Set up an import job to log inference files to Arize. Users generally find a sweet spot around a few hundred thousand to a million rows in each file, with the total file limit being 1GB.Documentation Index
Fetch the complete documentation index at: https://arize-ax.mintlify.dev/docs/llms.txt
Use this file to discover all available pages before exploring further.
Step 1. Get The Storage Container Name & Prefix
Create a blob storage container and folder (optional) where you would like Arize to pull your model’s inferences.For example you might set up a container named
bucket1 and folder /click-thru-rate/production/v1/ that contains CSV files of your model inferences.In this example, your bucket name is bucket1 and your prefix is click-thru-rate/production/v1/Step 2. Add the Arize Service Principal
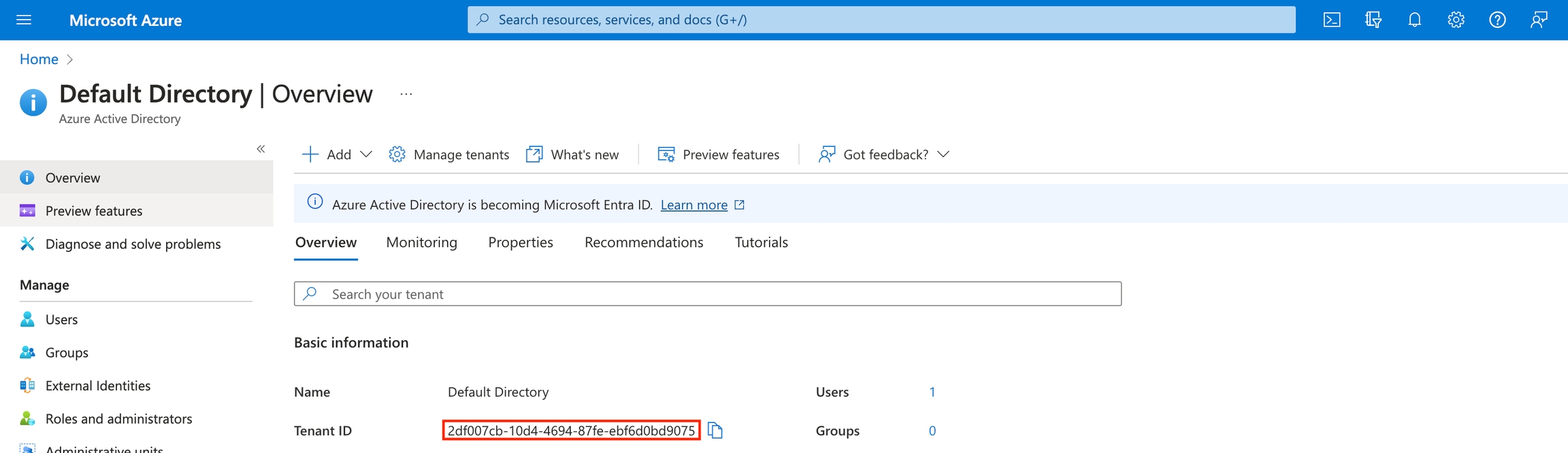
Follow the steps to download the Azure CLI: https://learn.microsoft.com/en-us/cli/azure/install-azure-cli Add the Arize Service Principal by referencing our application id:Step 3. Grant role to the Arize Service Principal
- Azure Portal
- Azure CLI
Find the storage account name that your container is created under, and click “Access Control”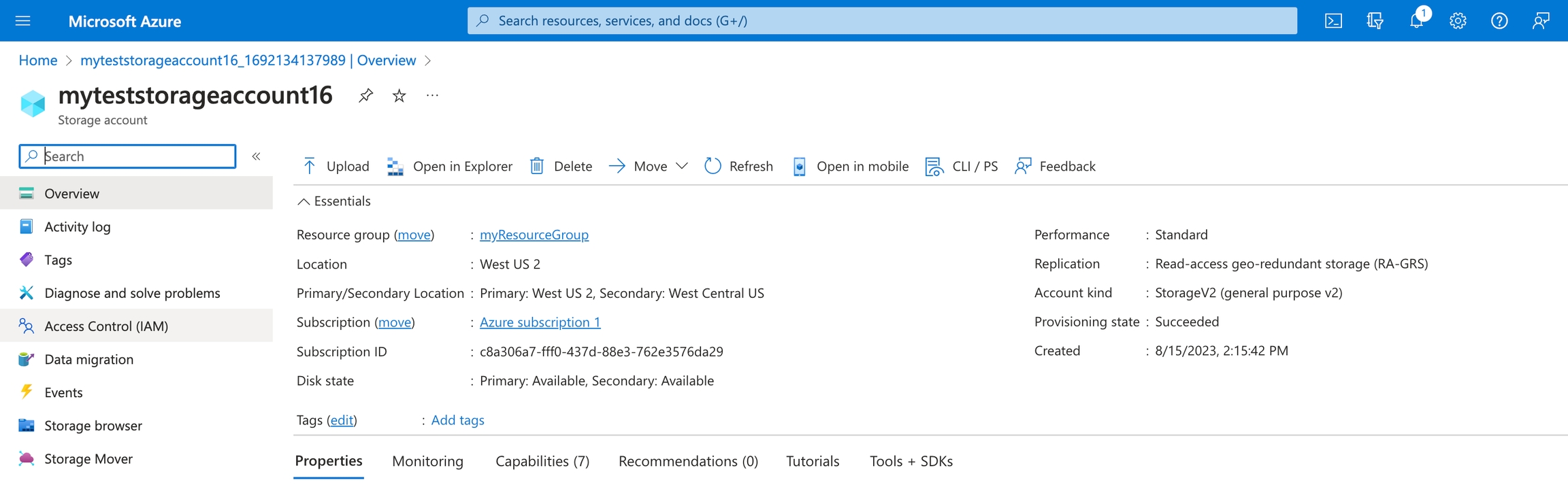 Go to “Role Assignments” and click “Add”
Go to “Role Assignments” and click “Add”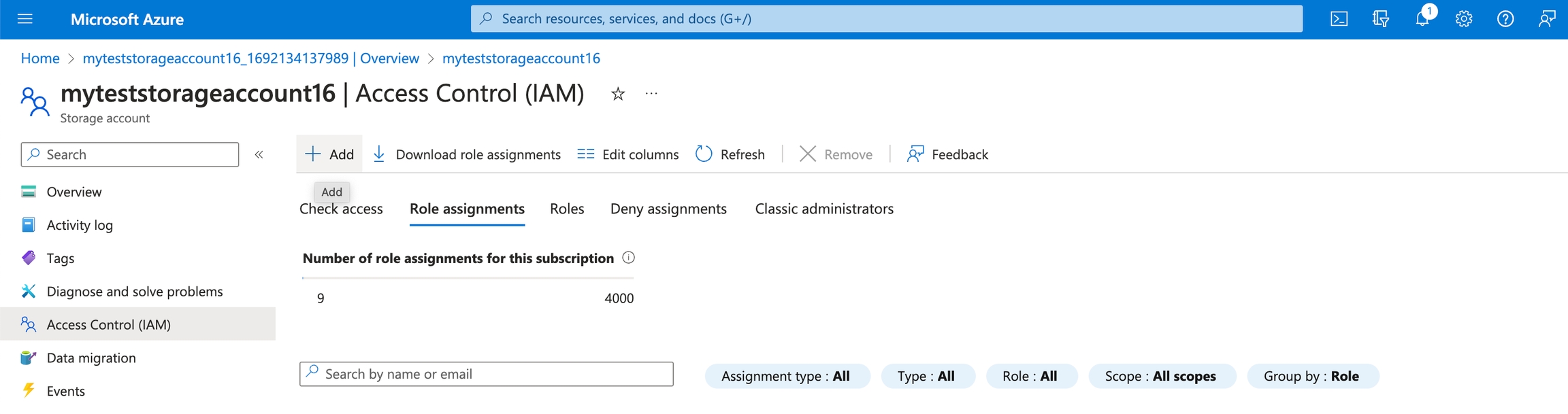 Search for “Storage Blob Data Reader” and click on it
Search for “Storage Blob Data Reader” and click on it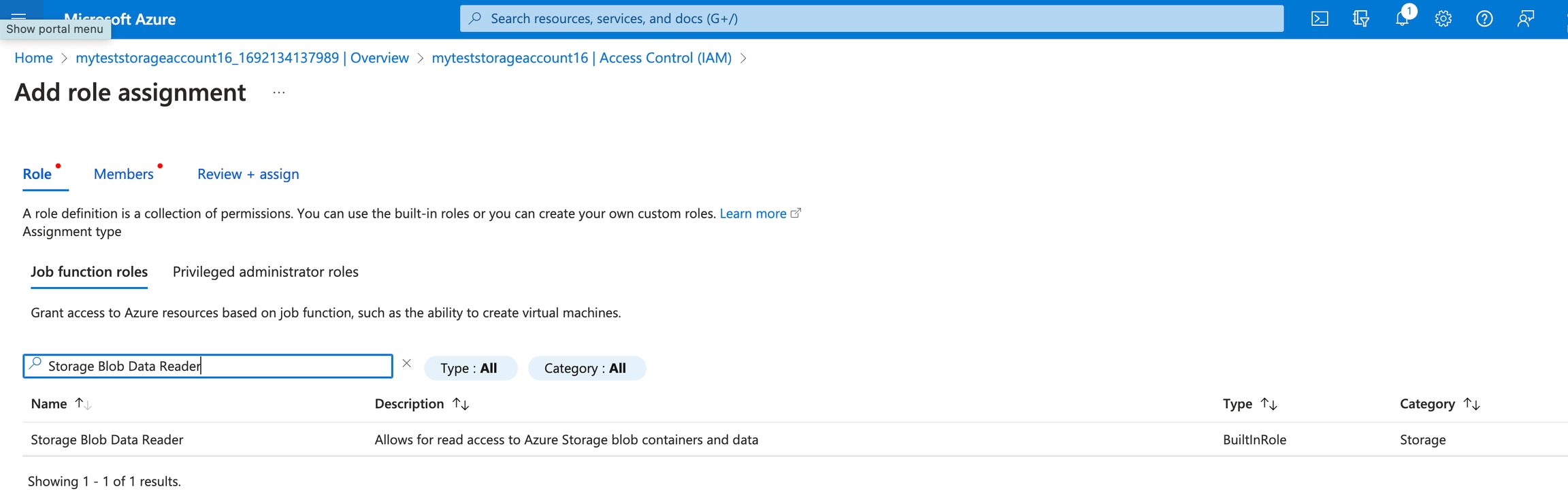 Click “Next” and check “Assign access to: User, group, or service principal”. Click on “Select Members” and search for “Arize”.
Click “Next” and check “Assign access to: User, group, or service principal”. Click on “Select Members” and search for “Arize”.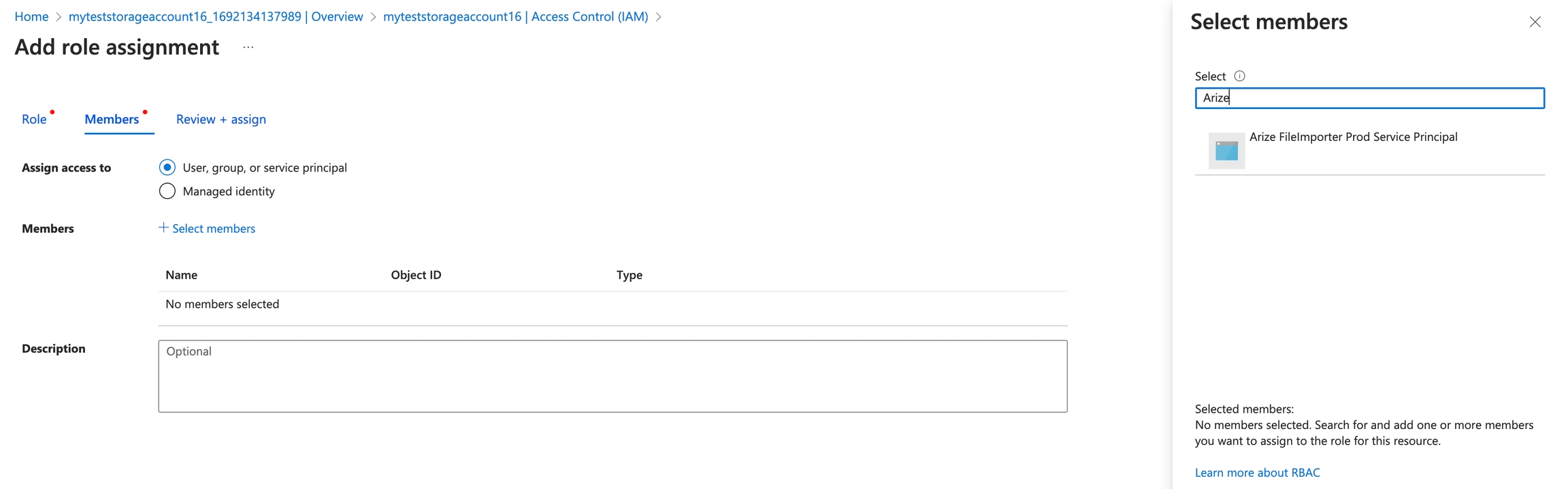 Click on “Review + Assign”
Click on “Review + Assign”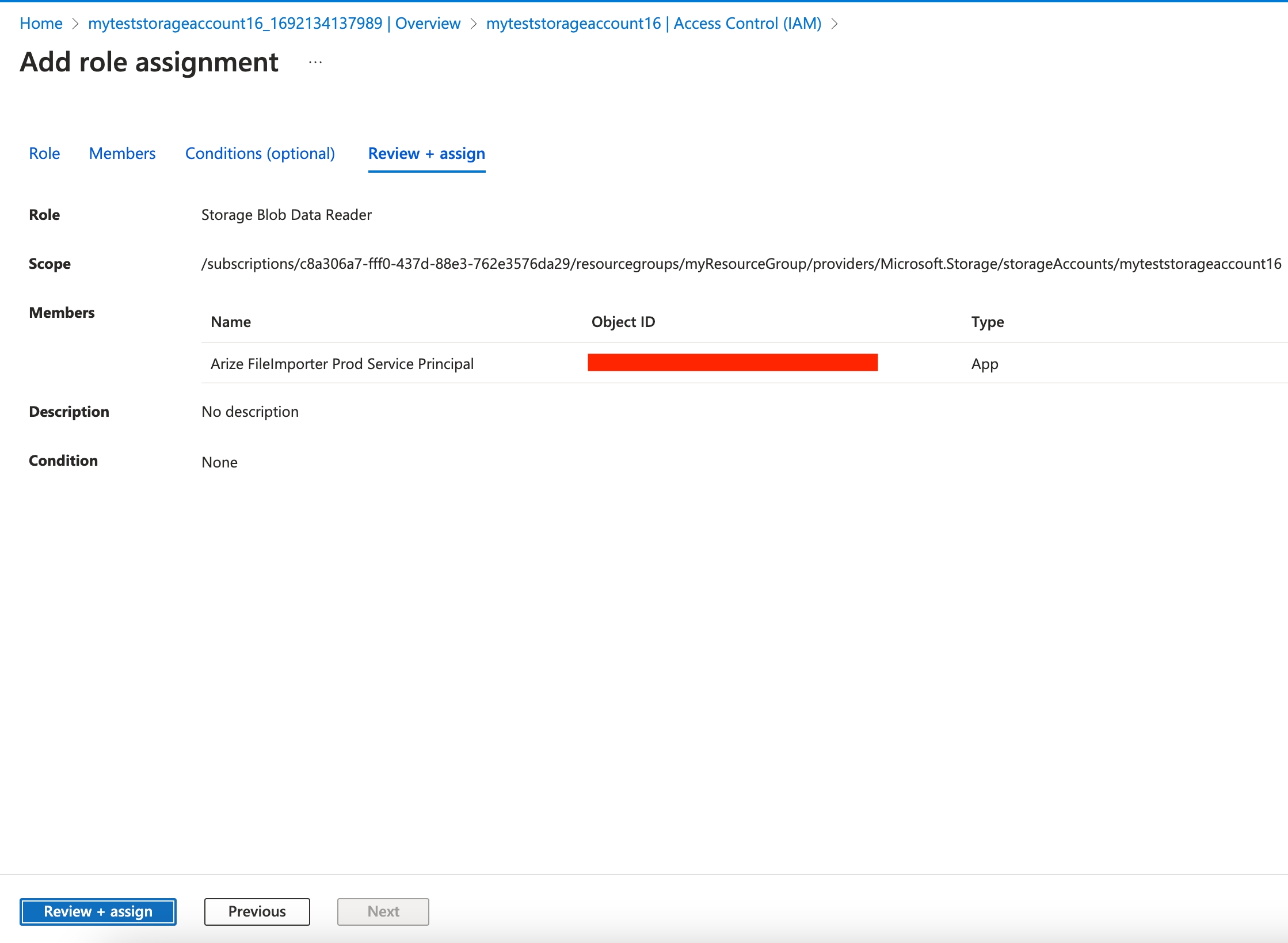 Ensure our Service Principal appears as having the “Storage Blob Data Reader” role
Ensure our Service Principal appears as having the “Storage Blob Data Reader” role
Step 4. Select Azure Storage
Navigate to the ‘Upload Data’ page on the left navigation bar in the Arize platform. From there, select the ‘Azure Blob Storage’ card to begin a new file import job.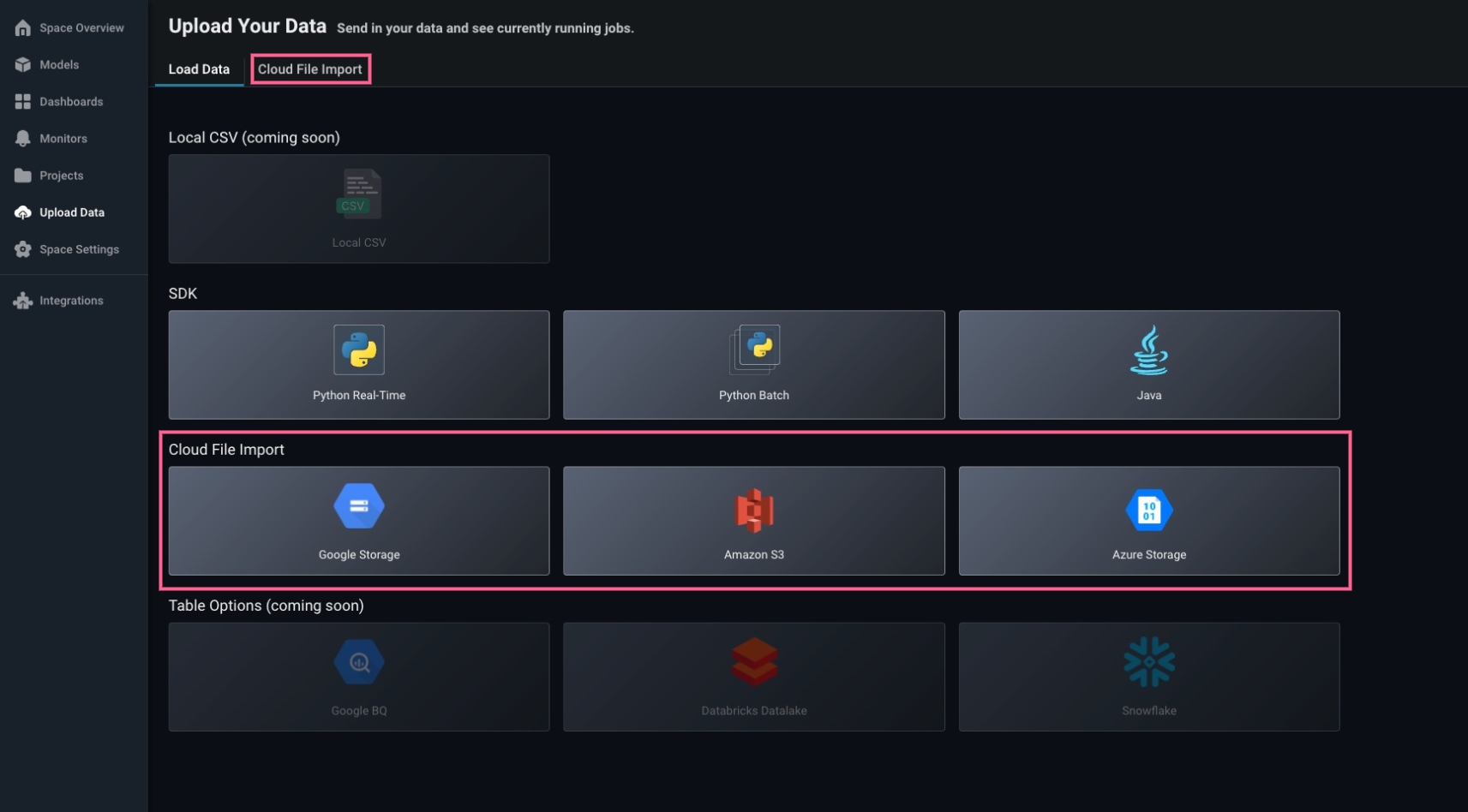
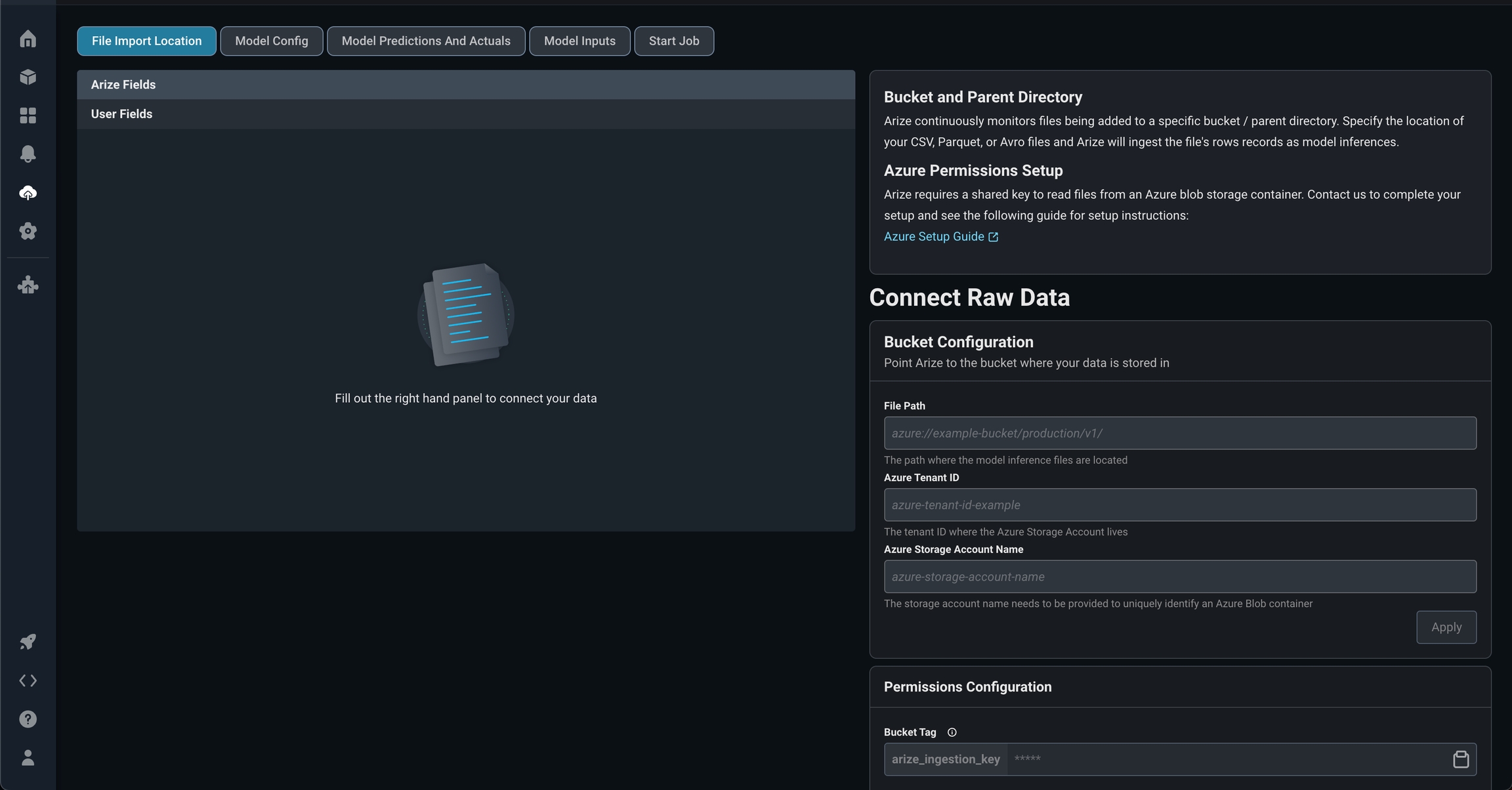
azure``://example-demo-bucket/click-thru-rate/production/v1/ that contains parquet files of your model inferences. Your bucket name is example-demo-bucket and your prefix is click-thru-rate/production/v1/.
The file structure can take into consideration various model environments (training, production, etc) and locations of ground truth. In addition, Azure blob store import allows recursive operations. This means that it will include all nested subdirectories within the specified bucket prefix, regardless of the number or depth of these directories
Step 5. Add Proof Of Ownership To Your Container
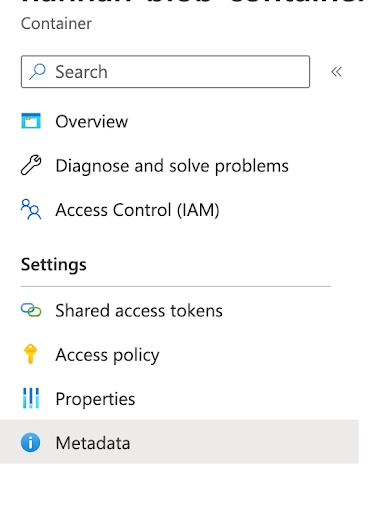
In your container metadata, add an entry with the key asarize_ingestion_key and the provided tag value.
-
In Arize UI: Copy the
arize_ingestion_keyvalue. - In Azure UI: Navigate to your Container -> Settings -> Metadata.
Step 6a. Define Your Model Schema
Model schema parameters are a way of organizing model inference data to ingest to Arize. When configuring your schema, be sure to match your data column headers with the model schema. You can either use a form or a simple JSON-based schema to specify the column mapping. Arize supports CSV, Parquet, Avro, and Apache Arrow. Refer here for a list of the expected data types by input type.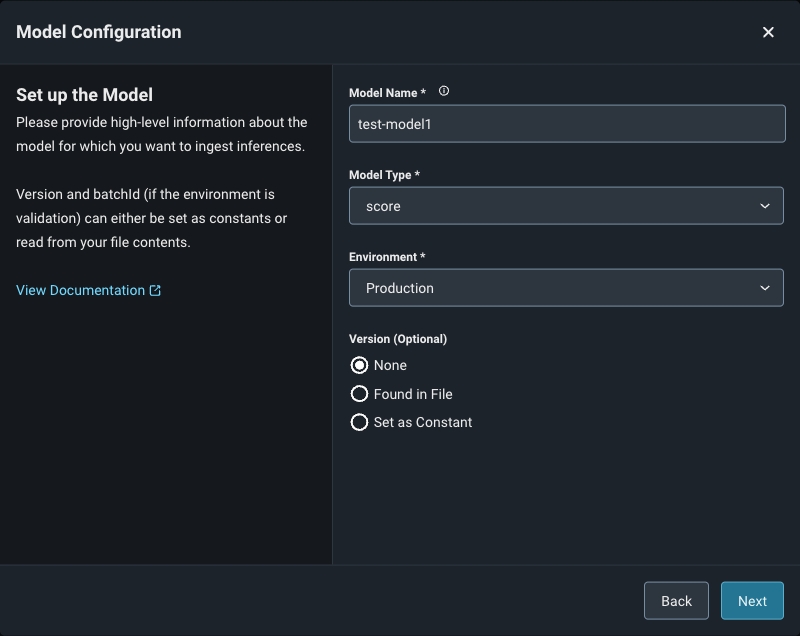
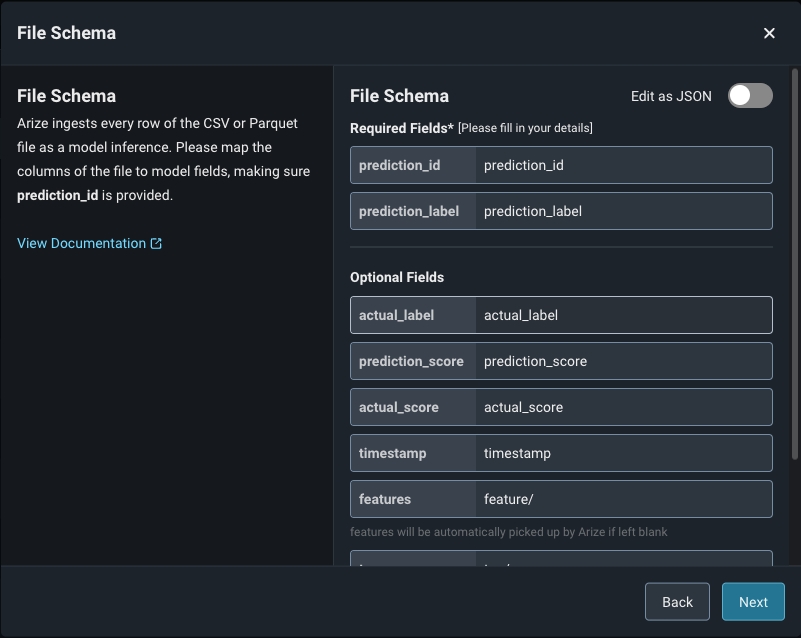
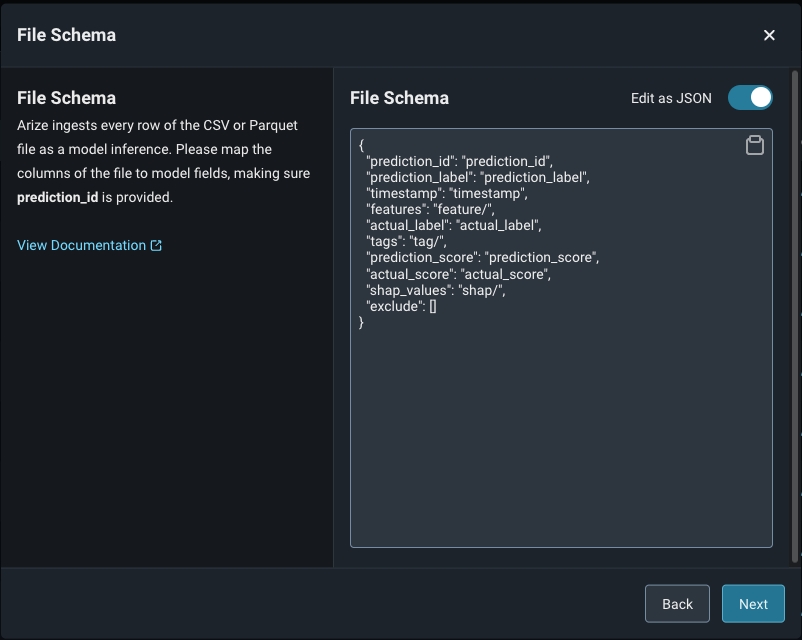
Step 6b. Validate Your Model Schema
Once you fill in your applicable predictions, actuals, and model inputs, click ‘Validate Schema’ to visualize your model schema in the Arize UI. Check that your column names and corresponding data match for a successful import job.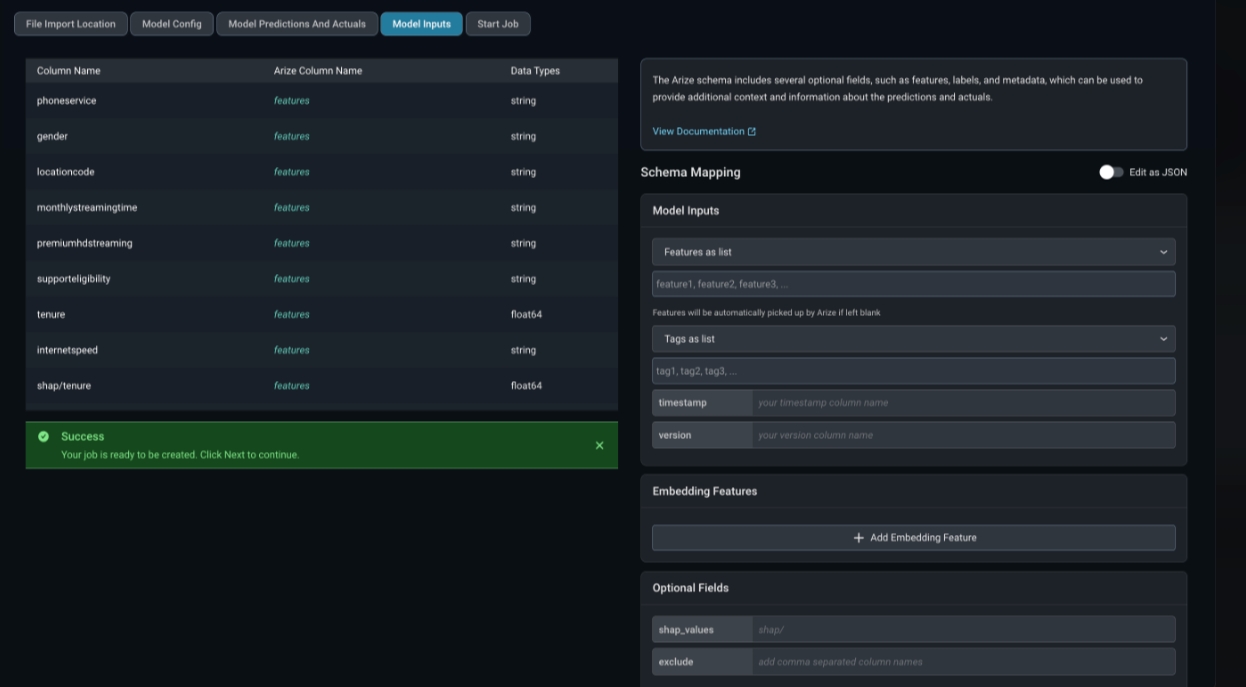
If your model receives delayed actuals, connect your predictions and actuals using the same prediction ID, which links your data together in the Arize platform. Arize regularly checks your data source for both predictions and actuals, and ingests them separately as they become available. Learn more here.
Step 7. Check Job Status
Arize will attempt a dry run to validate your job for any access, schema, or record-level errors. If the dry run is successful, you can proceed to create the import job. From there, you will be taken to the ‘Job Status’ tab. All active jobs will regularly sync new data from your data source with Arize. You can view the job details by clicking on the job ID, which reveals more information about the job.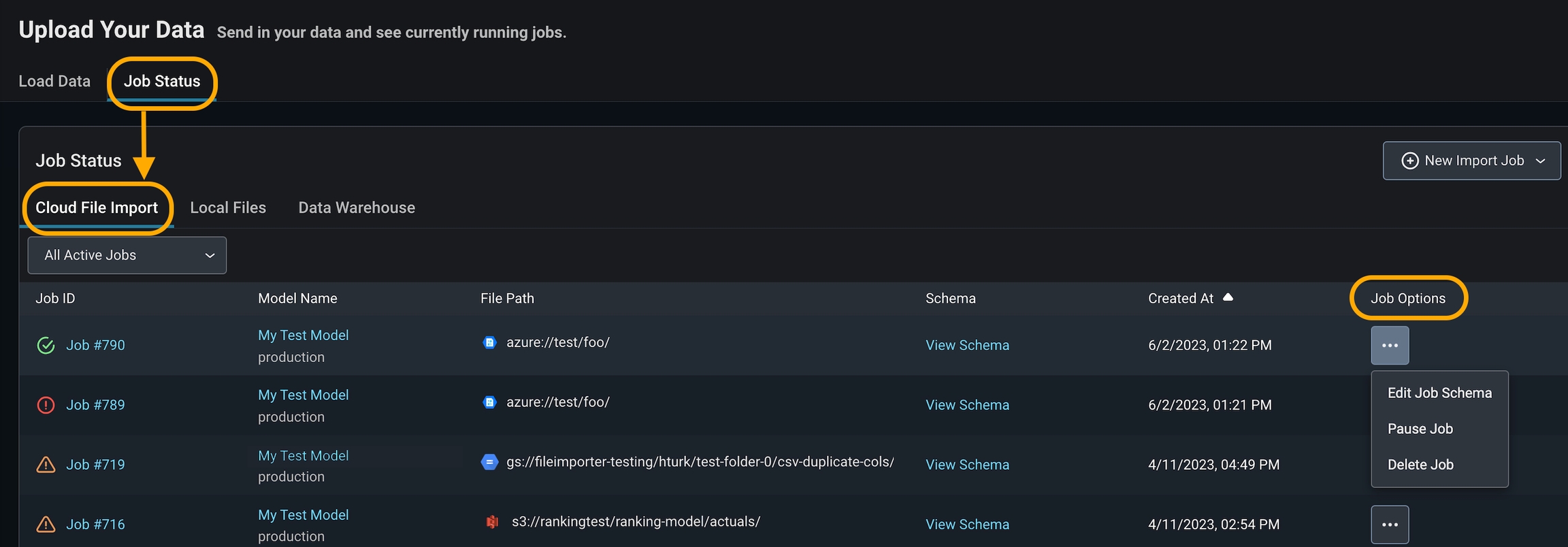
- Delete a job if it is no longer needed or if you made an error connecting to the wrong bucket. This will set your job status as ‘deleted’ in Arize.
- Pause a job if you have a set cadence to update your table. This way, you can ‘start job’ when you know there will be new data to reduce query costs. This will set your job status as ‘inactive’ in Arize.
- Edit a file schema if you have added, renamed, or missed a column in the original schema declaration.
Step 8. Troubleshoot Import Job
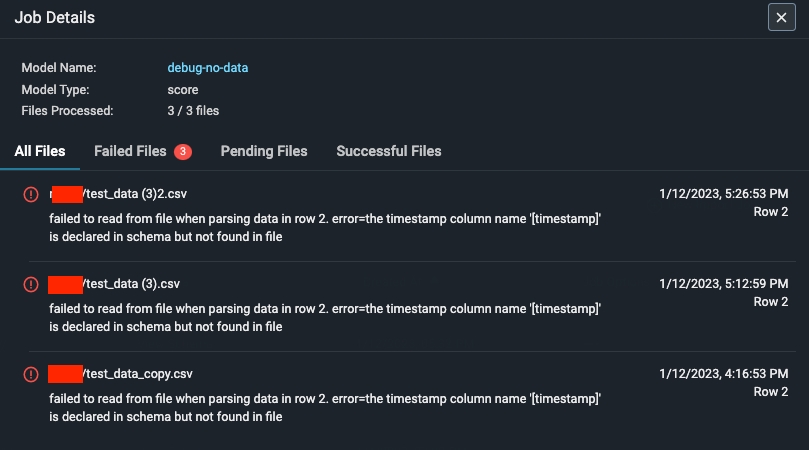
An import job may run into a few problems. Use the dry run and job details UI to troubleshoot and quickly resolve data ingestion issues.Validation Errors
If there is an error validating a file against the model schema, Arize will surface an actionable error message. From there, click on the ‘Fix Schema’ button to adjust your model schema.
Dry Run File/Table Passes But The Job Fails
If your dry run is successful, but your job fails, click on the job ID to view the job details. This uncovers job details such as information about the file path or query id, the last import job, potential errors, and error locations.