Documentation Index
Fetch the complete documentation index at: https://arize-ax.mintlify.dev/docs/llms.txt
Use this file to discover all available pages before exploring further.
Ranking Model Overview
There are four key ranking model use cases to consider:
-
Search Ranking
-
Collaborative Filtering Recommender Systems
-
Content Filtering Recommender Systems
-
Classification-Based Ranking Models
Different metrics are used for ranking model evaluation based on your model use case, score, and label availability. The case determines the available performance metrics. Click here for all valid model types and metric combinations.
| Ranking Cases | Example Use Case | Expected Fields | Performance Metrics |
|---|
| Case 1: Ranking with Relevance Score | Model predicts score used to rank | rank, relevance score | NDCG |
| Case 2: Ranking with Single Label | Model predicts binary actions a user can take which is used to rank | rank, relevance_labels | NDCG, GroupAUC, MAP, MRR |
| Case 3: Ranking with Multiple Labels | Model predicts multiple actions a user can take which is used to rank | rank, relevance_labels (list of strings) | NDCG, GroupAUC, MAP, MRR |
| Ranking + AUC and LogLoss | Model can also be evaluated using AUC + LogLoss | Ranking Case 2 or 3, prediction score | NDCG, GroupAUC, MAP, MRR, AUC, PR-AUC, Log Loss |
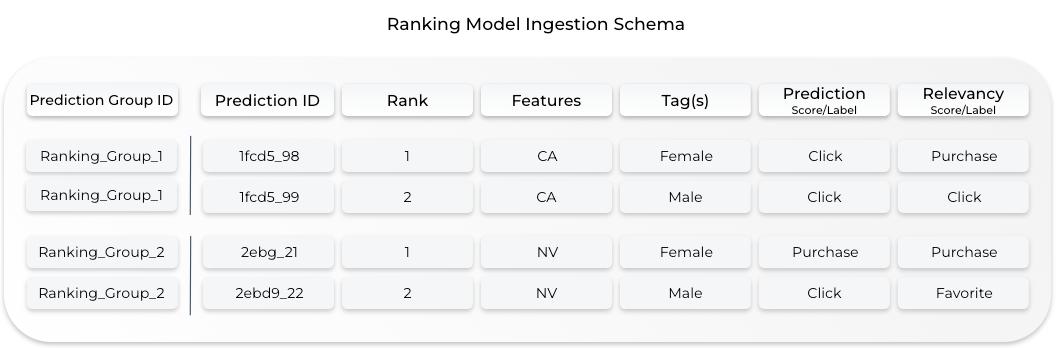
General Ranking Model Schema
Ranking models have a few unique model schema fields that help Arize effectively monitor, trace, and visualize your ranking model data.
-
Prediction Group ID: A subgroup of prediction data. Max 100 ranked items within each group
-
Rank: Unique value within each prediction group (1-100)
-
Relevancy Score/Label: Ground truth score/label associated with the model
Case 1: Ranking with Relevance Score
In the ranking model context, a relevance score is a ground truth numerical score where the higher the relevance_score, the more important the item is. For example, if an item was clicked on it may have a relevance score of 0.5, whereas if it was purchased that relevancy score would be 1.
rank and relevance_score are required to compute rank-aware evaluation metrics on your model.
| Ranking Model Fields | Data Type | Example |
|---|
| rank | int from 1-100 | 1 |
| relevance_score | numeric (float | int) | 0.5 |
| prediction_group_id | string limited to 128 characters | 148 |
Code Example
Python Pandas
Python Single Record
Data Connector
Example Row| state | price | search_id | rank | relevance_score | prediction_ts |
|---|
ca | 98 | 148 | 1 | 0.5 | 1618590882 |
# feature & tag columns can be optionally defined with typing:
tag_columns = TypedColumns(
inferred=["name"],
to_int=["zip_code", "age"]
)
schema = Schema(
prediction_id_column_name="prediction_id",
timestamp_column_name="prediction_ts",
prediction_group_id_column_name = "search_id",
rank_column_name = "rank",
relevance_score_column_name = "relevance_score",
feature_column_names=["state", "price"],
tag_column_names=tag_columns,
)
response = arize_client.log(
dataframe=df,
model_id="ranking-relevance-score-batch-ingestion-tutorial",
model_version="1.0",
model_type=ModelTypes.RANKING,
metrics_validation=[Metrics.RANKING],
environment=Environments.PRODUCTION,
schema=schema,
)
Python Batch API Reference
# import extra dependencies
from arize.utils.types import Environments, ModelTypes, Schema, RankingPredictionLabel, RankingActualLabel
# define prediction label arguments
pred_label = RankingPredictionLabel(
group_id="148",
rank=1,
score=0.155441
)
# define actual label argument
act_label = RankingActualLabel(
relevance_score=0.5
)
# log data to Arize
response = arize_client.log(
model_id="demo-ranking-with-relevance-score",
model_version="v1",
environment=Environments.PRODUCTION,
model_type=ModelTypes.RANKING,
prediction_id="311103e3-a493-40ea-a21a-e457d617c956",
prediction_label=pred_label,
actual_label=act_label,
features=features
)
Download an example Parquet file:Open parquet reader here.Learn how to upload files via various Data Connectors:Google Cloud Storage (GCS)
Case 2: Ranking with Single Label
In this case, relevance_scoredoes not need to be passed in. Since relevance_score is required to compute rank-aware evaluation metrics, Arize uses an attribution model to create a relevance_score based on your positive class and relevance_labels. Learn more about our attribution model here.
| Ranking Model Fields | Data Type | Example |
|---|
| rank | int from 1-100 | 1 |
| relevance_labels | string | “click” |
| prediction_group_id | string limited to 128 characters | 148 |
Code Example
Python Pandas
Python Single Record
Data Connectors
Example Row| state | price | search_id | rank | actual_relevancy | prediction_ts |
|---|
ca | 98 | 148 | 1 | "not relevant" | 1618590882 |
# feature & tag columns can be optionally defined with typing:
tag_columns = TypedColumns(
inferred=["name"],
to_int=["zip_code", "age"]
)
schema = Schema(
prediction_id_column_name="prediction_id",
timestamp_column_name="prediction_ts",
prediction_group_id_column_name = "search_id",
rank_column_name = "rank",
relevance_labels_column_name = "actual_relevancy",
feature_column_names=["state", "price"],
tag_column_names=tag_columns,
)
response = arize_client.log(
dataframe=df,
model_id="ranking-single-label-batch-ingestion-tutorial",
model_version="1.0",
model_type=ModelTypes.RANKING,
metrics_validation=[Metrics.RANKING, Metrics.RANKING_LABEL],
environment=Environments.PRODUCTION,
schema=schema,
)
# import extra dependencies
from arize.utils.types import Environments, ModelTypes, Schema, RankingPredictionLabel, RankingActualLabel
# define prediction label arguments
pred_label = RankingPredictionLabel(
group_id="148",
rank=1,
label="relevant"
)
# define actual label argument
act_label = RankingActualLabel(
relevance_labels=["Not relevant"]
)
# log data to Arize
response = arize_client.log(
model_id="demo-ranking-with-single-label",
model_version="v1",
environment=Environments.PRODUCTION,
model_type=ModelTypes.RANKING,
prediction_id="311103e3-a493-40ea-a21a-e457d617c956",
prediction_label=pred_label,
actual_label=act_label,
features=features
)
Download an example Parquet file:Open parquet reader here.Learn how to upload files via various Data Connectors:Google Cloud Storage (GCS)
Case 3: Ranking with Multiple Labels
Since ground truth can contain multiple events, you can pass in multiple ground truth labels in a list.
In this case relevance_score does not need to be passed in. Since relevance_score is required to compute rank-aware evaluation metrics, Arize uses an attribution model to create a relevance_score based on your positive class and relevance_labels. Learn more about our attribution model here.
| Ranking Model Fields | Data Type | Example |
|---|
| rank | int from 1-100 | 1 |
| relevance_labels | list of strings | [“click”, “favorite”, “buy”] |
| prediction_group_id | string limited to 128 characters | 148 |
Code Example
Python Pandas
Python Single Record
Data Connector
Example Row| state | price | search_id | rank | attributions | prediction_ts |
|---|
ca | 98 | 148 | 1 | "click, favorite, buy" | 1618590882 |
# feature & tag columns can be optionally defined with typing:
tag_columns = TypedColumns(
inferred=["name"],
to_int=["zip_code", "age"]
)
schema = Schema(
prediction_id_column_name="prediction_id",
timestamp_column_name="prediction_ts",
prediction_group_id_column_name = "search_id",
rank_column_name = "rank",
relevance_labels_column_name = "attributions"
feature_column_names=["state", "price"],
tag_column_names=tag_columns,
)
response = arize_client.log(
dataframe=df,
model_id="ranking-multiple-labels-batch-ingestion-tutorial",
model_version="1.0",
model_type=ModelTypes.RANKING,
metrics_validation=[Metrics.RANKING, Metrics.RANKING_LABEL],
environment=Environments.PRODUCTION,
schema=schema,
)
Python Batch API Reference
# import extra dependencies
from arize.utils.types import Environments, ModelTypes, Schema, RankingPredictionLabel, RankingActualLabel
# define prediction label arguments
pred_label = RankingPredictionLabel(
group_id="148",
rank=2,
label="click"
)
# define actual label argument
act_label = RankingActualLabel(
relevance_labels=["book", "click"]
)
# log data to Arize
response = arize_client.log(
model_id="demo-ranking-with-multiple-labels",
model_version="v1",
environment=Environments.PRODUCTION,
model_type=ModelTypes.RANKING,
prediction_id="dd19bee3-e7f4-4207-aef9-3abdad2a9be0",
prediction_label=pred_label,
actual_label=act_label,
features=features
)
Download an example Parquet file:Open parquet reader here.Learn how to upload files via various Data Connectors:Google Cloud Storage (GCS)
Ranking Single or Multi-Label + AUC and LogLoss
AUC and LogLoss are computed based on prediction_score and relevance_labels (or default relevance_labels in the case of multi-label).
| Ranking Model Fields | Data Type | Example |
|---|
| rank | int from 1-100 | 1 |
| prediction_score | float | 0.5 |
| prediction_group_id | string limited to 128 characters | 148 |
NDCG @k
Normalized discounted cumulative gain (NDCG) is a rank-aware evaluation metricthat measures a model’s ability to rank query results in the order of the highest relevance (graded relevance). You can read more about how NDCG is computed here.
What is @k?The k value determines the metric computation up to position k in a list.
Selecting Relevance Score or Label - Attribution Model
A relevance score is required to calculate rank-aware evaluation metrics. If your relevance_score is unavailable, the Arize platform will calculate a relevance_score using a simple attribution model with a prediction label and a relevance label. Arize computes a binary relevance value (0/1) based on the default positive class.
-
Positive class “buy” and relevance label is “buy” —> relevance will be attributed to 1.
-
Positive class “buy” and relevance label is else —> relevance will be attributed to 0.
-
Positive class “buy” and relevance labels are [“buy”, “click”, “scroll”] —> relevance will be attributed to
sum([1,0,0])
Ranking Quick Definitions
Ranking model: Assigns a rank to each item in a prediction group (also known as a batch or query), across many possible groups.
Arize supports pointwise,pairwise, and listwise ranking models
Prediction Group: A group of predictions within which items are ranked.
Example: A user of a hotel booking site types in a search term (“skiing”) and is presented with a list of results representing a single query
Rank: The predicted rank of an item in a prediction group (Integer between 1-100).
Example: Each item in the search prediction group has a rank determined by the model (i.e. Aspen is assigned rank=1, Tahoe is assigned rank=2, etc. based on input features and query features to the model)
Relevance Score (i.e. Actual Scores): The ground truth relevance score (numeric). Higher scores denote higher relevance.
Example: Each item in the search prediction group has a score determined by the action a user took on the item (i.e. “clicking” on an item indicates relevance score = 0.5, purchasing an item indicates relevance score = 1)
Rank-Aware Evaluation Metric: A rank-aware evaluation metric is an evaluation metric that gauges rank order and relevancy of predictions.
Rank-aware evaluation metrics include NDCG, MRR, and MAP. Note that MRR and MAP also require relevance_labels to be provided to be computed.