Overview
Relevant Kafka messages consist of a model’s input features, its relevant metadata (referred to as tags in the Arize platform), and the predictions.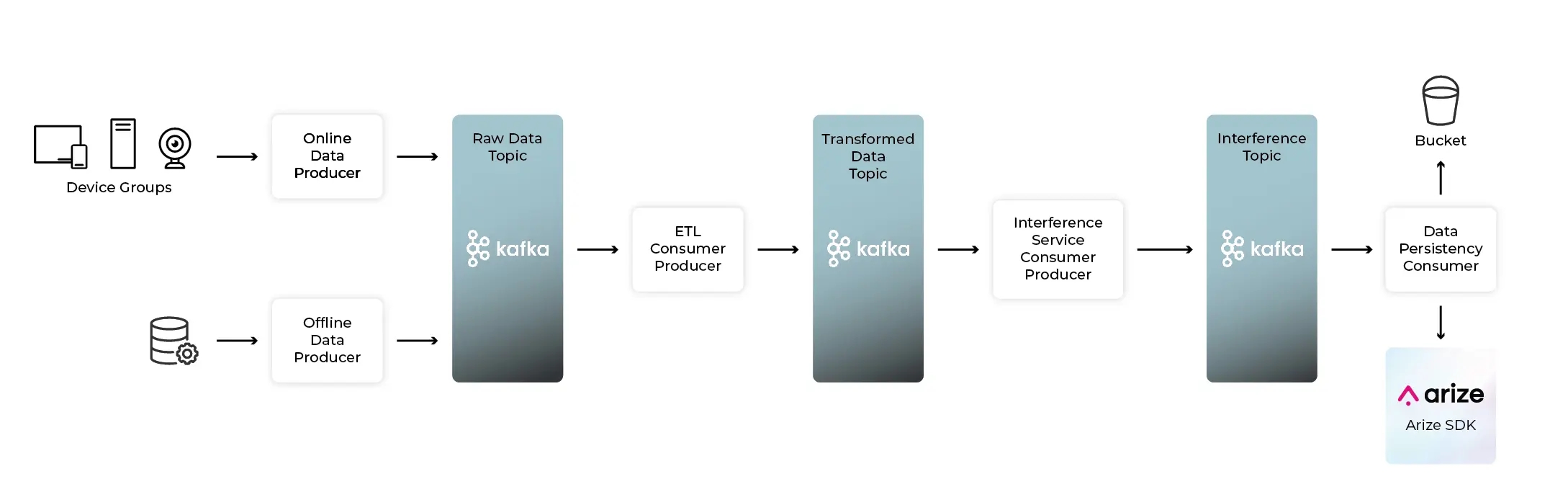
Visualization of Arize fitting into a Kafka Pipeline
Example
In the example below, Arize consumes a microbatch of up to 100,000 events or up to 10 seconds. This is a configuration that can be adjusted based on your use case. Arize consumes these events, deserialize them, and batch them together prior to sending them over the wire into the Arize platform. This micro-batching amortizes any round-trip overhead. Note that the automatic partition offset commits are disabled and manually commit the offsets after data has been persisted at the Arize edge. This ensures no data loss in the case of service disruption in any step of the process. Kafka consumers can be set to consume all partitions on a topic, or for larger clusters can be set to consume specific partitions – allowing for parallelization of the consumer and further increasing throughput for truly large data processing, ensuring data is always ingested in real time and minimizing any potential latency.Questions? Email us at support@arize.com or Slack us in the #arize-support channel