



Recently, I attended a workshop organized by Arize AI titled “RAG Time! Evaluate RAG with LLM Evals and Benchmarking.” Hosted by Amber Roberts – ML Growth Lead at Arize AI, and Mikyo King – Head of Open Source at Arize AI, the talks provided valuable insights into an important field of study.
Miss the event? Here are some key learnings and takeaways along with a code-along exercise to get started that covers building a RAG pipeline using LlamaIndex all the way through to response evaluation leveraging Phoenix.
What Is Retrieval Augmented Generation (RAG)?
RAG (Retrieval-Augmented Generation) involves enhancing the output of a robust language model by leveraging an authoritative knowledge base beyond its original training data sources. This ensures that the model references external information to refine its responses during the generation process.
The diagram below shows how RAG works.

RAG enhances the existing robust features of LLMs to cater to specific domains or an organization’s internal knowledge repository, all without requiring model retraining. It offers a cost-efficient method to enhance LLM output, ensuring its relevance, accuracy, and utility across different scenarios.
Pros of RAG include enhancing LLM application performance through leveraging proprietary data and benefiting from ongoing advancements for improved results. Cons involve potential time-consuming troubleshooting in RAG workflows and the risk of multiple points of failure if the system is not adequately monitored.
What Are the Key Steps in Building RAG?
There are five key stages within RAG, which will be a part of any larger RAG application.
- Loading: This stage entails gathering data from diverse sources like text files, PDFs, websites, databases, or APIs and integrating it into your pipeline.
- Indexing: involves building a robust data structure in LLMs by generating vector embeddings, numeric data representations, and utilizing metadata strategies to improve contextual information retrieval accuracy.
- Storing: Storing the index and its metadata after initial indexing is crucial to prevent re-indexing and ensure efficient data retrieval.
- Querying: Utilizing a range of query methods, such as sub-queries, multi-step queries, and hybrid approaches, by integrating LLMs and data structures within the chosen indexing strategy.
- Evaluation: This is crucial in any pipeline as it measures the efficacy of your approach against alternatives or modifications, offering objective metrics on response accuracy and speed.
How To Build a RAG pipeline using LlamaIndex
With the understanding of how RAG works and the stages involved, we will build a RAG pipeline using LlamaIndex and use Phoenix Evals for large language model evaluation. You can check out the Google Colab here if you have your OpenAI keys, and you can use this demo.
Install libraries
!pip install -qq "arize-phoenix[experimental,llama-index]>=2.0"Import the installed libraries
import nest_asyncio
nest_asyncio.apply()
import os
from getpass import getpass
import pandas as pd
import phoenix as px
from llama_index import SimpleDirectoryReader, VectorStoreIndex, set_global_handler
from llama_index.llms import OpenAI
from llama_index.node_parser import SimpleNodeParserThe nest_asyncio module enables the nesting of asynchronous functions within an already running async loop. This is necessary because Jupyter notebooks inherently operate in an asynchronous loop. By applying nest_asyncio, we can run additional async functions within this existing loop without conflicts.
Launch the Phoenix application
Throughout this implementation, we will capture all the data we need to evaluate our RAG pipeline using Phoenix tracing. To enable this, simply start the phoenix application and instrument LlamaIndex.
px.launch_app()
set_global_handler("arize_phoenix")This runs a server on your browser with your own instance, and the set_global_handler(“arize_phoenix”) from LlamaIndex is used to set all information in the Arize Phoenix.
We will be using OpenAI for creating synthetic data as well as for evaluation.
if not (openai_api_key := os.getenv("OPENAI_API_KEY")):
openai_api_key = getpass("🔑 Enter your OpenAI API key: ")
os.environ["OPENAI_API_KEY"] = openai_api_keyDownload, load, and build an Index
Lets use an essay by Paul Graham to build our RAG pipeline.
!mkdir -p 'data/paul_graham/'
!curl 'https://raw.githubusercontent.com/Arize-ai/phoenix-assets/main/data/paul_graham/paul_graham_essay.txt' -o 'data/paul_graham/paul_graham_essay.txt'Using LlamaIndex we parse out the essay, build chunks of the documents with a chunk_size of 512 and embed them. We move on to store the local file as a VectorStoreIndex so we can perform queries.
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
# Define an LLM
llm = OpenAI(model="gpt-4")
# Build index with a chunk_size of 512
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
nodes = node_parser.get_nodes_from_documents(documents)
vector_index = VectorStoreIndex(nodes)Build a QueryEngine and start querying
query_engine = vector_index.as_query_engine()
response_vector = query_engine.query("What did the author do growing up?")
response_vector.responseWe can check the response that we get from the query and notice that it is tailored to the use case we are looking for.
‘The author wrote short stories and worked on programming, specifically on an IBM 1401 computer in 9th grade.’
Heading over to the Phoenix server, you will see the query and response, input and output. Phoenix also traces the internal state as well showing you the cosine similarity, document chunks, and metadata. But if you want to use LlamaIndex to retrieve the text in the first and second textnodes, you can use this code block.
# First retrieved node
response_vector.source_nodes[0].get_text()
# Second retrieved node
response_vector.source_nodes[1].get_text()We can access the traces by directly pulling the spans from the Phoenix session using the get_spans_dataframe() to see all the rich information we have collected in Phoenix in our local notebook.
spans_df = px.active_session().get_spans_dataframe()
spans_df[["name", "span_kind", "attributes.input.value", "attributes.retrieval.documents"]].head()You can narrow it down to the dataframe that have documents.
spans_with_docs_df = spans_df[spans_df["attributes.retrieval.documents"].notnull()]
spans_with_docs_df[["attributes.input.value", "attributes.retrieval.documents"]].head()With that, we built a RAG pipeline and instrumented it using Phoenix. We now need to evaluate RAG performance.
RAG Evaluation
Assessing your RAG application primarily relies on evaluation, serving as the key metric. It gauges the accuracy of responses generated by the pipeline, considering various data sources and query types.
While analyzing individual queries and responses is valuable, it becomes challenging with a growing number of edge cases and failures. A more practical approach involves implementing a suite of metrics and automated evaluations. These tools offer insights into the overall performance of the system and pinpoint areas needing further examination.
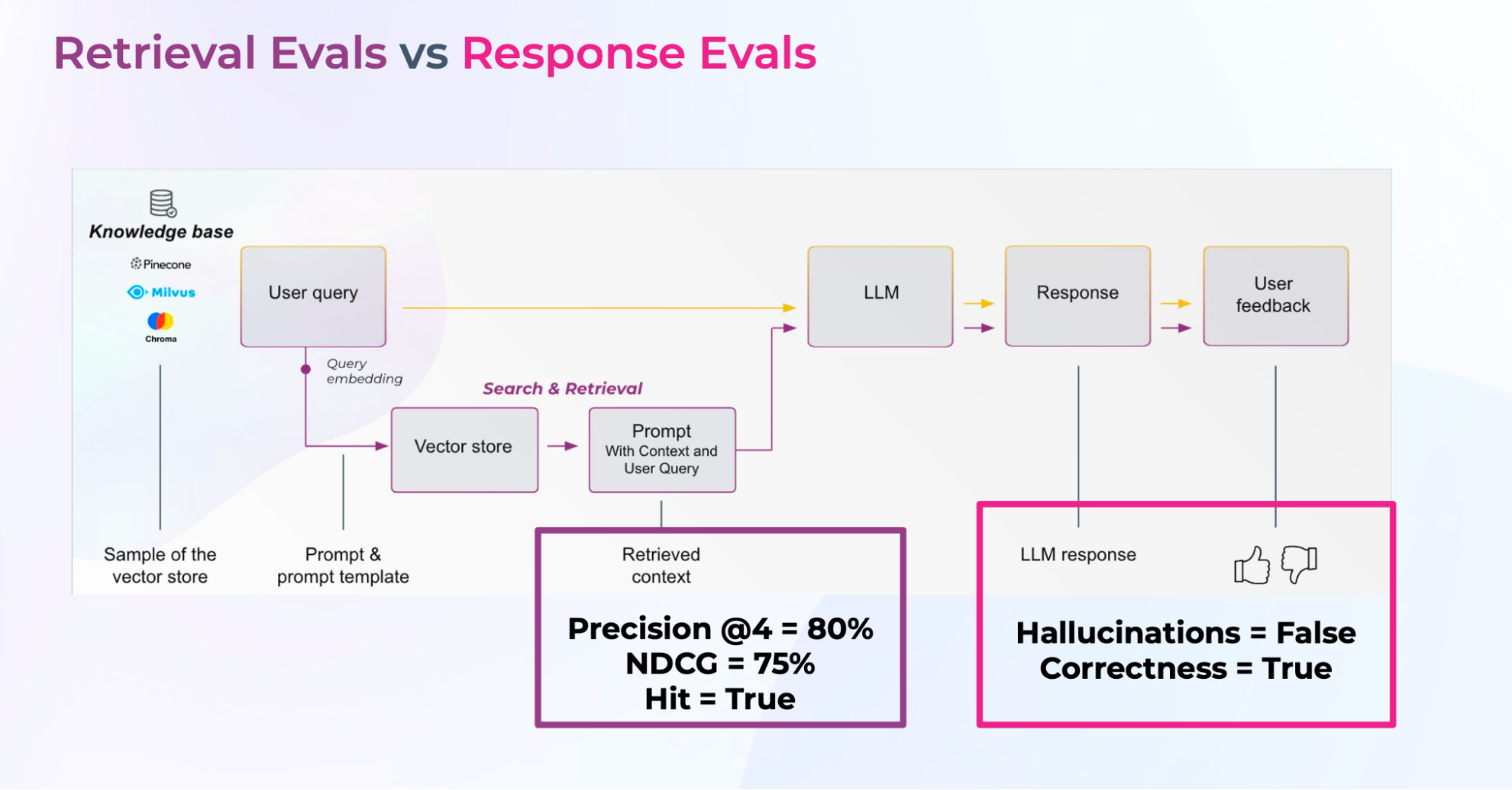
RAG system evaluation focuses on two critical aspects.
Retrieval Evaluation
To assess the accuracy and relevance of the documents that were retrieved.
- nDCG: To measure the effectiveness of your top-ranked documents. Takes into account the position of relevant docs.
- Hit Rate: percentage of queries that have relevant context. Hit is a binary metric (relevant document was or wasn’t retrieved).
- Precision @K: Precision = percentage of relevant documents, up to ‘K’ retrieved documents. Precision@3 = 33%, if 1 out of 3 docs is relevant.
Response Evaluation
Measure the appropriateness of the response generated by the system when the context was provided. If LLMs do not have ground-truth labels evaluation can be done using the following response evaluation criteria:
- QA Correctness: whether a question was correctly answered by the system based on the retrieved data.
- Hallucinations: detect LLM hallucinations relative to retrieved context.
- Toxicity: identify if the AI response is racist, biased, or toxic
Generate question context pairs
For the evaluation of a RAG system, it’s essential to have queries that can fetch the correct context and subsequently generate an appropriate response. We will make use of Phoenix llm_generate to create question-context pairs.
# Let's construct a dataframe of just the documents that are in our index
document_chunks_df = pd.DataFrame({"text": [node.get_text() for node in nodes]})
document_chunks_df.head()Now that we have the document chunks, let’s prompt an LLM to generate three questions per chunk.
generate_questions_template = """\
Context information is below.
---------------------
{text}
---------------------
Given the context information and not prior knowledge.
generate only questions based on the below query.
You are a Teacher/ Professor. Your task is to setup \
3 questions for an upcoming \
quiz/examination. The questions should be diverse in nature \
across the document. Restrict the questions to the \
context information provided."
Output the questions in JSON format with the keys question_1, question_2, question_3.
"""
import json
from phoenix.experimental.evals import OpenAIModel, llm_generate
def output_parser(response: str, index: int):
try:
return json.loads(response)
except json.JSONDecodeError as e:
return {"__error__": str(e)}
questions_df = llm_generate(
dataframe=document_chunks_df,
template=generate_questions_template,
model=OpenAIModel(
model_name="gpt-3.5-turbo",
),
output_parser=output_parser,
concurrency=20,
)
questions_df.head()Next, construct a dataframe of the questions and the document chunks, then stack these questions together with the context.
questions_with_document_chunk_df = pd.concat([questions_df, document_chunks_df], axis=1)
questions_with_document_chunk_df = questions_with_document_chunk_df.melt(
id_vars=["text"], value_name="question"
).drop("variable", axis=1)
# If the above step was interrupted, there might be questions missing. Let's run this to clean up the dataframe.
questions_with_document_chunk_df = questions_with_document_chunk_df[
questions_with_document_chunk_df["question"].notnull()
]
questions_with_document_chunk_df.head(10)Retrieval Evaluation
We will execute the queries we generated in the previous step and verify whether or not the correct context is retrieved. But first, loop over the questions and generate the answers
for _, row in questions_with_document_chunk_df.iterrows():
question = row["question"]
response_vector = query_engine.query(question)
print(f"Question: {question}\nAnswer: {response_vector.response}\n")Now that we have executed the queries, we can start validating whether or not the RAG system was able to retrieve the correct context. Let’s extract all the retrieved documents from the traces logged to Phoenix using the get_retrieved_documents()
from phoenix.session.evaluation import get_retrieved_documents
retrieved_documents_df = get_retrieved_documents(px.active_session())
retrieved_documents_dfSo let’s run a relevance evaluation using Phoenix LLM evals, we want to know if the chunk of the document is relevant to the question the user asked. We turned on explanations which prompts the LLM to explain its reasoning. This can be useful for debugging and for figuring out potential corrective actions.
from phoenix.experimental.evals import (
RelevanceEvaluator,
run_evals,
)
relevance_evaluator = RelevanceEvaluator(OpenAIModel(model_name="gpt-4-turbo-preview"))
retrieved_documents_relevance_df = run_evals(
evaluators=[relevance_evaluator],
dataframe=retrieved_documents_df,
provide_explanation=True,
concurrency=20,
)[0]
retrieved_documents_relevance_df.head()We can now combine the documents with the relevance evaluations to compute retrieval metrics, helping us to understand how the well the RAG system is performing.
documents_with_relevance_df = pd.concat(
[retrieved_documents_df, retrieved_documents_relevance_df.add_prefix("eval_")], axis=1
)
documents_with_relevance_dfCompute NCDG
Let’s compute the Normalized Discounted Cumulative Gain (NCDG) at two for all of our retrieval steps. In information retrieval, this metric is often used to measure the effectiveness of search engine algorithms and related applications.
import numpy as np
from sklearn.metrics import ndcg_score
def _compute_ndcg(df: pd.DataFrame, k: int):
"""Compute NDCG@k in the presence of missing values"""
n = max(2, len(df))
eval_scores = np.zeros(n)
doc_scores = np.zeros(n)
eval_scores[: len(df)] = df.eval_score
doc_scores[: len(df)] = df.document_score
try:
return ndcg_score([eval_scores], [doc_scores], k=k)
except ValueError:
return np.nan
ndcg_at_2 = pd.DataFrame(
{"score": documents_with_relevance_df.groupby("context.span_id").apply(_compute_ndcg, k=2)}
)
ndcg_at_2Compute precision
Let’s also compute precision at 2 for all our retrieval steps.
precision_at_2 = pd.DataFrame(
{
"score": documents_with_relevance_df.groupby("context.span_id").apply(
lambda x: x.eval_score[:2].sum(skipna=False) / 2
)
}
)
precision_at_2Compute hit
Lastly, let’s compute whether or not a correct document was retrieved at all for each query (e.g. a hit)
hit = pd.DataFrame(
{
"hit": documents_with_relevance_df.groupby("context.span_id").apply(
lambda x: x.eval_score[:2].sum(skipna=False) > 0
)
}
)Let’s now view the results in a combined dataframe.
retrievals_df = px.active_session().get_spans_dataframe("span_kind == 'RETRIEVER'")
rag_evaluation_dataframe = pd.concat(
[
retrievals_df["attributes.input.value"],
ndcg_at_2.add_prefix("ncdg@2_"),
precision_at_2.add_prefix("precision@2_"),
hit,
],
axis=1,
)
rag_evaluation_dataframeAggregate the scores
Let’s now take our results and aggregate them to get a sense of how well our RAG system is performing.
results = rag_evaluation_dataframe.mean(numeric_only=True)
results
=======
ncdg@2_score 0.913450
precision@2_score 0.804598
hit 0.936782
dtype: float64
=====
Log evaluations to Phoenix
From the above numbers, our RAG system is not perfect, there are times when it fails to retrieve the correct context within the first two documents. At other times the correct context is included in the top 2 results but non-relevant information is also included in the context. This is an indication that we need to improve our retrieval strategy.
One possible solution could be to increase the number of documents retrieved and then use a more sophisticated ranking strategy (such as a reranker) to select the correct context. We have now evaluated our RAG system’s retrieval performance. Let’s log these evaluations to Phoenix for visualization.
from phoenix.trace import DocumentEvaluations, SpanEvaluations
px.Client().log_evaluations(
SpanEvaluations(dataframe=ndcg_at_2, eval_name="ndcg@2"),
SpanEvaluations(dataframe=precision_at_2, eval_name="precision@2"),
DocumentEvaluations(dataframe=retrieved_documents_relevance_df, eval_name="relevance"),
)Response Evaluation
The retrieval evaluations demonstrate that our RAG system is not perfect. However, the LLM may be able to generate the correct response even when the context is incorrect. Let’s evaluate the responses generated by the LLM.
from phoenix.session.evaluation import get_qa_with_reference
qa_with_reference_df = get_qa_with_reference(px.active_session())
qa_with_reference_dfNow that we have a dataset of the question, context, and response, we now can measure how well the LLM is responding to the queries. For details on the QA correctness evaluation, see the LLM Evals documentation.
from phoenix.experimental.evals import (
HallucinationEvaluator,
OpenAIModel,
QAEvaluator,
run_evals,
)
qa_evaluator = QAEvaluator(OpenAIModel(model_name="gpt-4-turbo-preview"))
hallucination_evaluator = HallucinationEvaluator(OpenAIModel(model_name="gpt-4-turbo-preview"))
qa_correctness_eval_df, hallucination_eval_df = run_evals(
evaluators=[qa_evaluator, hallucination_evaluator],
dataframe=qa_with_reference_df,
provide_explanation=True,
concurrency=20,
)
qa_correctness_eval_df.head()
hallucination_eval_df.head()Aggregate the scores
Let’s now take our results and aggregate them to get a sense of how well the LLM is answering the questions given the context.
qa_correctness_eval_df.mean(numeric_only=True)
hallucination_eval_df.mean(numeric_only=True)Our QA Correctness score of 0.91 and a Hallucinations score 0.05 signifies that the generated answers are correct ~91% of the time and that the responses contain hallucinations 5% of the time.
Log evaluations to Phoenix
Since we have evaluated our RAG system’s QA performance and hallucinations performance, let’s send these evaluations to Phoenix for visualization.
from phoenix.trace import SpanEvaluations
px.Client().log_evaluations(
SpanEvaluations(dataframe=qa_correctness_eval_df, eval_name="Q&A Correctness"),
SpanEvaluations(dataframe=hallucination_eval_df, eval_name="Hallucination"),
)Conclusion
In this piece, we explained how to build and evaluate a RAG pipeline using LlamaIndex and the open-source offering Phoenix with a specific focus on evaluating the retrieval system and the generated responses within the pipeline. For more details, see the LLM Evals documentation. Comments or questions? Feel free to reach out in the Arize Community.