



Understanding Bias in Machine Learning Models

Gabe Barcelos
Founding Engineer
High accuracy doesn’t necessarily mean the model is stable and learning accurately.
If you are an ML practitioner or aspiring data scientist, you have heard of the term Model Bias a lot. Model bias is one of the core concepts of the machine learning and data science foundation. One of the most challenging problems faced by artificial intelligence developers, as well as any organization that uses ML technology, is machine learning bias. Before putting the model into production, it is critical to test for bias. Even if your ML model achieves 100% accuracy on your given dataset, this does not necessarily imply that your model is stable and learning.
In this article, we will cover bias concerning ML modeling, types of biases involved in developing machine learning models, methods to detect biases, and their impact with detailed examples. In addition, we will touch on best practices through which we can avoid biases at various stages of the machine learning pipeline.
What is Model Bias?
Bias is a systematic error from an erroneous assumption in the machine learning algorithm’s modeling. The algorithm tends to systematically learn the wrong signals by not considering all the information contained within the data. Model bias may lead an algorithm to miss the relevant relationship between data inputs (features) and targeted outputs (predictions). In essence, bias arises when an algorithm has insufficient capability in learning the appropriate signal from the dataset. For decades, bias in machine learning has been recognized as a potential concern, but it remains a complex and challenging issue for machine learning researchers and engineers when deploying models into production.
The COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) algorithm, which is utilized in US court systems to estimate the probability that a defendant will be a reoffender, is the most prominent example of AI bias and the negative implications on society. The algorithm predicts twice as many false positives for recidivism for black offenders (45%) than for white offenders (23%), and 77% more likely to peg black offenders as high risk of committing violent crimes in the future while mislabeling white offenders as low risk.
The company that produces this algorithm states that protected class data — in this case, race — isn’t used to determine the COMPAS scores. So how is this ML model producing results that are so clearly biased in its predictions?
Bias can be introduced into the machine learning process and reinforced by model predictions from a variety of sources. At various phases of the model’s development, insufficient data, inconsistent data collecting, and poor data practices can all lead to bias in the model’s decisions. While these biases are typically unintentional, their existence can have a substantial influence on machine learning systems and result in disastrous outcomes — from terrible customer experience and profitability, to missentences and fatal misdiagnoses. If the machine learning pipeline you’re using contains inherent biases, the model will not only learn them but will also exacerbate them. Therefore, identifying, assessing, and addressing any potential biases that may impact the outcome is a crucial requirement when creating a new machine learning model. As machine learning practitioners, it is our responsibility to inspect, monitor, assess, investigate, and evaluate these systems to avoid bias that negatively impacts the effectiveness of the decisions that machines drive.
We will review the whole machine learning pipeline to detect different kinds of biases involved in each phase. We will learn how to identify biases at each phase and how to prevent them using best practices. The standard machine learning project pipeline consists of the following steps:
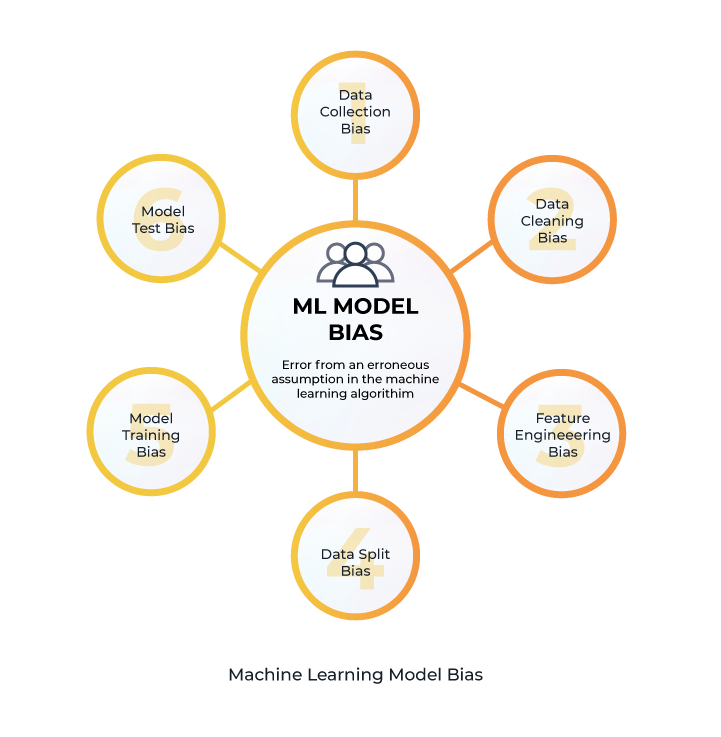
- Data Collection
- Data Pre-processing
- Feature Engineering
- Data Split/Selection
- Model Training
- Model Evaluation
Let’s go through the definitions of each phase in the machine learning pipeline and then look at the techniques for detecting and avoiding biases by using best practices and relevant examples of each process one by one.
1. Data Collection
Data collection is the process of gathering datasets and information from various data sources to train a machine learning model.
What are Data Collection Biases?
Data collection bias is a divergence from the truth in obtaining information from various sources that are based on biased assumptions and prejudice, which can lead to incorrect conclusions. This can often occur when we are not gathering the correct features in the correct context of our specific use case when collecting data from data sources. Or when focused on gathering data points from the whole population that adheres to certain trends or belongs to a specific group.
For example, a machine learning model built to help US hospitals to manage medical care for 200 million patients has given white patients more personalized referrals and recommendations than black patients. Because historical healthcare data was used to train the model, it perpetuated societal prejudices made in the past that resulted in low-cost treatment for black patients and high-cost intensive care for white patients.
How to Avoid Data Collection Biases?
Before actually proceeding with data collection, one should have a solid understanding of the data requirements to avoid bias. The data features extracted from the dataset should be targeted, unambiguous, and project-specific, as this will help you determine whether you will leverage quantitative or qualitative data. Inspecting the data source, examining the dataset, monitoring the timeframe of data collection, and confirming any potential prejudice connected with the dataset as a false notion are some approaches to reduce bias. This adheres to the “Garbage In, Garbage Out” principle — if you push the incorrect input, you will receive incorrect output.
Amazon’s hiring tool is a prime example of data gathering biases. When Amazon launched its AI-based hiring tool a few years ago, the company intended to automate the hunt for top talent that best fits their available job vacancies. When they implemented the tool in production, they discovered that it preferred resumes from male candidates for technical software development roles over resumes from female candidates. When their team looked into the behavior of the hiring system, they discovered that because men have disproportionately higher representation in Amazon’s technical units, the model reflected the implicit gender-bias seen in the training dataset. Once they were able to pinpoint the source of the problem, their ML teams were able to retrain their models on resumes from female candidates to reduce the rate of gender bias.
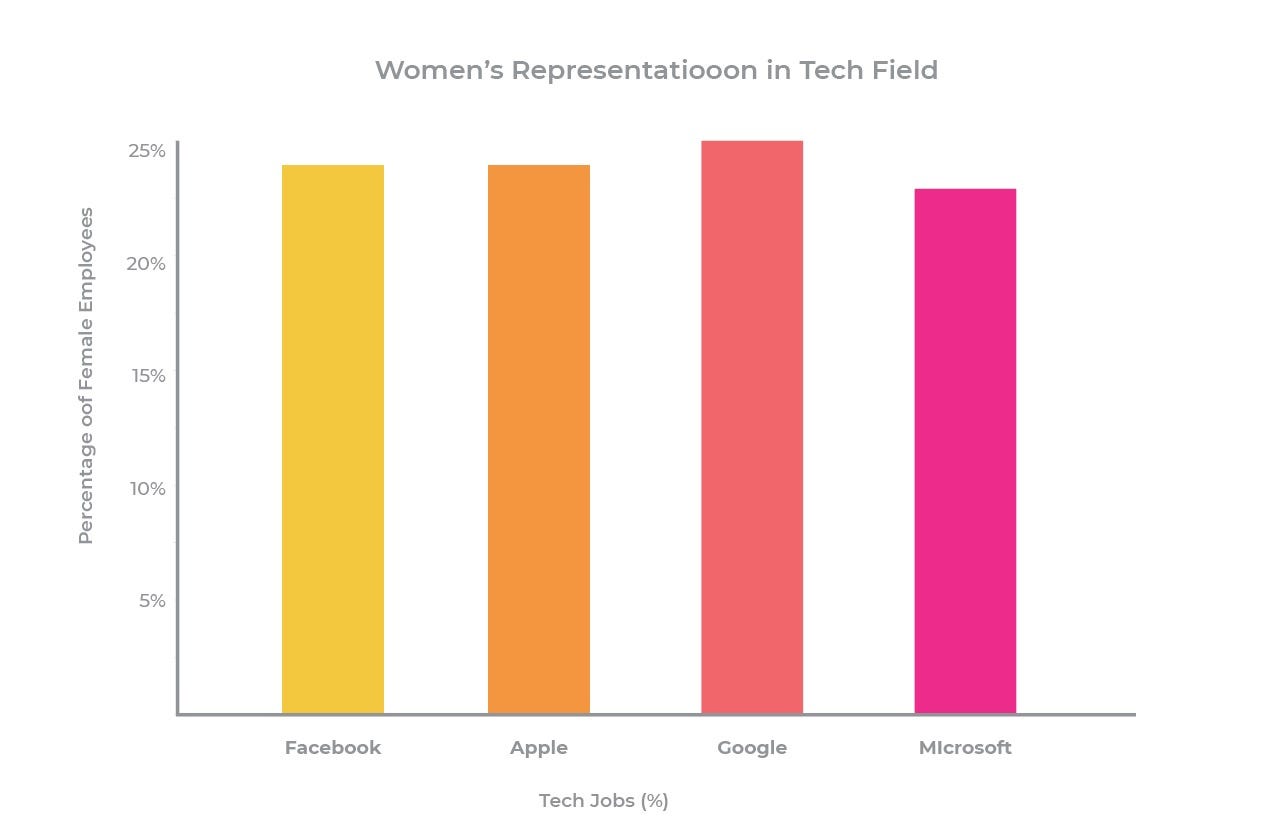
In the diagram, we can see that a huge gender gap exists when it comes to representation of women in tech. This context is vital to consider when gathering data to train models, to ensure ML powered systems aren’t further perpetuating societal or individual biases.
When collecting data, it is critical to have domain expertise to gather meaningful information variables whenever feasible. When acquiring data for a typical machine learning project, it is vital to have a subject-matter expert (SME) with the ML team to assist them in collecting the key features along with their characteristics.
2. Data Pre-processing
Data pre-processing is the act of exploring, examining, revealing, and cleaning data to remove any missing, inaccurate, erroneous, or outlier values, and preparing the information for training ML models. Real-world data is frequently inadequate, inconsistent, and/or missing in specific behaviors or patterns. Pre-processing data is a proven and solid way of overcoming such problems.
What are Data Pre-processing Biases?
Data pre-processing bias happens when we lack an intimate understanding of the raw data gathered from data sources and have inadequate domain expertise regarding the interpretation of specific variables. Biases frequently emerge at this step, and individuals are often unaware of them, inevitably resulting in a biased model in production.
How to avoid Data Pre-processing Biases?
Missing data might lead to bias in the estimation of the model parameters. The lack of actual data decreases statistical power, which is the likelihood that the test would reject the null hypothesis when it is false. These inaccuracies can jeopardize the trials’ accuracy and lead to erroneous findings. To minimize biases at this step, we should select a suitable data imputation technique to replace missing values with new imputed values, and then examine the whole data set alongside the imputed values to determine if the imputed values are reflective of real observed values. Data imputation methods include mean imputation, substitution, hot-deck imputation, cold deck imputation, regression imputation, and stochastic regression imputation. The nature of the dataset and its values influence the selection criteria for proper data imputation methods.
Consider the following scenario: we need to estimate an employee’s salary based on their age, years of experience, and domain. Certain information in the years of experience column is missing to predict salary. When building a machine learning pipeline, we impute the data to train our machine learning model.
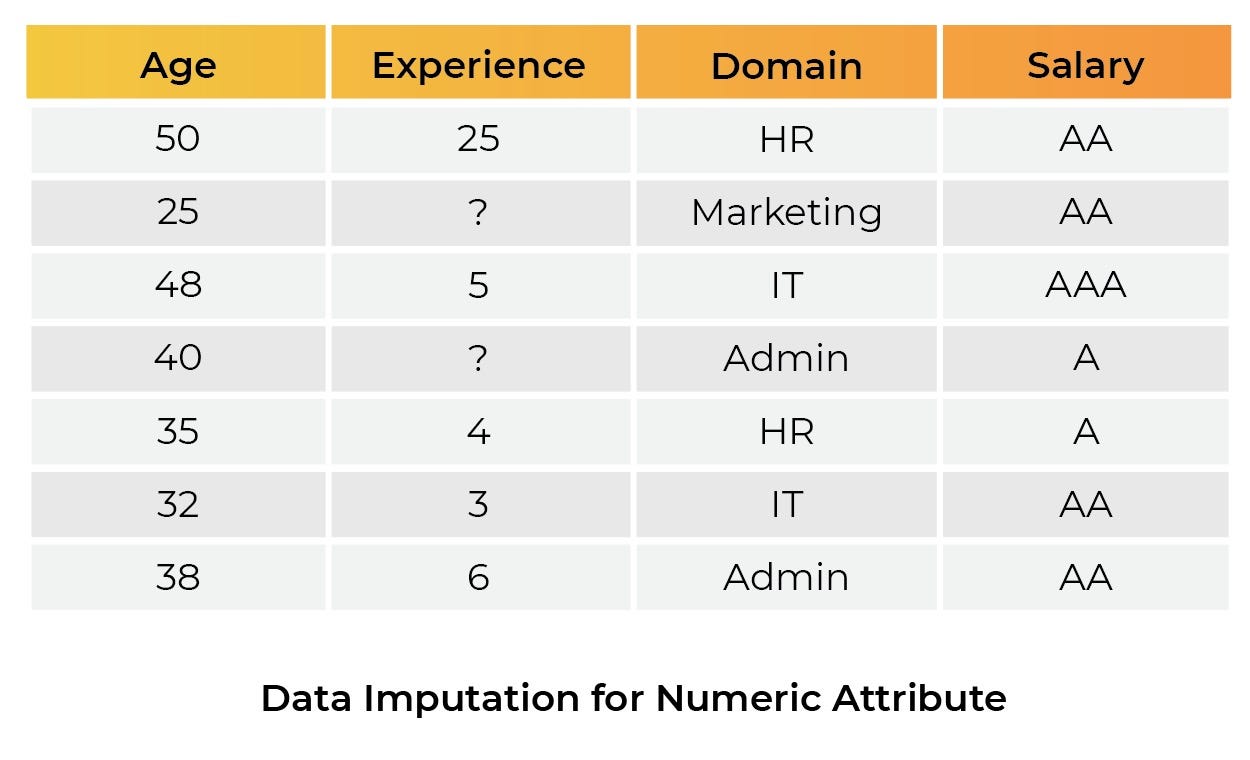
We have a variety of strategies for replacing missing values in data imputation, as mentioned above. Because ‘experience’ is a numerical feature, we utilize the most basic imputation technique — the mean central tendency — to fill in the missing value and train our model using this imputed data. However, during the model validation phase when we monitor the model predictions on real data, we see that the model behavior is inconsistent. Why? Because the imputation technique selected calculates the univariate average of the column with the influence of outlier values of the data (in this case, the person with 25 years experience), resulting in inconsistency bias. It was not a good idea to use mean imputation to replace the missing values in this situation.
To eliminate the biases in the model’s predictions, we must then try another imputation approach. But regardless of the approach, validating a model with offline training/testing datasets can’t adequately capture the realities of an online production environment. So we must continuously monitor model performance throughout the model life cycle to compare performance across environments and catch regressions or drift when they occur.
Also important to consider, when we strive to make our model noise-free or outlier-free for training, we inadvertently remove data that are indicative of a certain group. When these models are put into production certain outliers can reemerge, and our model will fail to anticipate such records because we removed them in the training step! This is why we must perform deeper introspection with ML observability tools before discarding outliers. Observability platforms that help you group and analyze specific cohorts of model predictions can provide better insight into the nature of these outliers and how relevant they are to your model’s purpose.
An example of this sort of bias is the house price prediction model. Assume we have three input columns in the home price prediction dataset: ‘the number of rooms’, ‘area’ and ‘price of the house’. Our goal class is the ‘house price’ that we need to predict. The majority of the values in the ‘area’ column do not exist in the dataset and are marked as ‘null’. If we substitute ‘null’ with ‘0′ in a data cleaning step to fill the area column and then use that dataset for model training, the resulting model will be unstable and biased. Because a 0 square feet home is an impossible input in real life, the model outcomes would be biased and marred with data inconsistency.
3. Feature Engineering
The process of a machine learning pipeline that integrates the input data from the data cleaning step and then transforms the data into model features is known as feature engineering. This phase prepares the dataset so that a model can be trained on how to respond to different features and values.
What are Feature Engineering Biases?
Feature engineering bias arises when a feature or set of features, such as gender, ethnic categories, or social position has a detrimental influence on the overall learning of machine learning models, thereby producing unideal model outcomes or predictions.
How to avoid Feature Engineering Biases?
The most essential thing we need to do to minimize feature bias is to use feature scaling to standardize the range of values of independent variables or features. It is used to normalize data that have different scales to measure the same type of data characteristic in order to reduce bias and inconsistency. Real-world datasets frequently contain characteristics with different magnitudes, ranges, and units. As a result, feature scaling is required in order for machine learning models to understand these characteristics on the same scale.
For example, if we need to predict the time window of vehicle failure, we will have a feature set of vehicle covered distance (in Km), vehicle life (in years), and other numeric features. The most notable scaling elements here are ‘distance’ and ‘vehicle life’, which must be standardized on a single scale. Because the distance covered by a vehicle is in the range of 1-6 digits and vehicle life is in the range of 1-2 digits, when we train the model on this dataset the output will be skewed by the measurements in which the distances were recorded. Which impacts model learning as a whole, and the outcomes will be incorrect.
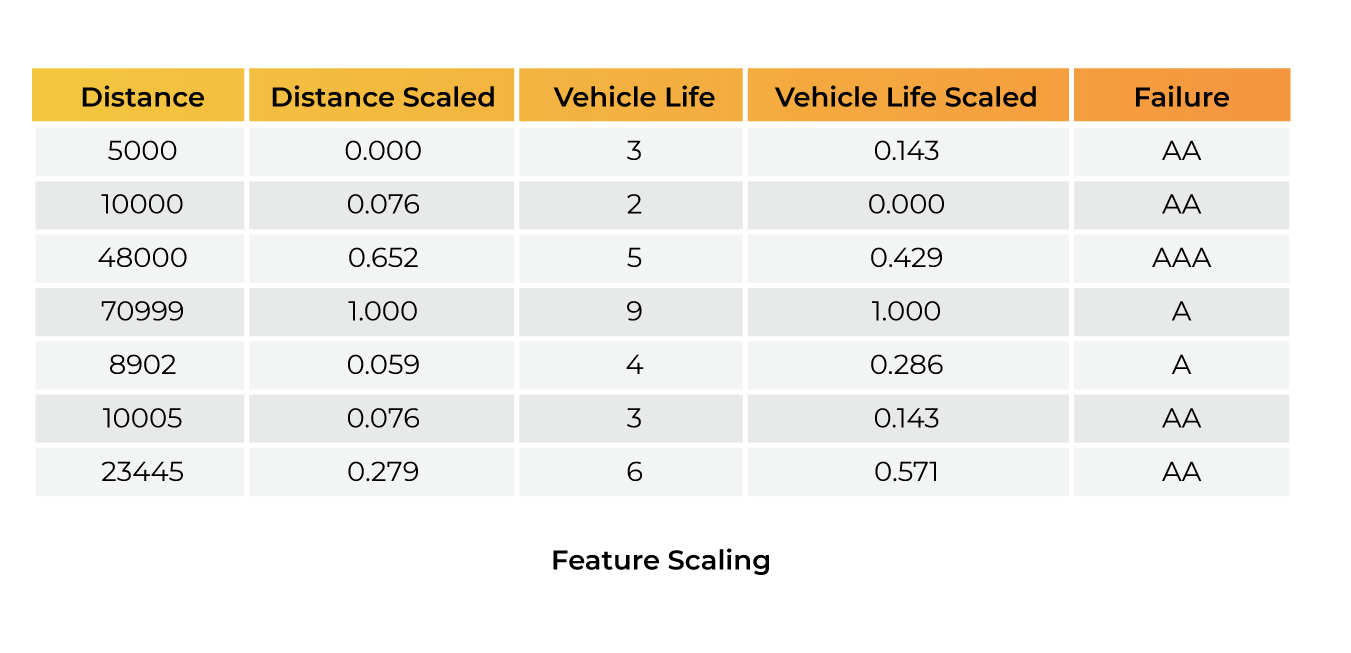
The diagram shows input ranges differ greatly in terms of the gap between the ‘distance’ and ‘vehicle life’ estimates. This is why it is necessary to normalize the data.
Also, to decrease feature bias, you need to account for factors that have a large effect on the model’s outcomes being extremely skewed when deployed to a whole population — such as gender, socioeconomic status, racial characteristics, and regional preferences. For example, if we are training a model to predict heart failure in US adults and the dataset used to train the model is predominantly white males, the final model won’t be properly representative of women or non-white males, whose age-standardized incidence rate of heart failure differ.
We may confront bias factors in the dataset like gender bias, racial prejudice, community bias, category bias, and many more depending on the dataset and use case we are working on.
As a result, it’s critical to analyze feature set values and understand feature importance in a model’s predictions. We must carefully consider the implications of each feature’s inclusion and removal not just at an aggregate level (i.e. accuracy across all adults in the US), but against specific cohorts of predictions (i.e. accuracy by gender, race, geo, etc).
4. Data Split/Selection
The process of deciding which parts of the data should go into the training dataset and which should go into the test dataset is called data selection. The model will be biased if we don’t randomly split the data into both train and test datasets using cross-validation (performing the random folds many times).
What are Data Split/Selection Biases?
Data selection bias occurs when the data used in training is insufficiently large or representative, resulting in a misrepresentation of the real population. When we split the dataset into train and test data, most of the data features that are entered into the training dataset belong to one type of data distribution, while the other data distribution is missing. Some features rows will be missing from the training dataset due to data exclusion. As a consequence, a bias model is created that predicts only the characteristic rows that are present in the dataset.
How to avoid Data Split/Selection Biases?
So, in order to minimize such biases, we must ensure that when we conduct data selection or data sample, we use random sampling. Multiple random samplings are performed so that the model may be trained on various sorts of data distributions present in the training dataset, such as K-Folds Cross-Validation or Stratified Cross-Validation.
Simple random sampling, in which samples are picked only by chance, is one of the most successful and straightforward strategies that researchers employ to minimize sampling bias. This ensures that every individual of the population has an equal chance of being selected as a participant in the training dataset. For example, suppose 500 people in the population are qualified for the job they want. We need to choose 20 of them as research samples for the study and then use random sampling to choose any n=20 individuals from the whole population. K-Folds Cross-Validation is the process of repeating the same random procedure k (any integer number) times.
Stratified random sampling is also commonly used by researchers because it allows them to acquire a sample population that best represents the overall population being researched while also ensuring that each subgroup of interest is represented. We must guarantee that each class/label has an equal distribution (Stratified Cross-Validation) in both the training and testing datasets when constructing a machine learning pipeline to avoid biases in the final model.
Assume that more than 100 people in the population are competent for the job. We need to choose 20 of them as research samples for the study and then use stratified random sampling to choose any n=20 individuals from the whole population, ensuring that each subset of the population comprises equally of men and women (10 men and 10 women). In this manner, the model may learn robustly and offer accurate predictions for all types of data distribution. Assuring that the subgroups picked have the same key features as the entire population.
An example of this sort of bias is the Netflix movie recommendation engine, which is responsible for recommending a movie to its users based on their profile, demographics, viewing history, and interests. The Netflix streaming server receives the majority of its traffic from the United States. If Netflix’s recommendation system focuses primarily on data from US users and recommends a movie to their viewers globally, the results will be incorrect since the data gathered only represent a small portion of the global population.

The above diagram shows that the majority of traffic is coming from the US area, which has a market share of 64.5 percent.
5. Model Training
Model training is a critical component of the machine learning pipeline. At this point, we feed the training dataset into a machine learning model to get it ready for production. When training the model, each algorithm has its structure and principles that must be tweaked with the data.
What are Model Training Biases?
The discrepancy between the trained model’s produced outcomes and the actual results is known as model training bias. Some models, like neural networks, are ideal for huge datasets since they function on millions of data points and provide reasonable accuracy. It memorizes a small dataset and offers high accuracy to the model on training data, but fails to provide excellent results on testing data. For small datasets, regression and tree-based models, for example, are appropriate.
How to avoid Model Training Biases?
To prevent ML algorithmic bias, we must consider important aspects such as the problem statement and desired outcome, the type and amount of data, the computing time available, the number of features and observations in the data, and so on when choosing the right model for our dataset.
When choosing a model, we need to understand what the actual goal is that we are trying to achieve. If the interpretation of the output is the aim, restricted models are preferable since they are easier to understand. It means that you can easily understand how any individual predictor is associated with the response. Examples of restricted models are Linear Regression, Logistic Regression, Decision Trees, and Naive Bayes. If the high accuracy of the model is a major requirement, then flexible models are preferable. Such as Artificial Neural Nets and Deep Learning algorithms.
As a machine learning practitioner, you must realize that while building a model, we must choose the machine learning method that best matches our dataset. Model selection can be done at this phase by shortlisting three to four models and then conducting cross-validation to determine the best one for the job. We should train the final model on the entire dataset once we choose the model and fine-tune the parameters.
For instance, suppose we’re trying to create a Wedding Dress Recognition System for a fashion store. The wedding dress dataset contains more than 5 million pictures of all the wedding fancy attire. Each garment features a wide range of pictures from various perspectives and lighting situations that would be found in a real-world setting. On such a large dataset, standard machine learning techniques such as decision trees, multiple logistic regression, and other tree-based models will not generalize well enough to accurately detect the wedding dress. As a result, the wedding attire is misclassified and the accuracy is low. The neural network, on the other hand, will generalize better if it is trained on a bigger data set. Artificial Neural Networks, for example, require a rather big data collection for optimal performance. When we provide the artificial neural networks the input dataset of wedding attires, they learn all the essential hyperparameters in the most efficient way possible. This will aid the optimization function in minimizing the error loss in identifying the dresses to the greatest extent possible. The trained model will now be more generalized and more accurate than the conventional one in terms of precision.
6. Model Validation
Model validation is the process of assessing a model’s performance on a test or unseen data using performance indicators established prior to model training.
What are Model Evaluation Biases?
When we train our model on training data, we cannot predict the model’s quality by evaluating its performance on the training data alone. Since sensitivity analysis on training data is generally biased — due to the fact that the model learned how to respond to that specific dataset — we need to examine the model’s performance on test data.
For example, if we are working on a fraud detection problem in the banking industry, the majority of transaction instances do not contain fraudulent behavior, therefore the dataset will be heavily biased towards one class of transactions that do not involve fraudulent activity.
As a side effect, when you train your ML model on the training dataset, it will have relatively few data points indicating fraudulent behavior. As a result, the model may provide 90% accuracy but only 50% sensitivity or recall on the testing dataset. When interpreting the findings, most people think that the model is stable and produces reliable results if the overall accuracy is high, however, this is an extremely false assumption. You likely are facing training-prod skew, and you might want to rethink your data sampling techniques to curate a more representative dataset.
How to Avoid Model Evaluation Biases?
At this point, we need to evaluate our model’s performance on test data to ensure that it is not biased outside the training environment. When doing the evaluation, we must consider the performance indicator that was previously established based on the use case. Under certain instances, the model’s sensitivity is more significant than the model’s overall accuracy. We utilize confusion matrix values as our measurements when binary classification is required; in regression models, we use distance formulas such as Euclidean distance and root-mean-square-error (RMSE). As a result, we’ll need to fine-tune the performance metric to provide a fair model evaluation.
The status quo is to layer on model monitoring once a model has been deployed into production — this approach, however, forces you into a defensive position of reacting to performance regressions, data quality issues, and drift after your business is already consuming model predictions. This is where full-stack ML observability platforms come in. These platforms enable you to perform pre-production model validation so you understand how a model performs before deployment.
Aggregate statistics such as accuracy are useful when the aim is to observe the top-level health of your model, allowing you to quickly detect regressions in model predictions. However, when it comes to detecting bias, aggregate statistics can actually mask areas that your models may not be stable and learning the way you intended.
For example, your model predicting the incidence of heart failure in adults may seem stable with an aggregate accuracy rate of 80%. But when you look at the performance of male adults you may uncover that the accuracy for that cohort is 95%, while the accuracy for female adults is only 65%. Without analyzing these cohorts independently, it’s easy to falsely assume that the model performs better than it actually does. It’s therefore critical to incorporate model observability tools that allow you to analyze slices or cohorts of predictions and features of interest prior to the production stage of your ML pipeline, so you can diagnose potential problems or biases against specific cohorts in advance.
Keys to Preventing Bias in ML Model Development:
In machine learning applications, reducing data bias is an intentional and continuous effort. Although it may be sometimes challenging to detect whether your data or model is biased, there are a few things below you can do to assist mitigate or detect bias:
- The AI and ML teams should be well-versed on the underlying data, important features, and any outliers.
- Avoid sensitive groups like gender, socioeconomic position, ethnic traits, regional preferences, and so on if they interfere with the interpretation of the data and model.
- Engage your AI and machine learning team with a subject-matter expert to acquire relevant data variables during the data collection and feature engineering phases.
- Create generic use cases for different sorts of biases and take proactive debiasing measures.
- Update training data on a regular interval to ensure that the ML model can absorb and learn new data patterns.
- Ensure that your model’s training data is not influenced by any prejudice or incorrect assumption.
- Make your training dataset to be the best representative of the whole population, and it should be as diversified as possible.
- Ensure data diversity by gathering data from a variety of sources and integrating it to create a training dataset.
- AI and ML teams should be aware of when to apply which ML algorithm. Select the most appropriate machine learning model for the data at hand.
- The performance of the machine learning model should be monitored and validated on real-life data before it is deployed into a real-time system.
- Conduct bias testing as a part of your machine learning project lifecycle to discover bias at an early stage before it causes real-world system damage.


