



Co-Authored by Aparna Dhinakaran, Co-founder & Chief Product Officer & Kyle Gallatin, Technical Lead Manager of ML Infrastructure @ Handshake.
Handshake is the largest early-career network, specializing in connecting students and new grads with employers and career centers. It’s also an engineering powerhouse and innovator in applying AI to its product and features. Given constantly evolving model capabilities and user expectations, the product and engineering team at Handshake needed a way to ship LLM features fast without sacrificing reliability, safety, or cost control. To achieve that goal, Handshake developed an opinionated orchestration layer that gives product and engineering a consistent path to production and an integration with Arize AX for observability and evals to keep quality high.
Handshake: The Business Context
Handshake operates a three-sided marketplace connecting schools, employers, and students/alumni. That multiplicity of interactions creates many touchpoints where AI improves matching, messaging, and categorization.
Giving Teams a Fast Lane: A Simple, Central Way To Launch LLM Use Cases
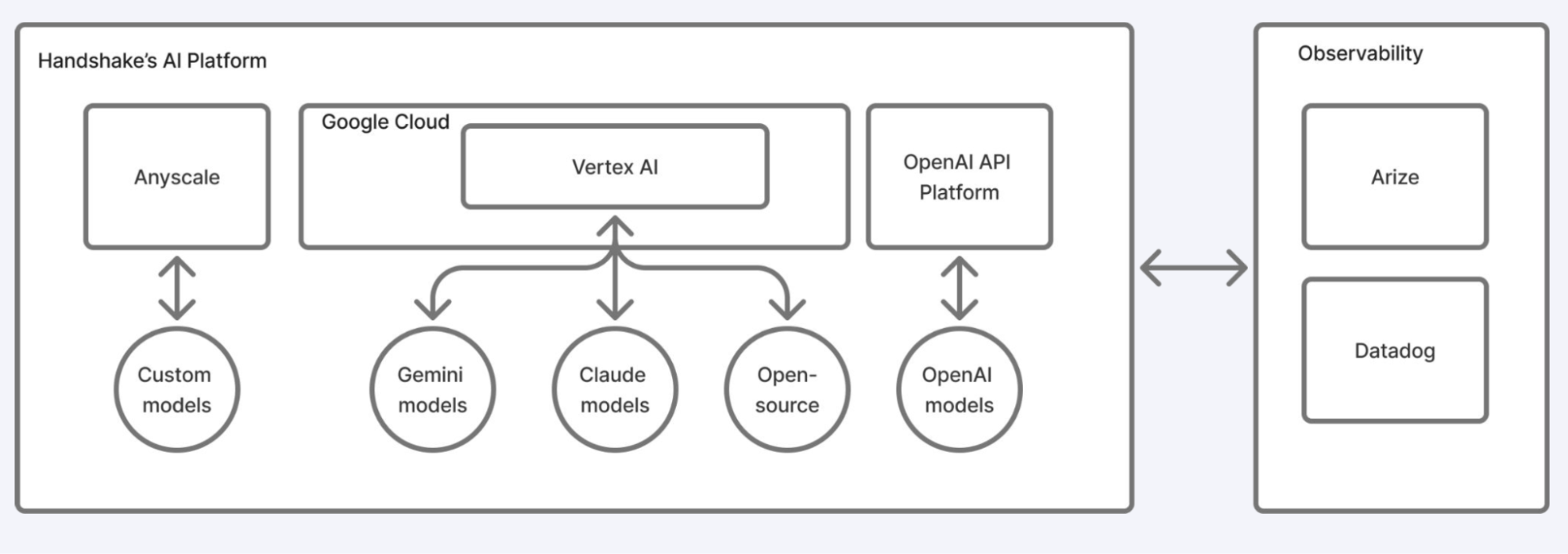
Handshake runs on Google Cloud, historically combining a Ruby monolith with focused Go microservices. On the AI side, the team relies on Vertex AI (Gemini and Anthropic via Vertex) alongside the OpenAI Platform, with Anyscale for managed Ray and custom models.
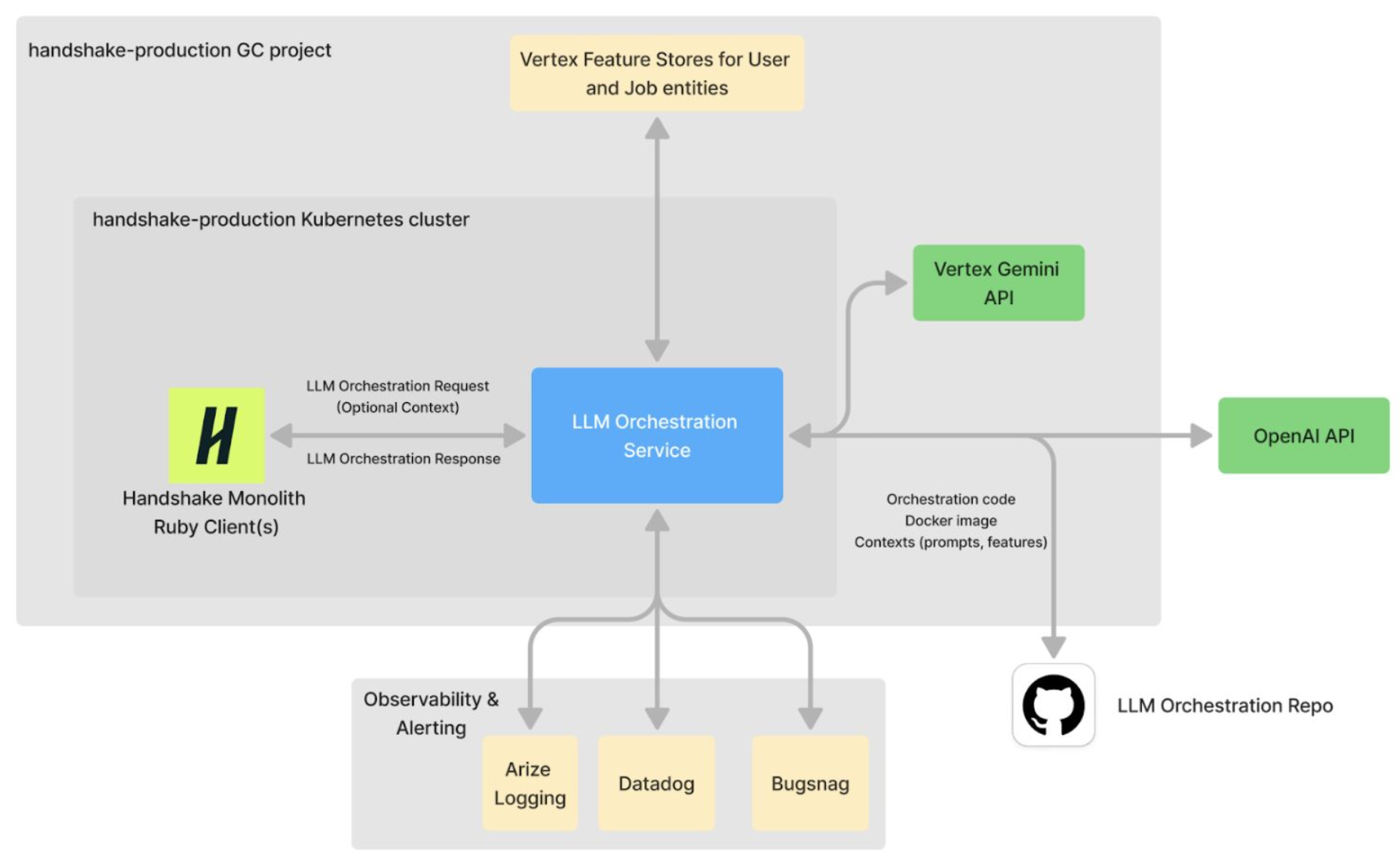
To help provide product and engineering teams with a single, sanctioned entry point to launch LLM-powered features quickly — one that “just works,” routes to approved providers, and is already integrated with observability tools like Arize AX – the team developed a microservice called LLM Orca. Orca is not a generic chat gateway; rather, it’s a deliberately scoped service for stateless LLM calls with structured outputs, using Handshake entity IDs to fetch context when needed. Orca’s goal is simple but powerful: remain robust to rapid shifts in LLM research and development.
The user experience of LLM Orca is designed to be easy for a set of LLM use cases. Arize AX and Datadog integrations are built in, so every call is traced for evaluation and monitoring.
Evaluation From Day One
“We started thinking about evals from the moment we considered a use case: define the success criteria, build a golden dataset, do offline testing and prompt iteration, run pre-launch validation, then launch with production monitoring—and re-test every new prompt or model to prove it’s as good or better.” – Kyle Gallatin, Technical Lead Manager of ML Infrastructure at Handshake
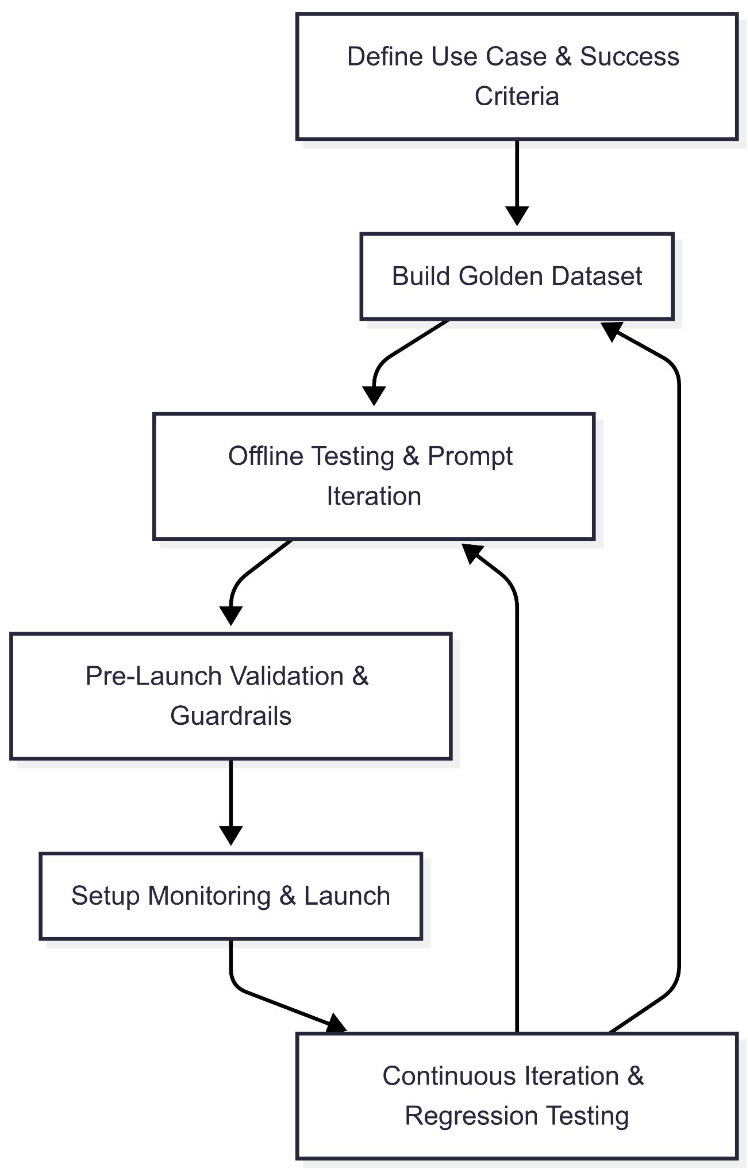
Because LLM Orca is 100% traced to Arize, teams can break down cost, automate LLM-as-a-judge, export traces, and run prompt-engineering evals with real data—starting with a golden dataset and pre-launch validation, then production monitoring and continuous iteration.
Business Impact
Since launching Orca, the team has shipped over a dozen LLM-powered features – with Arize AX integrated for tracing and evals throughout. These include:
- AI-generated first-contact messages for recruiters, with explanations or rationales surfaced where appropriate.
- Job & content tagging to power collections and cold-start recommendations—an ideal fit for structured outputs.
- Employer criteria extraction from descriptions into Handshake’s taxonomy to improve search and matching.
- Agent patterns for multi-step workflows (e.g., job-search assistants and interview experiences).
With Arize AX integrated throughout, the team gets several benefits.
- Unified QA loop from day one. Product managers and engineers work from the same traces and datasets, catching issues early in pre-launch validation and holding comparable metrics in production.
- Faster, safer iteration. Prompts are evaluated on golden datasets and real traces; LLM-as-judge helps enforce consistency and reduce LLM hallucination risk.
- Operational clarity. With end-to-end tracing to Arize AX, teams see cost and error rates per use case and model provider without extra plumbing.
- Meaningful velocity. The approach enabled 15+ production use cases in the first six months, with a typical path from idea to live measured in one to two weeks and major bugs fixed early.
“Arize AX is where all of the traces go—it’s been fantastic to collect everything in one place for evals and iteration. Having a single point of entry means itʼs easy to trace all our LLM calls and break down cost, automate LLM-as-a-judge workflows, export traces for analysis, and do prompt engineering LLM evals with real data.” – Kyle Gallatin, Technical Lead Manager of ML Infrastructure at Handshake
Conclusion
Scaling GenAI isn’t about the flashiest agent or the longest chain; it’s about shipping valuable use cases quickly and proving they work. Handshake’s path shows how a lightweight orchestration layer can empower product teams to build on their own cadence, while Arize AX provides the evaluation, tracing, and cost insight that keep everything grounded. The result is a repeatable rhythm: launch focused features fast, observe them deeply, and iterate with confidence. That’s how you get from a handful of pilots to 15+ production use cases without sacrificing reliability or accountability.
Want to see what Arize AX can do for your team? Book a demo.