



We’ve fielded the same question at every conference this year. An engineer has chosen a framework, CrewAI one week, LangGraph the next, Mastra the week after, and wants to see exactly how observability plugs into the one they picked. OpenInference defines the span vocabulary, the framework-specific instrumentor packages do the wiring. What people want to see before they commit to wiring it into their own code is a complete, running agent with that work already done.
That is the gap Project Rosetta Stone closes. It’s a single repository where the same agent is built across 22+ agent frameworks and reference implementations, each shipped in three observability tiers: a baseline with no instrumentation, a Phoenix version, and an Arize AX version. Pick your framework, clone the directory, run it, and watch traces land. Diff the instrumented tier against the no-observability baseline and you see the exact files you need to touch in your own code.
The agent: Wonder Toys
The reference agent is Wonder Toys, a chat-to-purchase toy store.
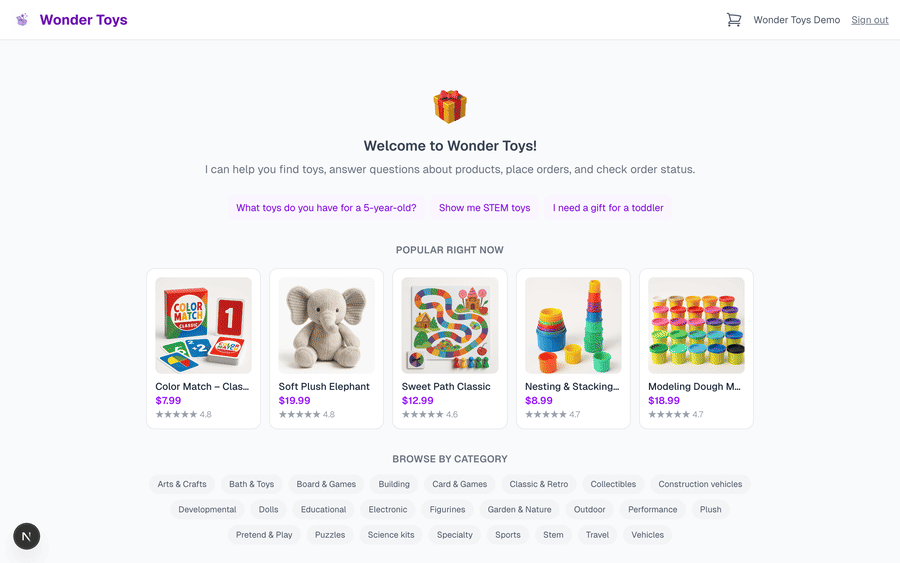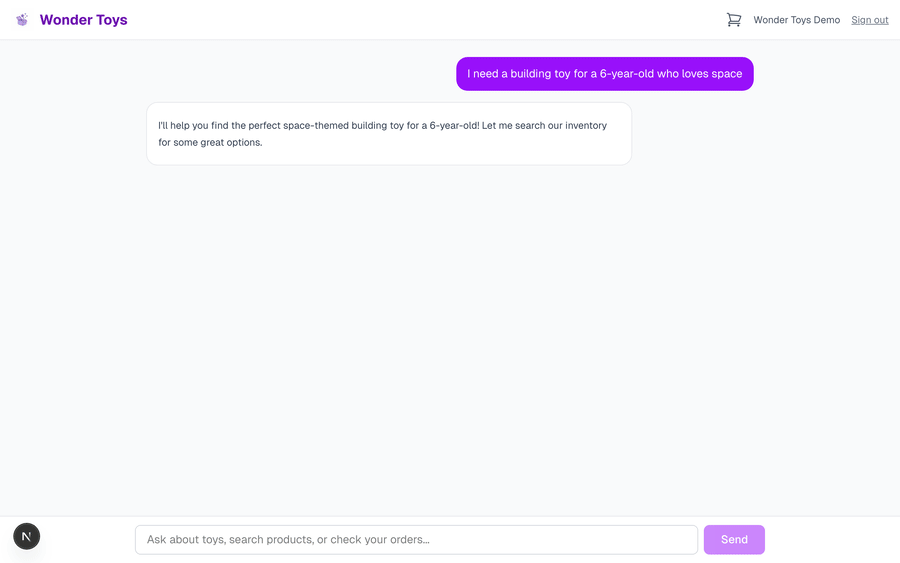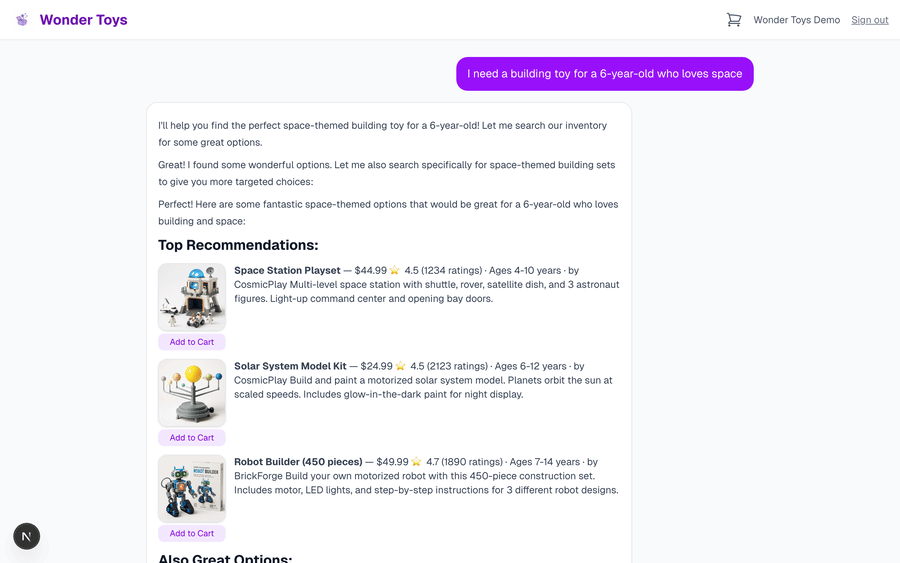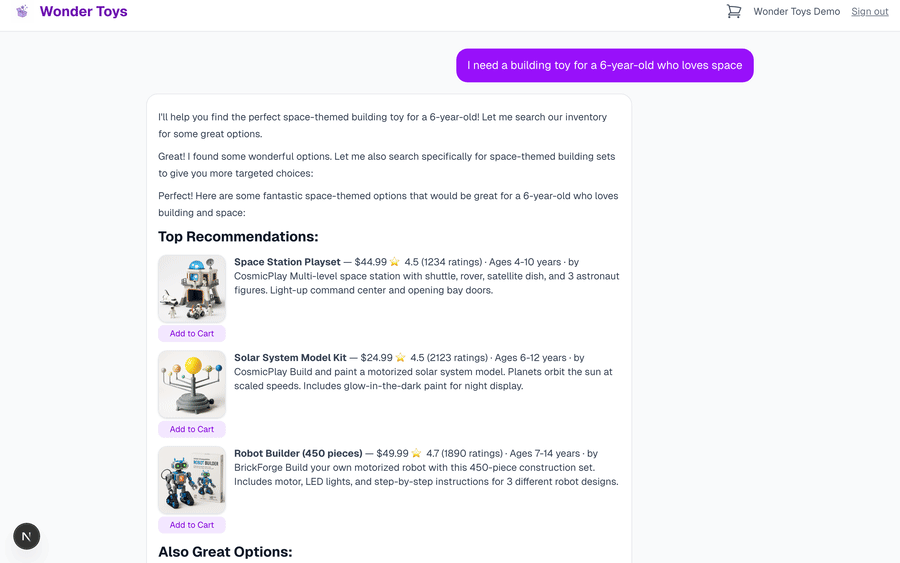
It does five things:
- Search a 200-product inventory by description, keyword, age range, or category
- Show product detail pages with rich markdown cards (images, prices, ratings)
- Purchase products with shipping details (credit card assumed on file)
- Track order status by ID or natural-language description
- Cancel orders that have not yet been delivered
It is not a hello-world. It has real retrieval (semantic search over 200 products via ChromaDB and all-MiniLM-L6-v2 embeddings, with keyword fallback), real tool calls (five tools across product catalog, vector search, and an in-memory order store), real streaming (each framework’s native event API), and real user sessions through NextAuth + X OAuth, with observability tiers attaching session information to traces. The traces look like production traces because the agent underneath looks like a production agent.
And like production applications, it also has its limitations with some subtle bugs, so it’s a great place to start testing out evals, Alyx, and Signal.
Architecture
Every tier and every framework runs the same shape: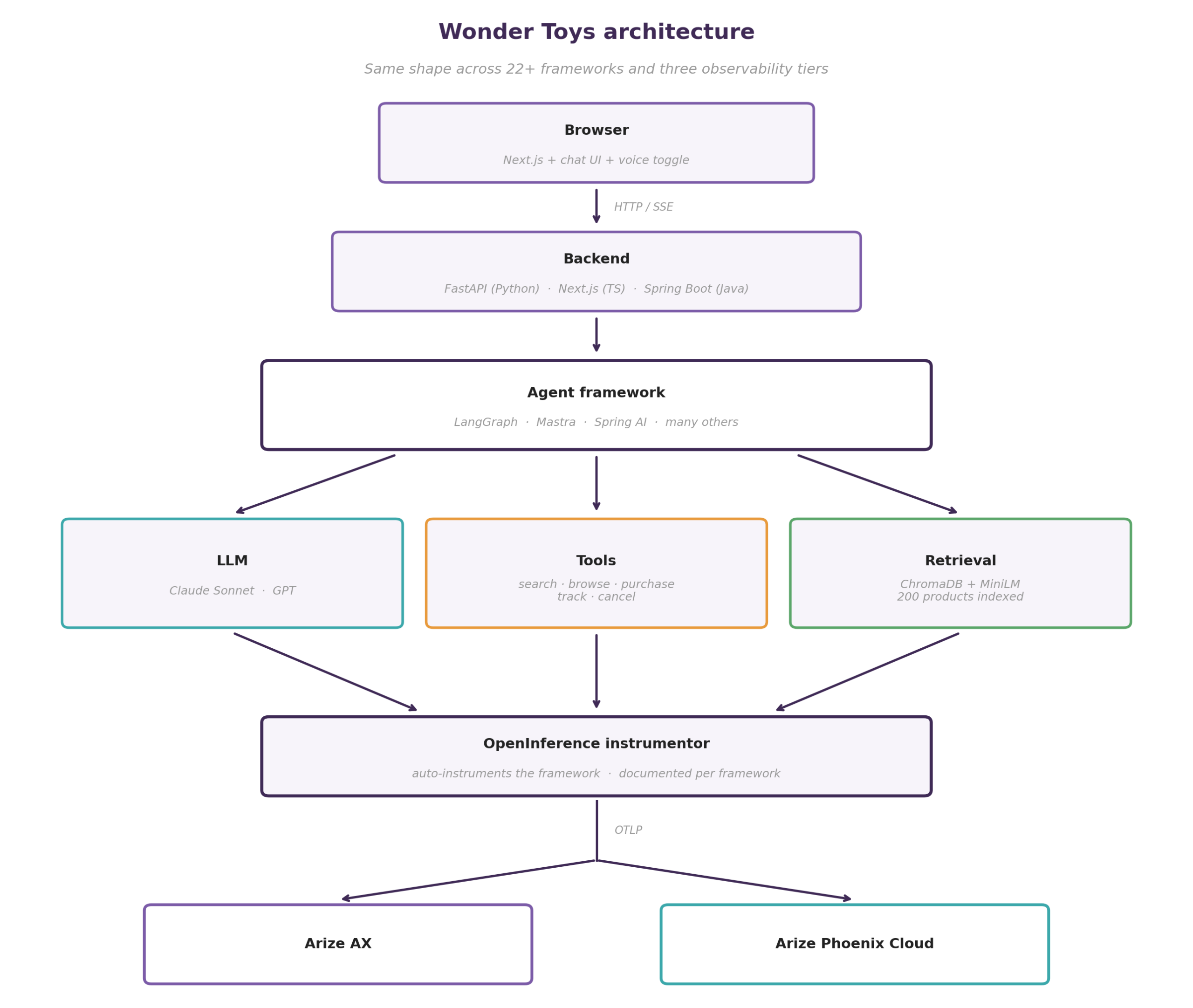
The frontend is identical across all tiers and frameworks. The backend shape varies by language: FastAPI for Python, a Next.js monolith for TS/JS, Spring Boot for Java. The agent runtime varies by framework. The LLM is Anthropic Claude for most tiers; the OpenAI Agents SDK and voice tiers use OpenAI. Tools and retrieval are identical everywhere. The instrumentation footprint is documented per framework.
Across many Python frameworks, the pattern starts the same way: register the backend tracer provider, then install the OpenInference instrumentor before framework imports. AX uses arize.otel.register(...); Phoenix uses phoenix.otel.register(...). The README documents the exact diff per framework.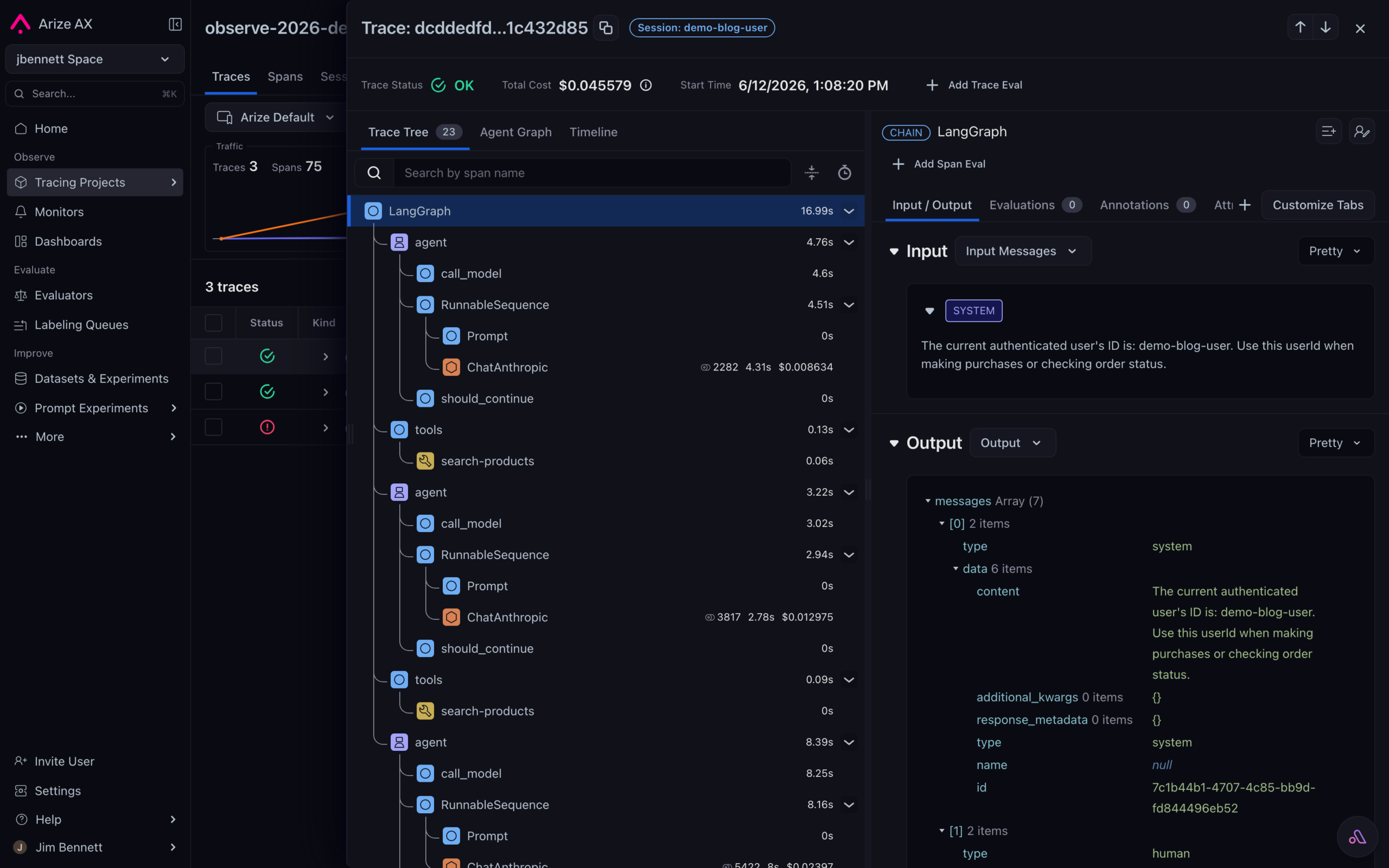
Here is what a Wonder Toys conversation looks like when you run the LangGraph version against Arize AX: a CHAIN root for LangGraph, repeated node spans for the agent loop, LLM spans for ChatAnthropic, and TOOL spans such as search-products. session.id and user.id ride along on the spans so the platform team can group by user without writing a custom wrapper.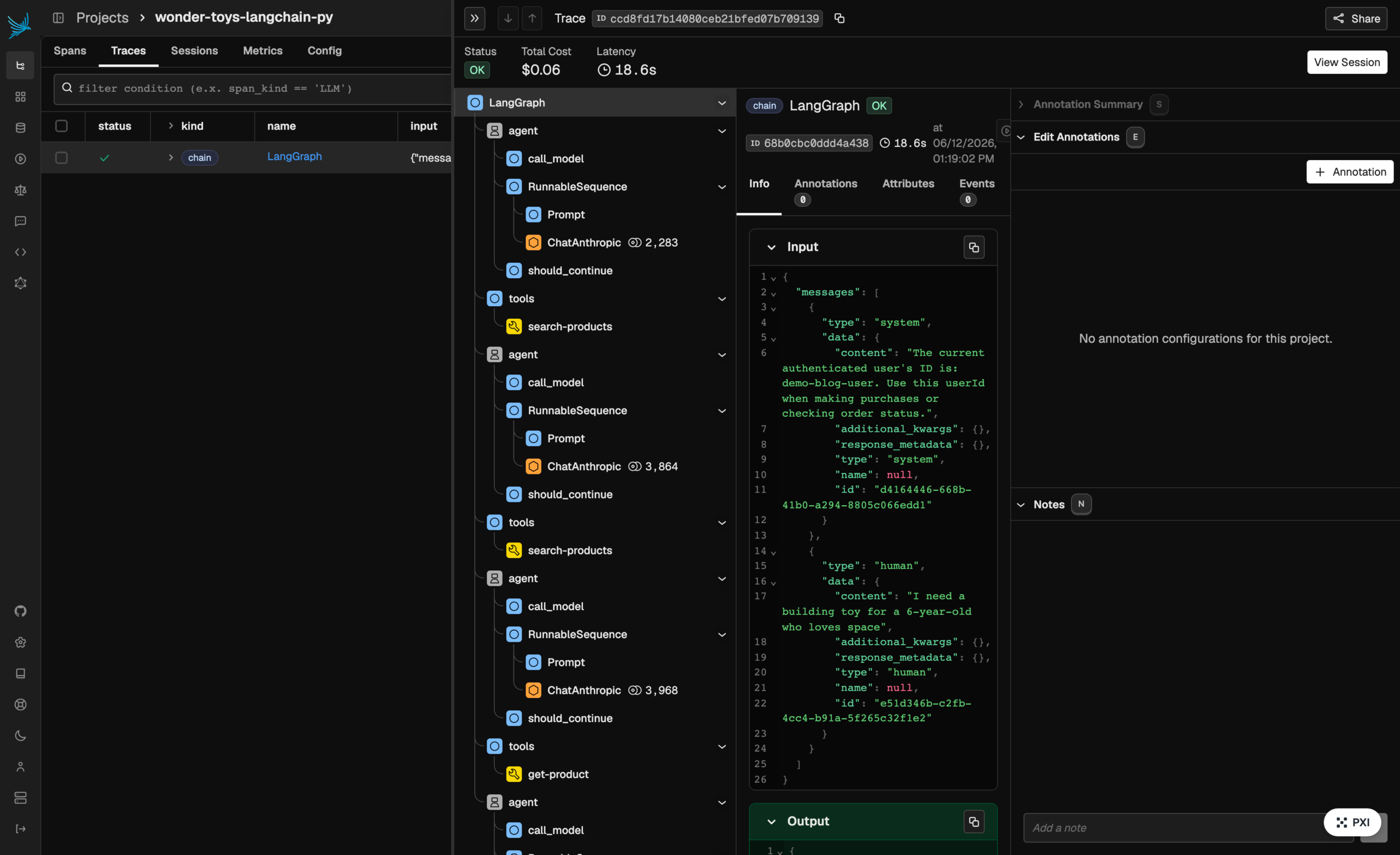
The same LangChain conversation produces the same observable structure in Phoenix: LangGraph, repeated agent-loop spans, ChatAnthropic LLM spans, and tool spans such as search-products and get-product. That is the consistency OpenInference gives you across backends.
The framework matrix
Find your framework, clone the directory, diff against the no-observability sibling. 22+ frameworks across three languages, three tiers each:
| Framework | Python | TS/JS | Java |
|---|---|---|---|
| Agno | ✅ | ||
| Arconia | ✅ | ||
| AutoGen AgentChat | ✅ | ||
| AWS Strands | ✅ | ||
| BeeAI | ✅ | ✅ | |
| CrewAI | ✅ | ||
| DSPy | ✅ | ||
| Google ADK | ✅ | ||
| Haystack | ✅ | ||
| LangChain / LangGraph / LangChain4j | ✅ | ✅ | ✅ |
| LlamaIndex | ✅ | ||
| LlamaIndex Workflows | ✅ | ||
| Mastra | ✅ | ||
| Microsoft Agent Framework | ✅ | ||
| Microsoft Semantic Kernel | ✅ | ||
| OpenAI Agents SDK | ✅ | ✅ | |
| OpenAI Realtime API (Voice) | ✅ | ||
| OpenInference Annotation Tracing | ✅ | ||
| Pydantic AI | ✅ | ||
| Smolagents | ✅ | ||
| Spring AI | ✅ | ||
| Vercel AI SDK | ✅ |
Every framework and tier directory is a self-contained app. Clone the repo, set up the environment, and run, and you have a running, instrumented agent in a few minutes. The local dev script also starts ChromaDB and indexes the 200 products the first time through.
The repo also ships a shared eval harness: 25 synthetic requests and six evaluators (Correctness, Tool Selection, Tool Response Handling, Format Compliance, Image URL Correctness, Tool Call Count). The Phoenix path runs the evaluators programmatically. The AX path generates the traces and you configure the same six evaluators in the AX console. The voice tier ships its own eight-prompt voice harness that streams pre-recorded MP3 prompts through the same WebSocket a real microphone would use.
Full setup steps, per-framework notes, and the evaluator templates are all in the repo README.
If your organization runs on more than one framework
The reference angle is the first reason most engineers reach for the repo. The second reason shows up at the platform layer: a lot of organizations don’t run agents on one framework. They run them on three, five, or more. The data team picked LangChain, the Java fintech app shipped on Spring AI, the new product line is on Mastra, the voice team is on the OpenAI Realtime API, someone is experimenting with Pydantic AI for a side project. Every choice is defensible. Different ergonomics, different language ecosystems, different runtime tradeoffs.
That diversity is fine in development. It is the platform and engineering teams that have to monitor and improve every one of those agents who feel it. They need a single pane of glass for observability: the same eval pipeline, the same alerting, the same dashboards, the same workflows, regardless of which framework an agent is built on.
Project Rosetta Stone is the proof that the single-pane-of-glass argument works in practice. Each tier under phoenix/ and ax/ emits OpenInference-shaped spans through OTLP. The traces from a LangGraph agent and a Spring AI agent land in the same backend, populate the same evaluator pipeline, and surface in the same dashboards. The same trace tree mental model applies to every framework in the matrix. One observability stack across every framework you ship.
A growing catalog
The framework landscape is moving fast. New frameworks ship every few months. Existing frameworks evolve their tracing APIs. The OpenInference instrumentor packages ship updates to match. Project Rosetta Stone will keep growing alongside them.
If you ship an agent framework and want it represented, or you spot a gap in how the current tiers handle a specific case, contributions are welcome. The repo has a CONTRIBUTING guide that documents how to add a new tier end-to-end: agent runtime, tools, instrumentor, eval harness, and screenshot capture.
Find your framework, read the diff, copy the pattern: github.com/Arize-ai/project-rosetta-stone.