



This post walks through how human annotations fit into your evaluation pipeline in Phoenix, why they matter, and how you can combine them with evaluations to build a strong experimentation loop.
Our notebook provides an easy way to test out these evaluations for yourself.
Why Annotations Matter In AI
Annotations, specifically human annotations, provide high-quality feedback on how your agent or AI system is performing. Unlike automated methods, human annotations are precise. But, they’re also time-consuming and don’t scale well. That means when we do have annotations, we should leverage them as much as possible to drive improvements in our applications.
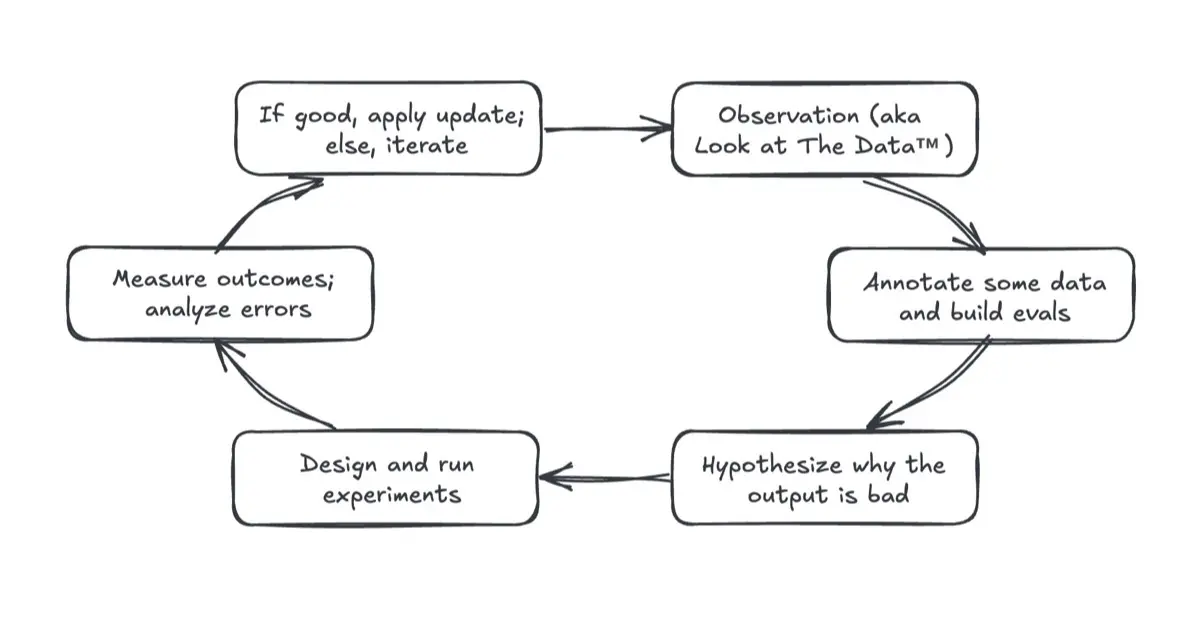
The process follows a flow like this (adapted from Eugene Yan’s article):
- Collect data and make observations – These are your traces and spans in Phoenix.
- Annotate some of the data – either via the Phoenix UI or API & save your annotated data as a dataset.
- Build an evaluator – use your annotated data to define quality checks.
- Run experiments – test hypotheses about what might improve results.
- Measure outcomes – analyze performance changes using your evaluator
- Apply updates – adopt the changes that work for your system
How To Annotate Your AI Application with Open Source Tools
You can annotate data in Arize-Phoenix in two ways:
- Directly in the Phoenix UI – configure categorical, numerical, or free-text labels and apply them to spans.
- Using the Phoenix REST API – great for building custom annotation tools that fit your team’s workflow.
For example, we built a custom annotation tool using the Phoenix REST API. It uses Lovable with a backend on Render to make it incredibly easy to visually see data and send annotations back to Phoenix. These tools make it easy for both technical and non-technical teammates to contribute annotations.
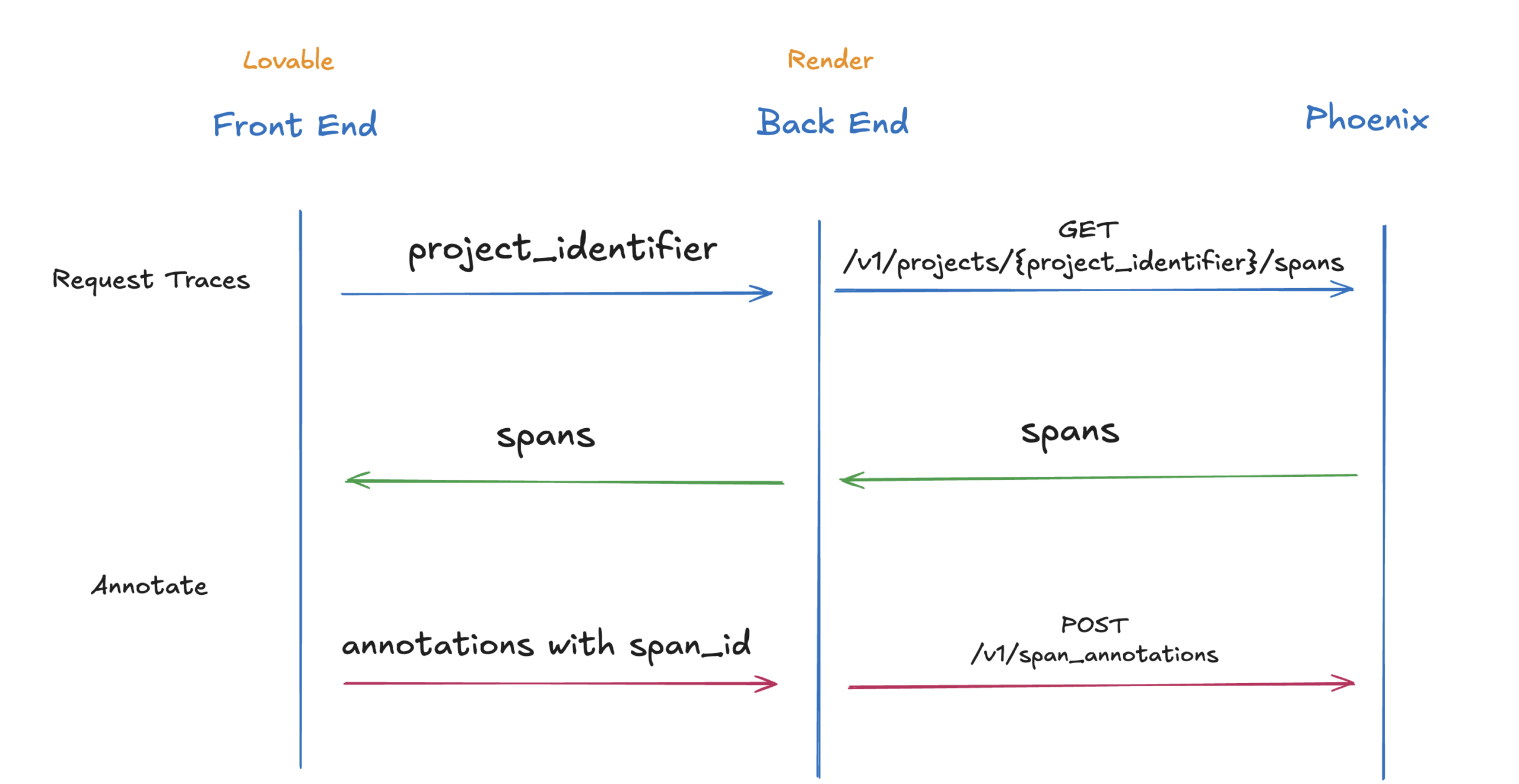
Note: This annotation UI was built for Phoenix Cloud demo purposes and is not optimized for high-volume trace workflows.
Step 1: Generating Traces
For this example, we generated a small dataset of 20 simple questions (e.g., Why is the sky blue?, Who painted the Mona Lisa?). The goal was to answer each question in the form of a rhyme. The system prompt instructed the model to answer in rhyme or nonsense, introducing both good and bad examples for annotation.
Step 2: Annotating Traces
Using the custom tool, we then annotated traces as Correct or Incorrect. Phoenix allows you to define multiple annotation types (e.g., correctness, relevance, frustration), but for this demo we focus on correctness. Each annotation was saved to Phoenix in real-time.
After annotating half the traces, we saw a correctness score of ~20%. Even a small number of annotations like these can provide strong grounding for evaluations. We saved our annotated traces as a dataset. In Phoenix, the annotations persist within each dataset row as metadata.
Step 3: Building an Evaluator
Next, the evaluator was built using the LLM-as-a-judge approach. The evaluator prompt instructed the model to:
- Check if the response was a proper rhyme.
- Mark answers with irrelevant numbers or nonsense as incorrect.
This evaluator returned structured outputs (Correct / Incorrect) with explanations. We tested our evaluator on the annotated dataset to ensure that it was able to score outputs properly. In this portion, the annotations acted as ground truth labels to improve the evaluator.
Step 4: Running Experiments
With the annotated dataset and evaluator in place, a series of experiments were run that included model swaps and prompt changes. As part of each experiment, we ran the evaluator to score performance. Phoenix’s experiment tracking made it easy to compare results across runs and visualize improvements.
Step 5: Applying Updates
Once we were confident in a change or improvement, we applied it back to the original dataset. Running the full experiment and evaluator across the entire dataset confirmed that the improvements generalized well, even to traces and use cases we hadn’t explicitly annotated.
Key Takeaways
- Human annotations provide precision but don’t scale. Use them to ground evaluators and bootstrap experiments.
- Phoenix makes it easy to combine annotations, evaluators, and experiments into a systematic pipeline.
- Custom annotation tools can empower more team members to contribute feedback easily.
- Iterative experimentation helps pinpoint what drives quality improvements.
With just a handful of annotations and structured experimentation, teams can move from noisy outputs to consistent, high-quality responses.