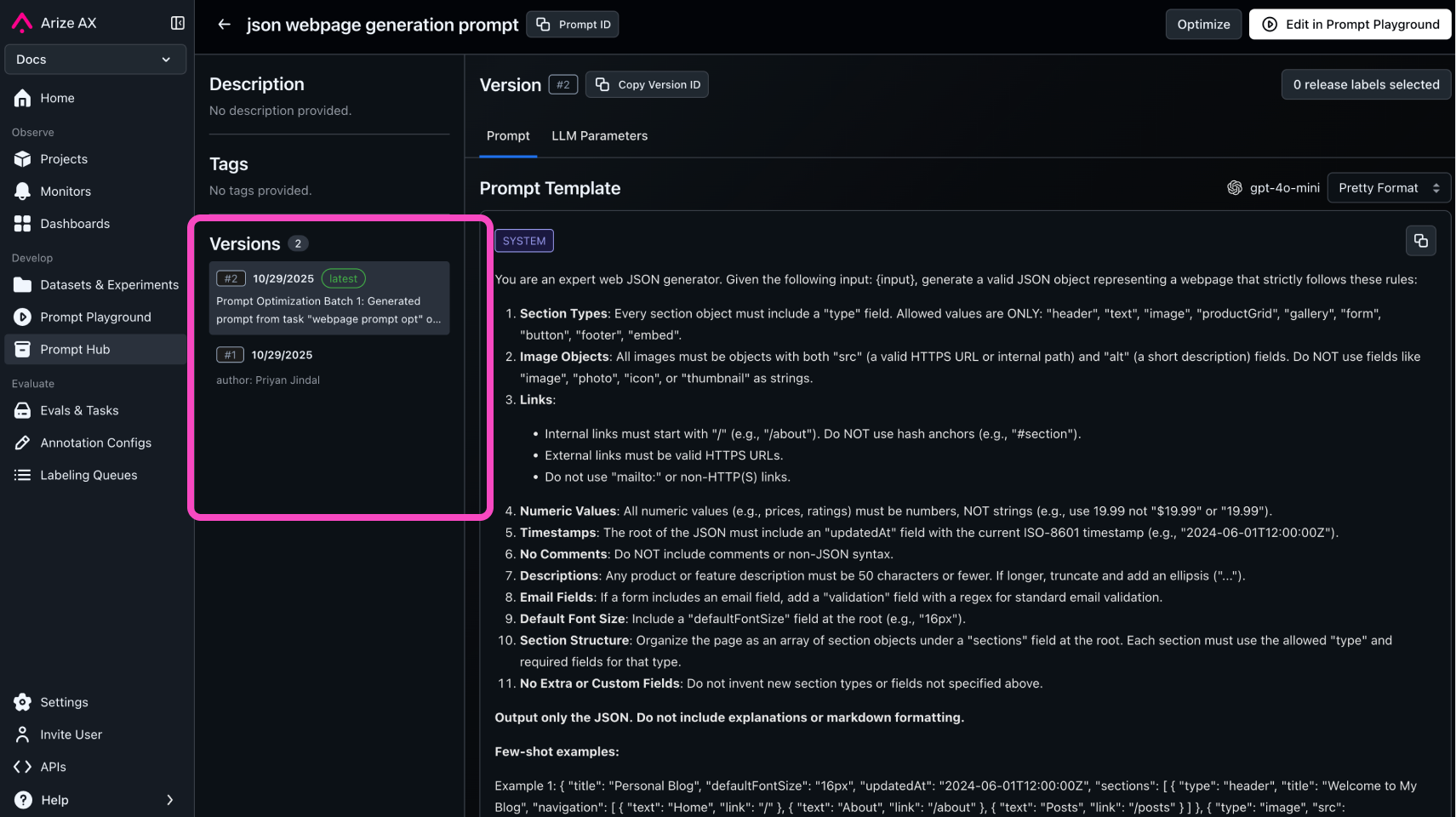
This allows you to store and visualize your prompt updates. You can also load these prompts into the Prompt Playground, which allows you to experiment with your new prompts.
Prompt Learning does not lock you into DSPy to optimize your application
GEPA’s trace-level optimization requires your entire application — LLM calls, tools, retrieval steps, and control flow—to be expressed inside the DSPy abstraction. This is necessary because GEPA relies on DSPy-generated execution traces to drive its optimization process.
Prompt Learning’s trace level optimization is vendor agnostic. It doesn’t require you to rewrite or restructure your system around DSPy. Whether your app is built with LangChain, CrewAI, Mastra, AutoGen, or your own custom framework, you can simply instrument it with our lightweight tracing libraries, export the traces, and feed them directly into the meta-prompt. You get the benefits of trace-aware optimization without committing to any specific framework or architecture.
Start exploring your traces in Arize AX here.
Benchmarking
Here’s how we ran these benchmarks.
In order to compare Prompt Learning and GEPA in terms of their optimization success, we decided to run Prompt Learning on the same benchmarks published in the GEPA paper. The four benchmarks are:
- HotpotQA: Tests multi-hop question answering by requiring models to retrieve and reason across multiple Wikipedia articles to answer complex questions.
- HoVer: Evaluates claim verification accuracy by asking models to determine whether a claim is supported, refuted, or lacks evidence based on retrieved documents.
- PUPA: Measures a model’s ability to rewrite user queries to remove personally identifiable information while preserving task intent.
- IFBench: Assesses how well a model follows natural-language instructions and adheres to explicit task constraints.

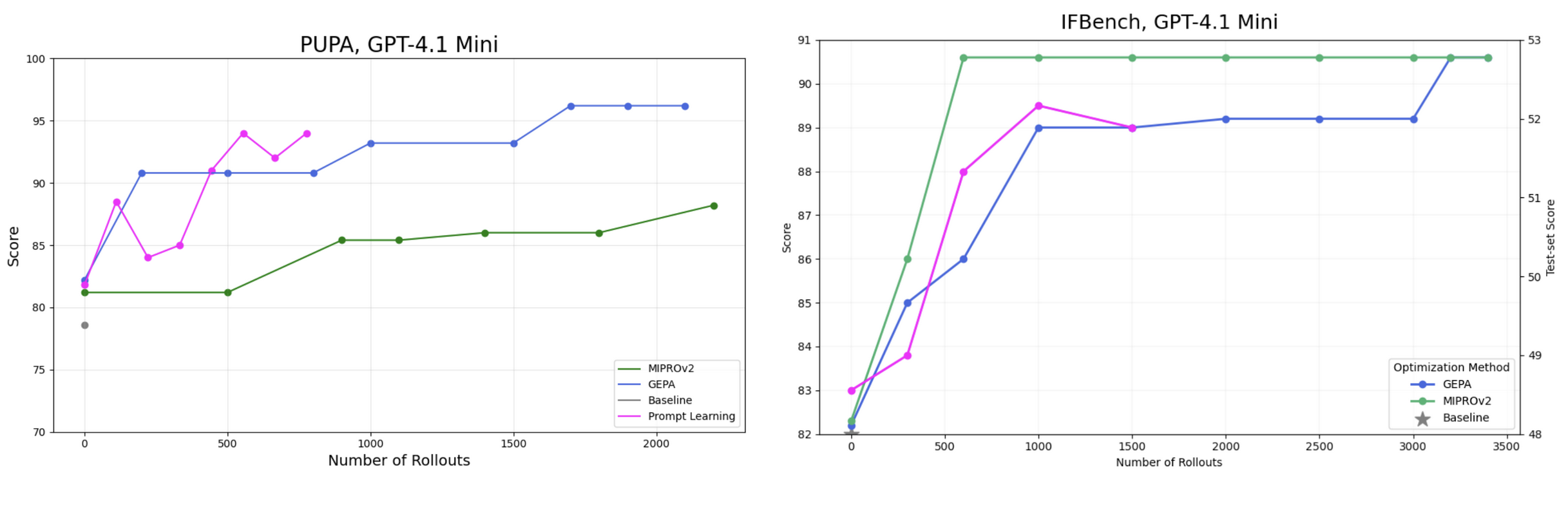
Note that even in the cases where Prompt Learning underperforms GEPA or MIPRO, it’s only by 2%.
Despite using the same core feedback loop, Prompt Learning is able to achieve similar or better results, with far less rollouts. With all the advanced optimization features GEPA employs, one would expect it to outperform Prompt Learning.
Prompt Learning is able to achieve similar accuracy results in significantly less rollouts due to eval and meta prompt engineering. With crafted evals that generate informative feedback, and meta prompts equipped to use that feedback, the same feedback loops that GEPA uses become much stronger.
Let’s take a look at the eval prompt we used for the HoVer benchmark.
You are evaluating a **multi-hop claim verification system** designed for the HoVer dataset.
The system determines whether a factual claim is **SUPPORTED**, **REFUTED**, or **NOT ENOUGH INFO** based on evidence retrieved from Wikipedia.
=====================
🟩 INPUT CLAIM
{claim}
=====================
🟦 STEP 1 — FIRST QUERY & PASSAGES
Query #1:
{query_1}
Retrieved Passages (Hop 1):
{passages_1}
Summary #1 (based on the claim and the first set of passages):
{summary_1}
=====================
🟪 STEP 2 — SECOND QUERY & PASSAGES
Query #2:
{query_2}
Retrieved Passages (Hop 2):
{passages_2}
Summary #2 (based on the claim, previous summaries, and passages):
{summary_2}
=====================
🟫 STEP 3 — THIRD QUERY & PASSAGES
Query #3:
{query_3}
Retrieved Passages (Hop 3):
{passages_3}
Summary #3 (based on the claim, previous summaries, and passages):
{summary_3}
=====================
🟨 FINAL VERDICT
{final_answer}
=====================
🟥 GROUND TRUTH
Ground Truth Wikipedia titles: {ground_truth_wikipedia_titles}
Ground Truth Label (SUPPORTED / NOT_SUPPORTED / NOT_ENOUGH_INFO): {ground_truth_label}
Correctness of the final verdict: {correctness}
=====================
🧠 EVALUATION TASK
Your task is to analyze the **entire reasoning and retrieval chain** to assess the reasoning quality, and faithfulness of the model’s decision.
Provide **structured, diagnostic feedback** that helps improve the system’s prompts and reasoning.
Please:
1. **Assess Correctness**
- Does the final answer (SUPPORTED / NOT_SUPPORTED / NOT_ENOUGH_INFO) match the ground truth label?
- Were the correct supporting documents retrieved and used?
2. **Evaluate Reasoning Quality**
- Did the model logically connect the retrieved evidence across all hops?
- Did the summaries faithfully reflect the passages and support the correct verdict?
3. **Identify Failure Points**
- If the system is incorrect or uncertain, determine *which stage* caused the issue:
- **Query Generation:** missing entities, ambiguous phrasing, irrelevant focus
- **Retrieval:** lack of recall or precision (even though retrieval itself is static)
- **Summarization:** omitted critical facts, introduced hallucinations, or distorted relationships
- **Final Answer Generation:** misinterpreted summaries, ignored key evidence, or over/under-stated confidence
4. **Propose Actionable Improvements**
- Provide concise, constructive suggestions for each component to improve future performance.
- Focus especially on improving query precision/recall and reasoning faithfulness across hops.
=====================
🧾 OUTPUT FORMAT
Return your evaluation strictly in this JSON-like format (no markdown, no extra text):
"explanation": "<a detailed, structured analysis of why the system was correct or incorrect, highlighting reasoning quality and factual grounding>",
"suggestions": "<specific, actionable improvement ideas for each component—query generation, retrieval, summaries, and verdict synthesis>"
Instead of a single correctness label, this evaluator prompt asks a teacher model to inspect every hop of the HoVer pipeline: queries, retrieved passages, summaries, and the final verdict. The evaluation output isn’t just “right or wrong” — it decomposes errors by component (query, retrieval, summarization, verdict), talks about missing or spurious evidence, and proposes concrete fixes for each stage. That gives us a high-dimensional feedback signal we can feed into a meta-optimizer, so we’re not just tuning prompts based on a scalar accuracy score, but on a rich description of how the reasoning chain failed and what to change next.
Conclusion
Prompt Learning and GEPA are built on the same underlying idea: prompts can be optimized through iterative feedback loops, much like parameters in a traditional machine learning pipeline. Both frameworks leverage meta-prompting and trace-level reflection to close the loop between real application behavior and prompt updates. But they take different positions on what ultimately drives meaningful improvement.
GEPA focuses on programmatic optimization strategies—evolutionary search, Pareto filtering, and candidate merging—to explore prompt space efficiently. Prompt Learning instead treats prompt optimization as an evaluation-engineering problem, emphasizing high-quality feedback signals and meta-prompts tailored to the application. The benchmarks suggest that richer evaluations and more expressive meta-prompts can materially strengthen the same feedback loop GEPA relies on, even without additional search algorithms or large rollout budgets.
Prompt Learning’s framework-agnostic design also makes it easier to apply in real production systems, where teams rarely have the freedom to rewrite entire applications inside a single abstraction layer. By instrumenting existing code with lightweight tracing and feeding those traces directly into the optimization process, teams can adopt prompt feedback loops without restructuring their architecture. For teams that prefer visual or collaborative workflows, Prompt Learning also supports a no-code optimization interface and provides tooling such as the Prompt Hub and Prompt Playground to store versioned prompt iterations and interactively test changes.
Across HotpotQA, HoVer, PUPA, and IFBench, Prompt Learning performs comparably to or better than GEPA with far fewer rollouts. This reinforces a broader point: as LLM applications become more complex, the most impactful optimizations will come from the quality of evaluations and the specificity of the meta-prompt—how much actionable information we can give the optimizer—not only from algorithmic search procedures.
As LLM systems continue to scale, we expect prompt optimization to look less like manual prompt crafting and more like a principled process driven by trace data, structured evaluations, and tailored meta-prompts. Prompt Learning aims to make that workflow accessible to any team, regardless of headcount or framework choice.
Summary: Table
| Aspect | Prompt Learning | GEPA |
| Core approach | Feedback loops | Feedback loops |
| What drives improvement | High-quality evals + meta-prompts | Algorithmic search (evolution, Pareto filtering, merging) |
| Rollouts needed | Less than GEPA, less than RL | Less than RL |
| Framework dependence | Framework-agnostic (just add tracing) |
Requires DSPy framework for trace level optimization |
| Ideal for | Real-world production systems | Research-style controlled pipelines |
| Big takeaway | Eval-driven optimization, framework agnostic, no code options, and more suited for built-out production systems | Advanced algorithmic features for research or development projects |