
AI agents become dangerous at the moment they gain the ability to execute actions.
The moment an agent can touch the file system or invoke external tools, safety shifts from language to execution. What matters is not what the model says, but what the runtime allows it to do. Most existing isolation mechanisms, like VM or containers, operate below this level. They constrain the environment, but they provide little insight into how agent behavior unfolds step by step.
A recent study by Tsinghua University shows that as agents plan, retry, and adapt across multiple tool invocations, this lack of visibility becomes a liability: when something breaks, there’s no clear record of which action was attempted, which policy applied, or why the decision was made.
This article introduces an observability-driven approach to sandboxing using Google ADK and Arize Phoenix. Tool invocations are treated as capability requests, evaluated at runtime, and traced using OpenTelemetry. Every allow or deny decision becomes part of the execution trace, making agent behavior inspectable.
Introducing Observability-Driven Sandboxing
Observability-driven sandboxing is a runtime enforcement layer that intercepts agent tool calls and decides whether they are allowed to execute. In this system, the agent still plans actions and selects tools, but execution is gated by explicit policy checks implemented in code. The sandbox resides between inference and side effects, where decisions can be enforced without modifying the model’s behavior.
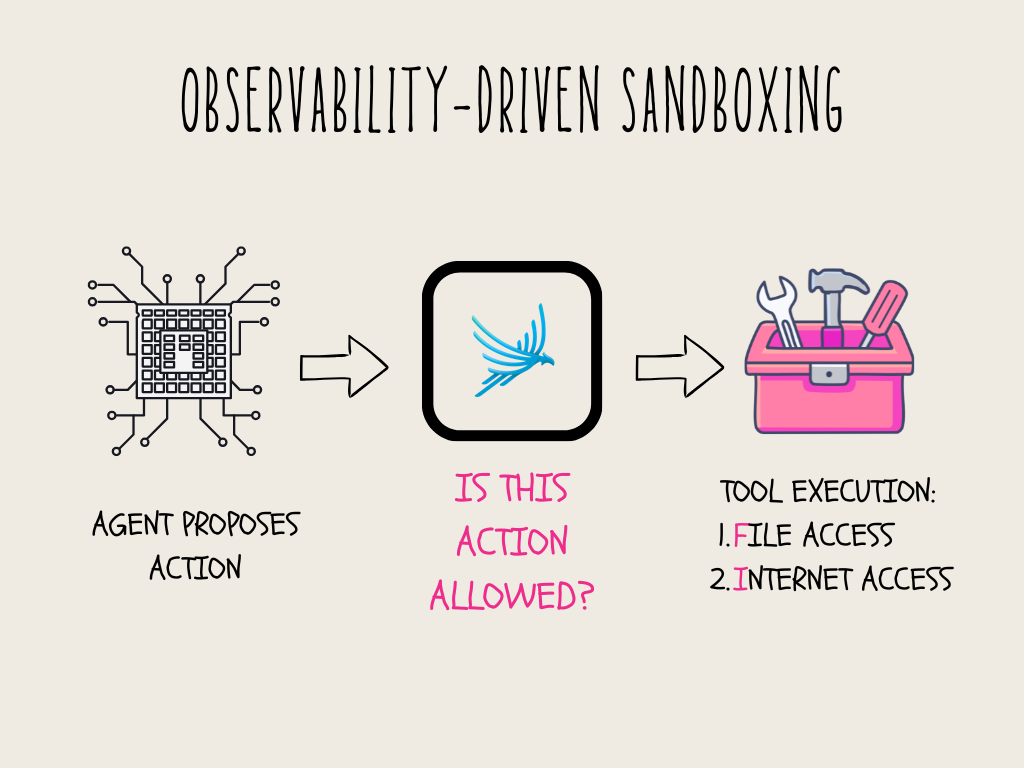
Each tool invocation is treated as a request for a capability. Reading a file, listing a directory, or contacting a host is evaluated at execution time against a defined policy. If the request is allowed, the tool runs. If it is denied, the action is blocked before any side effect occurs.
Every decision made by the sandbox is emitted as a trace event using OpenTelemetry and visualized in Arize Phoenix. Check out this article to learn more about how tracing works in Arize Phoenix. This makes enforcement observable. Instead of a singular inference output, you get why an action failed, and developers can inspect the exact point where a decision was made and see the policy outcome in context.
How Observability-Driven Sandboxing Works
To keep the example concrete, the sandbox enforces a single rule: the agent may read files only inside a defined workspace. Any attempt to access files outside that boundary is blocked. This example exists to demonstrate execution-time enforcement and how those decisions surface through tracing.
This setup exposed an issue during development. The same workspace also contained environment configuration files with active credentials. With unrestricted file access, an agent could read those files simply because they were present on disk. No exploit was required.
Observability-driven sandboxing makes this boundary explicit for the runtime. Each file access attempt is evaluated at execution time and recorded as a policy decision. The next section explains how these policies are defined.
How To Define Policies for a Sandbox
In this tutorial, policies are defined as code. They run every time the agent tries to execute a tool. The sandbox intercepts the tool call, converts the call into a resource hint, runs a policy check, and enforces the returned decision. We implemented three practical rule-classes:
| Policy | Purpose | Enforcement |
| Workspace enforcement | Confines file reads and writes to a designated directory | Requests outside the workspace are blocked |
| Network allowlist | Restricts external connections to approved hosts | All other hosts are denied |
| Write control | Prevents unapproved file modifications | Only versioned or approved writes succeed |
While these rules may seem simple at first glance, in practice, access to data is everything. Workspace enforcement, network allowlists, and write controls through concrete logic illustrate how even minimal policies create meaningful boundaries.
The same framework can easily extend to API access, prevent prompt injection, and defend against TOCTOU attacks, without limiting the agent’s reasoning capabilities.
In theory, the agent can plan actions as it normally would, but the sandbox enforces rules by feeding back a clear message whenever an action is not allowed. This ensures the agent understands the restriction while all decisions remain observable and auditable.
Quickstart: Implementing Observability-Driven Sandboxing
The full reference implementation for this tutorial is available on GitHub. The sections below focus on the core observability concepts for AI agents needed to understand how observability-driven sandboxing works in practice.
While the tutorial focuses on isolating events in a Google ADK AI Agent, the same concept can be applied across other frameworks. For readers looking to integrate Phoenix specifically from a Google ADK standpoint, detailed guidance is available here.
From tool calls to enforceable capabilities
In a sandboxed AI agent, every intended action — reading a file, listing a directory, or summarizing a document — is first converted into a concrete capability that can be checked against policies. This happens at runtime, ensuring safety and observability without changing the agent’s planning.
Key points:
- Resource translation: Each tool call becomes a structured resource with type, path/host, and metadata.
- Policy evaluation: Resources are checked against rules like workspace boundaries, network allowlists, and write restrictions.
- Decision enforcement: Allowed actions execute normally; denied actions return a standardized error object.
- Observability: Each decision and action is traced, creating an auditable execution record.
Example Python wrapper implementing this flow:
from typing import Callable
from sandbox import policy_check, SandboxConfig, start_policy_check_span, emit_policy_counter
class SandboxedTool:
def __init__(self, func: Callable):
self.func = func
self.cfg = SandboxConfig.load_from_env()
def build_resource(self, *args, **kwargs):
return {
"type": "fs",
"path": args[0] if args else "",
"meta": {"func": self.func.__name__}
}
def __call__(self, *args, **kwargs):
# Step 1: Convert the tool call into a structured resource
resource = self.build_resource(*args, **kwargs)
# Step 2: Start a tracing span for observability (record the policy decision)
with start_policy_check_span(None, "policy.check") as span:
# Evaluate the resource against sandbox policies
decision = policy_check("tool.invoke", resource, self.cfg)
# Record the decision in the trace
span.set_attribute("sandbox.decision", decision.get("decision"))
# Step 3: If the action is denied by policy, stop execution
if decision.get("decision") != "allow":
# Increment a counter for monitoring violations
emit_policy_counter(span, "sandbox.violation_count", 1)
# Return a standardized error object to the agent
return {"error": "blocked", "decision": decision}
# Step 4: If the action is allowed, execute the original tool function
return self.func(*args, **kwargs)
# Example: Wrap a simple file-reading tool
@SandboxedTool
def read_markdown_file(filename: str):
"""Reads a markdown file from disk"""
with open(f"tests/markdown_samples/{filename}") as f:
return f.read()
This wrapper ensures that every tool call is validated and traced, enforcing policies consistently while keeping runtime actions auditable.
Defining sandbox policies as code
In the sandbox, policies are defined directly in code. Each action the agent attempts is checked against deterministic, local rules. The result is returned as a structured object:
class PolicyDecision(TypedDict):
allow: bool
decision: str # "allow", "deny", or "escalate"
rule_id: str # identifier for the applied rule
reason: str # human-readable explanation
meta: Dict[str, Any] # optional metadata
resolved_path: str # ensures the path is safe and prevents TOCTOU attacks
The check function starts a tracing span for each policy evaluation:
def check(action: str, resource: Resource, config: SandboxConfig = None) -> PolicyDecision:
cfg = config or SandboxConfig.load_from_env()
# Start a policy.check span for tracing
tracer = tracing.get_tracer("sandbox.policy")
with tracing.start_policy_check_span(tracer, "policy.check", openinference_span_kind="guardrail") as span:
span.set_attribute("input", json.dumps({"action": action, "resource": resource}))
span.set_attribute("sandbox.policy_name", "default")
# Determine decision (filesystem logic, network checks, and other rules)
# ...comments for path resolution, denylists, read/write checks...
decision: PolicyDecision = ... # final PolicyDecision returned
# Emit the decision as an annotation to Phoenix
# ...Phoenix annotation logic...
return decision
Every decision is traced and emitted as an annotation to Phoenix, creating an auditable record of what the agent attempted and why it was allowed or blocked.
These policies enforce core safety checks, including:
- Confinement to workspace directories
- Blocking access to sensitive paths
- Denying unapproved file writes
- Controlling network access via allowlists
For readers interested in the full implementation — including detailed path resolution, write restrictions, and tracing — the repository contains the complete code. This snippet highlights the essence: the PolicyDecision TypedDict defines the contract through which sandboxing enforces safe, observable agent behavior.
Tracing policy enforcement with Arize Phoenix
Every policy check emits a policy.check span. Every tool execution emits a tool.invoke span. These spans carry key metadata about the policies, tools, session runtime, and decisions taken by the policy engine.
Decisions also become visible as labeled events in Phoenix via a best-effort annotation:
# inside policy.check
span.set_attribute("sandbox.decision", decision.get("decision"))
span.set_attribute("sandbox.rule_id", decision.get("rule_id"))
span.set_attribute("sandbox.reason", decision.get("reason"))
span.set_attribute("output", json.dumps(decision))
# annotate in Phoenix (non-blocking)
try:
client = pc.Client()
client.spans.add_span_annotation(
span_id=format_span_id(span.get_span_context().span_id),
annotation_name="policy_decision",
annotator_kind="CODE",
label=decision.get("decision"),
score=1.0 if decision.get("decision") == "allow" else 0.0,
explanation=decision.get("reason")
)
except Exception:
pass
This makes every decision visible in the dashboard. You can filter by rule, decision, session, or tool. Instrumentation won’t block execution if Phoenix is unavailable.
Interpreting the dashboard
A trace in Arize Phoenix captures the full lifecycle of a single agent request, from the moment the user sends input, through planning, policy evaluation, tool execution, and finally the response back to the UI. The timeline shows the session from start to finish, with spans representing key steps:
- Planning – agent tool decisions
- Policy check (
policy.check) – capability evaluation - Tool invoke (
tool.invoke) – execution or error
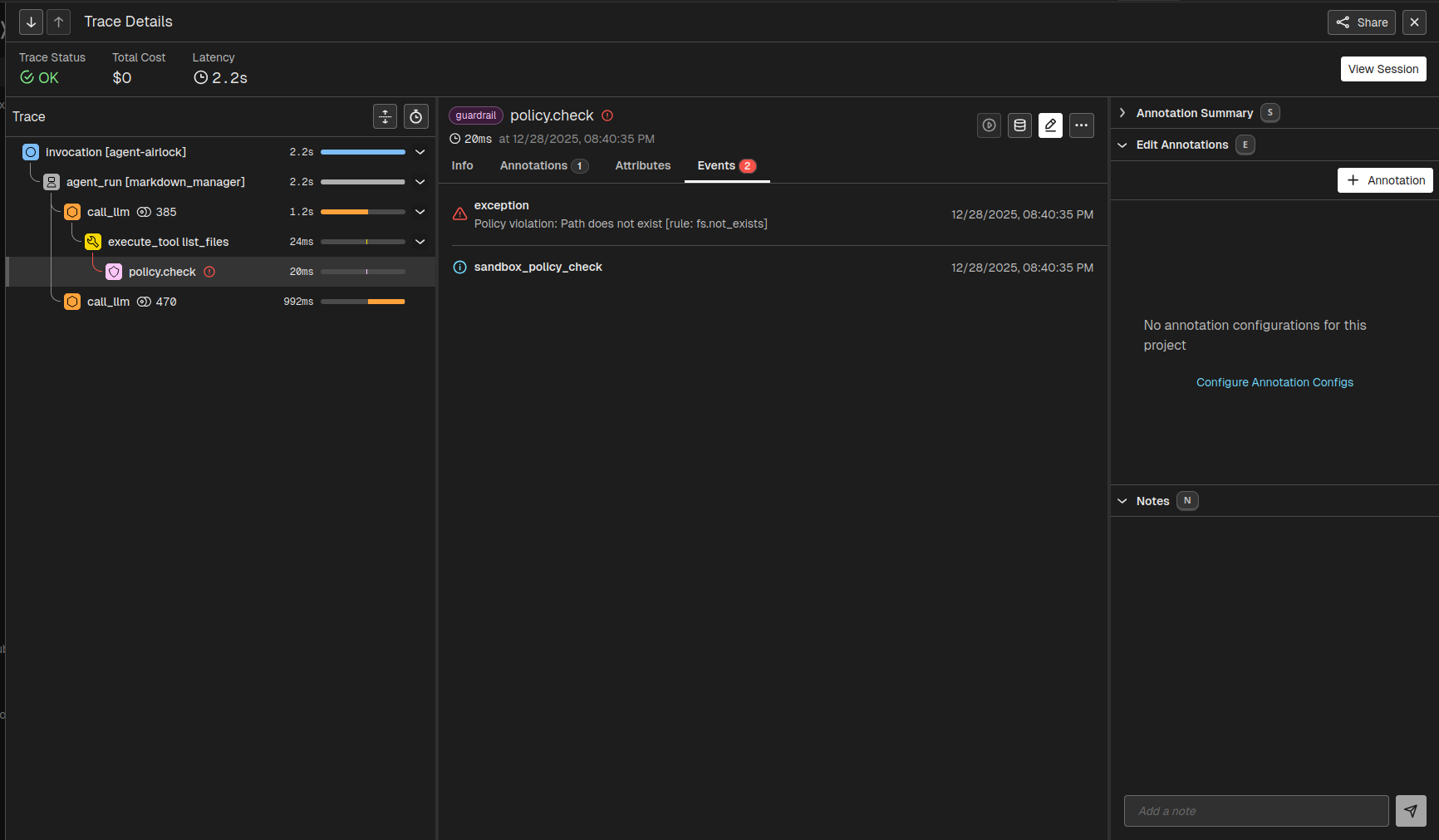
Clicking on a span reveals metadata and annotations. Important fields include:
sandbox.decision– allow/deny/escalatesandbox.rule_id– applied policysandbox.reason– explanationresolved_path– ensures safe file access
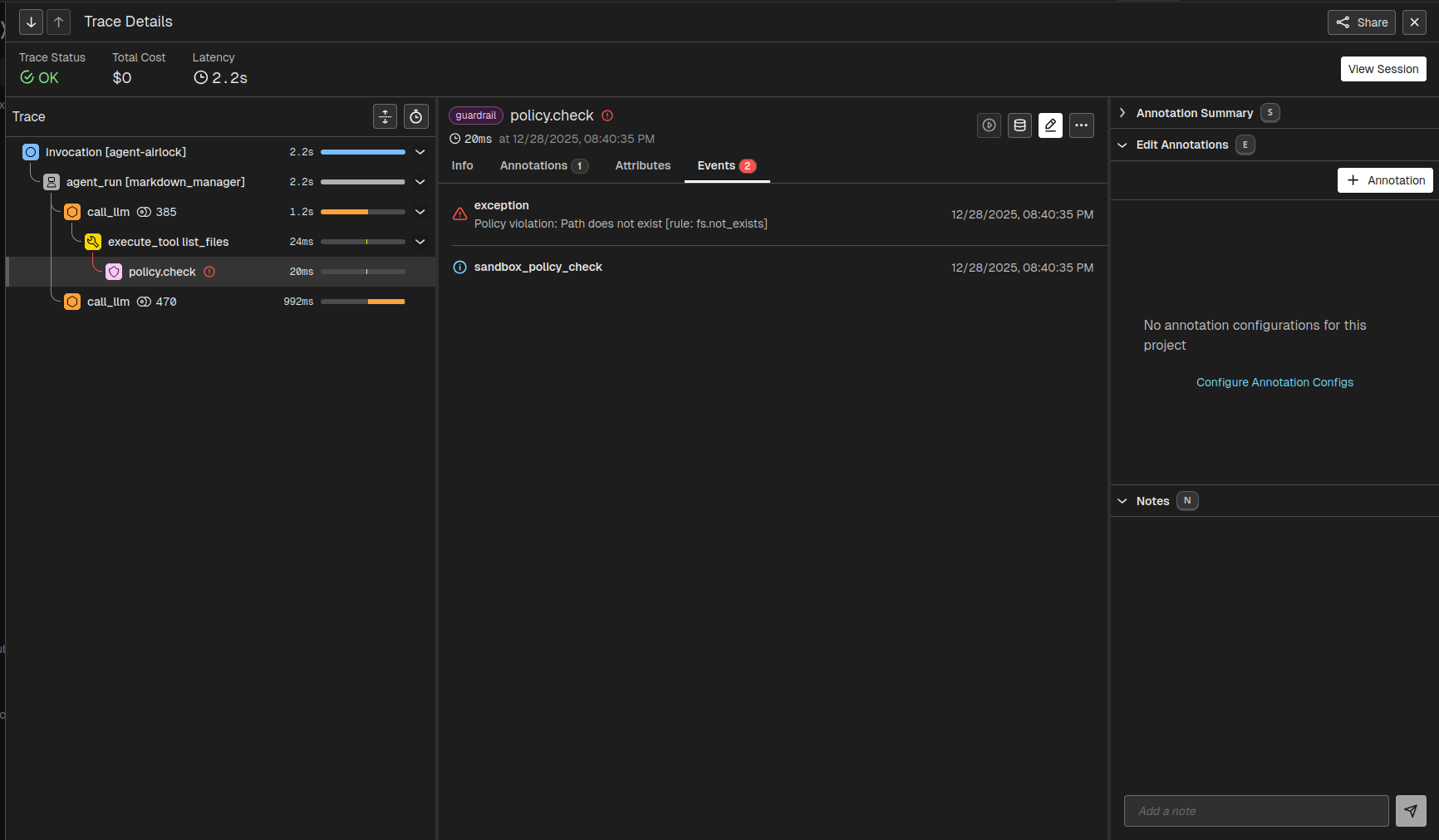
Each decision impacts the trace: allowed actions appear as completed tool invocation spans, while denied actions generate error objects and increment metrics such as sandbox.violation_count.
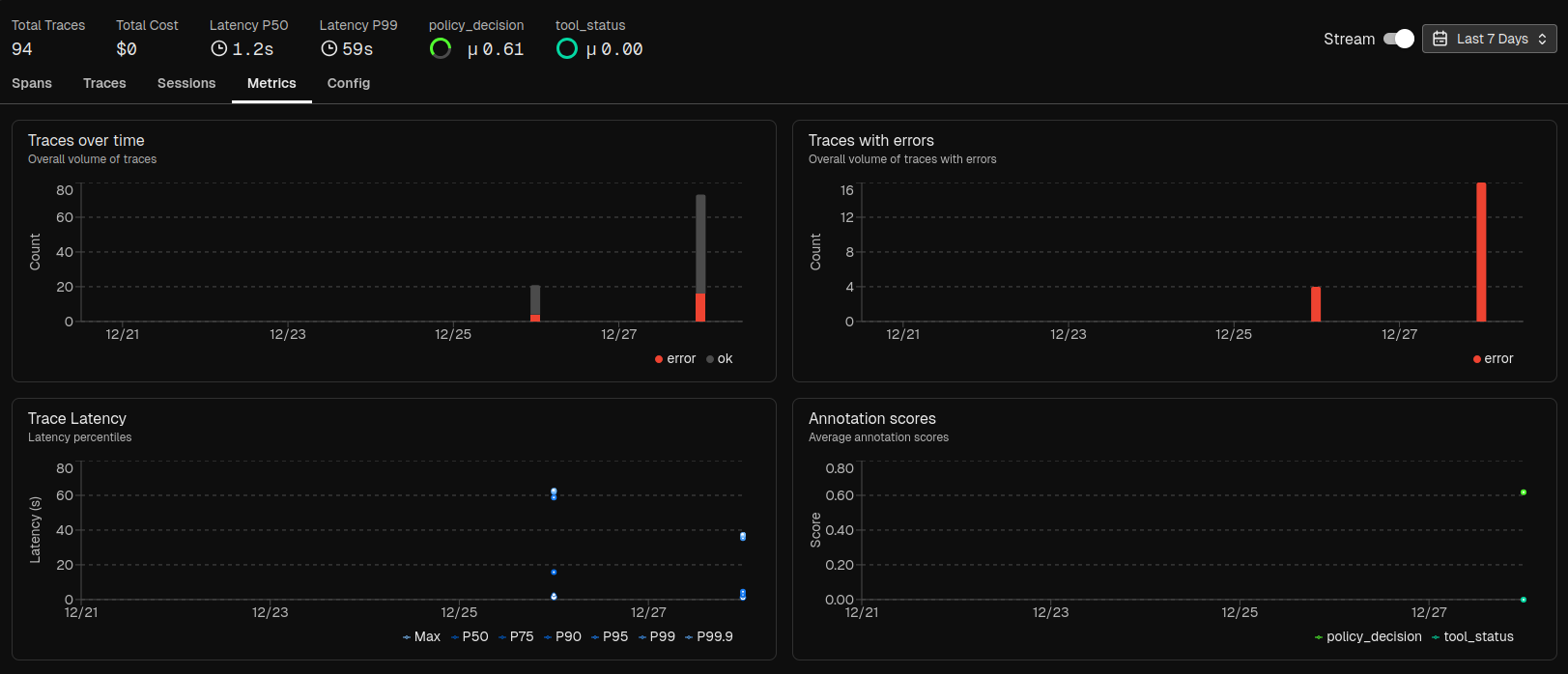
Repeated attempts indicate agent replanning after a denial. All denied or failed actions are captured in Phoenix metrics, where filtering by policy, decision, or session helps reveal patterns and identify which rules trigger most frequently.
Validating Sandbox Enforcement
To demonstrate that the sandbox enforces policies consistently, we tested a range of scenarios covering safe and unsafe actions. The results show that every denied action is captured as a trace event, while allowed actions proceed normally, ensuring both enforcement and observability.
| Test Scenario | What’s Tested | Expected Result |
test_allowed_read |
Read file within workspace | ✅ Allow |
test_blocked_read_outside |
Read file outside workspace | ❌ Deny |
test_blocked_write_outside |
Write operation (any location) | ❌ Deny |
test_network_blocked |
Network access attempt | ❌ Deny |
test_prompt_injection_block |
Prompt injection in arguments | ❌ Deny |
test_path_traversal_attack |
Path traversal with ../ | ❌ Deny |
test_directory_listing_outside |
List directory outside the workspace | ❌ Deny |
test_multi_step_bypass_attempt |
Read then exfil attempt | Partial deny (read allowed, exfil denied) |
The sandbox passes all these tests, showing deterministic enforcement across core attack vectors. Safe actions execute normally, while any unsafe operation is blocked and recorded in the trace.
Partial successes, such as reading a workspace file followed by a denied exfil attempt, are fully visible in the dashboard, providing a transparent, auditable record of agent behavior.
Conclusion
We’ve explored a framework for building safer, more auditable AI agents. Observability-driven sandboxing provides the visibility needed to understand agent behavior at every step, from planning and tool selection to policy enforcement and execution.
By combining deterministic policy enforcement with real-time tracing, agents can operate in complex environments without sacrificing control or safety.
Looking ahead, organizations and developers who adopt observability-first approaches will be best positioned to manage sophisticated, multi-tool agents reliably. Transparent tracing and auditable decisions while remaining fully observable.