Enterprises are moving AI applications into production faster than ever and the operational reality on the other side looks very different from a prototype. Application teams need to ship and iterate quickly. Platform and quality teams need to know what every model call did and why and whether the output stayed within the quality bar the business expects. The harder question is this: how do you trace and evaluate and monitor hundreds of model calls across multiple providers and multiple agent frameworks without embedding a vendor SDK inside every service?
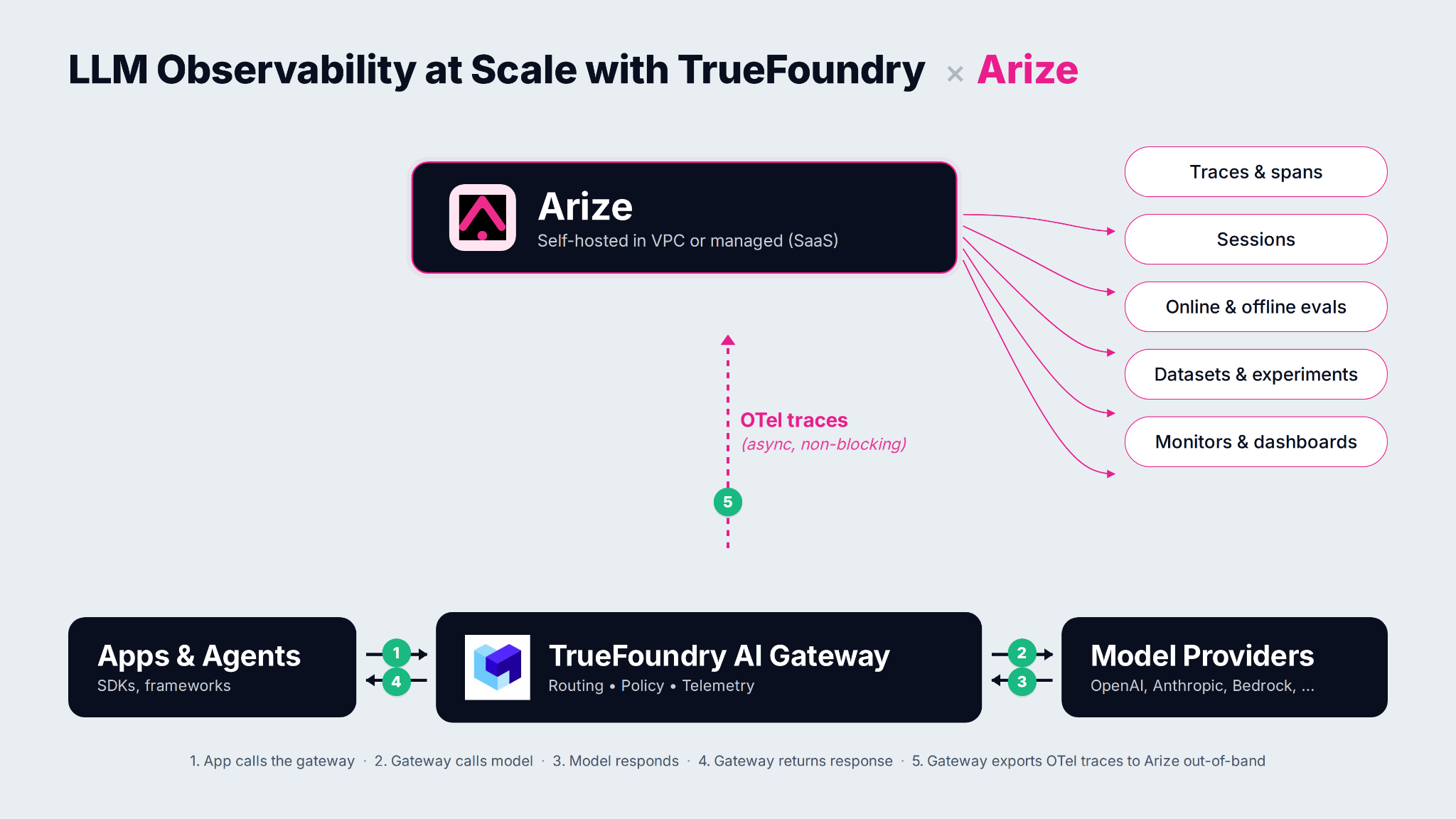
At TrueFoundry our approach is to keep the execution layer uniform and let teams plug in the observability and evaluation system they already use. That is why we are announcing a native integration between the TrueFoundry AI Gateway and Arize. The gateway becomes the single execution boundary that every model call and every agent step passes through and Arize becomes the system of record where those calls turn into OpenInference traces and online evaluations and production monitors the team can act on.
Introducing TrueFoundry AI Gateway
The TrueFoundry AI Gateway establishes a single governed entry point for all model and agent requests. Applications and agents no longer talk directly to model providers. They talk to the gateway proxy. This architectural decision matters because it creates a consistent surface for policy enforcement and routing decisions and telemetry generation. The gateway determines which model is used and under what constraints and in which environment and with what safeguards. It also becomes the one place where production behavior can be observed comprehensively.
For platform leaders this is the point where AI systems stop being a collection of python scripts and start behaving like infrastructure.
Introducing Arize
While the gateway governs where and how requests execute, Arize is the place you go to reconstruct what actually happened as structured trace data rather than scattered logs. In Arize’s terminology a trace captures the end-to-end sequence of spans for a single request and each span is a discrete unit of work such as an LLM call and a retriever step and a tool invocation and any other operation you want visibility into. Spans are organized into projects which are containers for everything related to a given application or service. Multi-turn conversations can be linked as sessions so you can inspect behavior across an entire dialogue rather than one isolated request. Read here if you want to dive deeper: Arize OpenInference tracing concepts.
Arize treats evaluation as a first-class concept and lets you attach scores and labels to spans whether that feedback comes from humans or automated LLM-as-a-Judge evaluators or online evaluators running on production traffic. This is what makes it more than monitoring. It supports an evaluation loop where you run offline evaluations on curated datasets before shipping and online evaluations on real user interactions in production to detect regressions and track quality in real time.
This is how traces from the TrueFoundry AI Gateway appear in the Arize UI. Each model call shows up as its own span with the operation type and latency captured at the gateway level.
How TrueFoundry and Arize work together
Most enterprises already operate a centralized observability stack that anchors their incident response and SRE practice. The challenge with LLM systems is that the telemetry generated by model calls (prompts and completions and token usage and cache hits and guardrail decisions and agent step graphs) does not map cleanly onto the metrics and traces those tools were originally designed for. Teams typically end up choosing between two unsatisfactory options:
- Instrument every application with an LLM specific SDK
- Ship traces into the existing stack while losing span semantics and sessions and evaluations
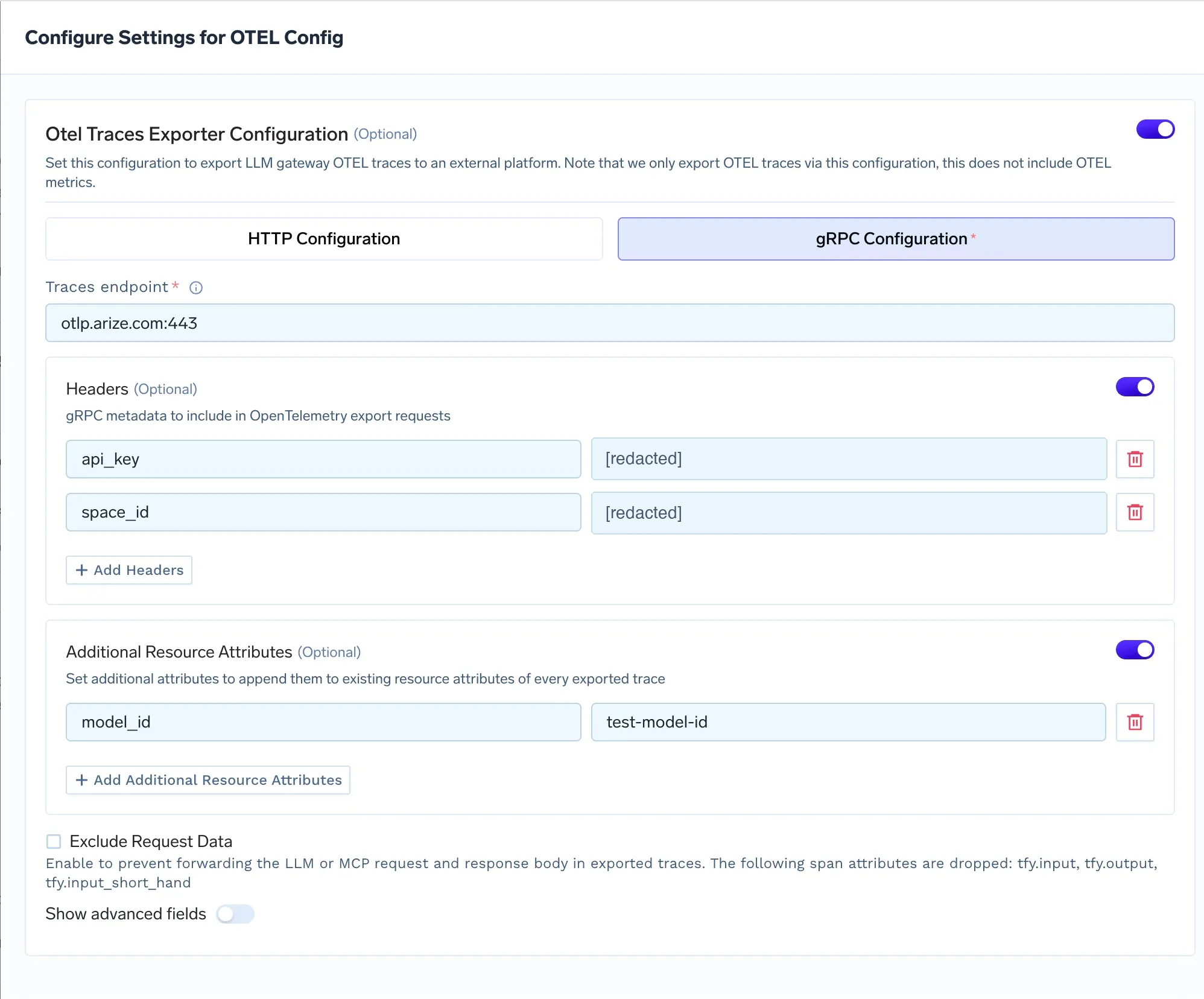
On the TrueFoundry side you enable the AI Gateway’s OpenTelemetry traces exporter. The gateway remains responsible for generating and storing traces that you can view inside the TrueFoundry Monitor UI and exporting those traces is an additive operation that does not change TrueFoundry’s own storage behavior. Check OTel export docs here: TrueFoundry.
On the Arize side you provide an API key and a space ID for authentication and (optionally) a project name so traces land in a predictable project rather than the default. Arize’s OpenTelemetry guide documents the OTLP headers used for authentication and project routing. Docs: Arize.
Conclusion
For AI leaders the TrueFoundry and Arize integration provides a shared foundation where execution and observability and evaluation stay aligned as systems scale. It lets teams manage LLM applications with the same rigor as distributed services and meet enterprise requirements without slowing development because production AI needs production-grade infrastructure.
The partnership is intentionally composable. TrueFoundry governs and routes execution and Arize records and evaluates behavior and OpenTelemetry connects them. Together they function as a practical control plane that moves organizations from promising demos to dependable AI in production.
Appendix
How the Gateway Generates Traces
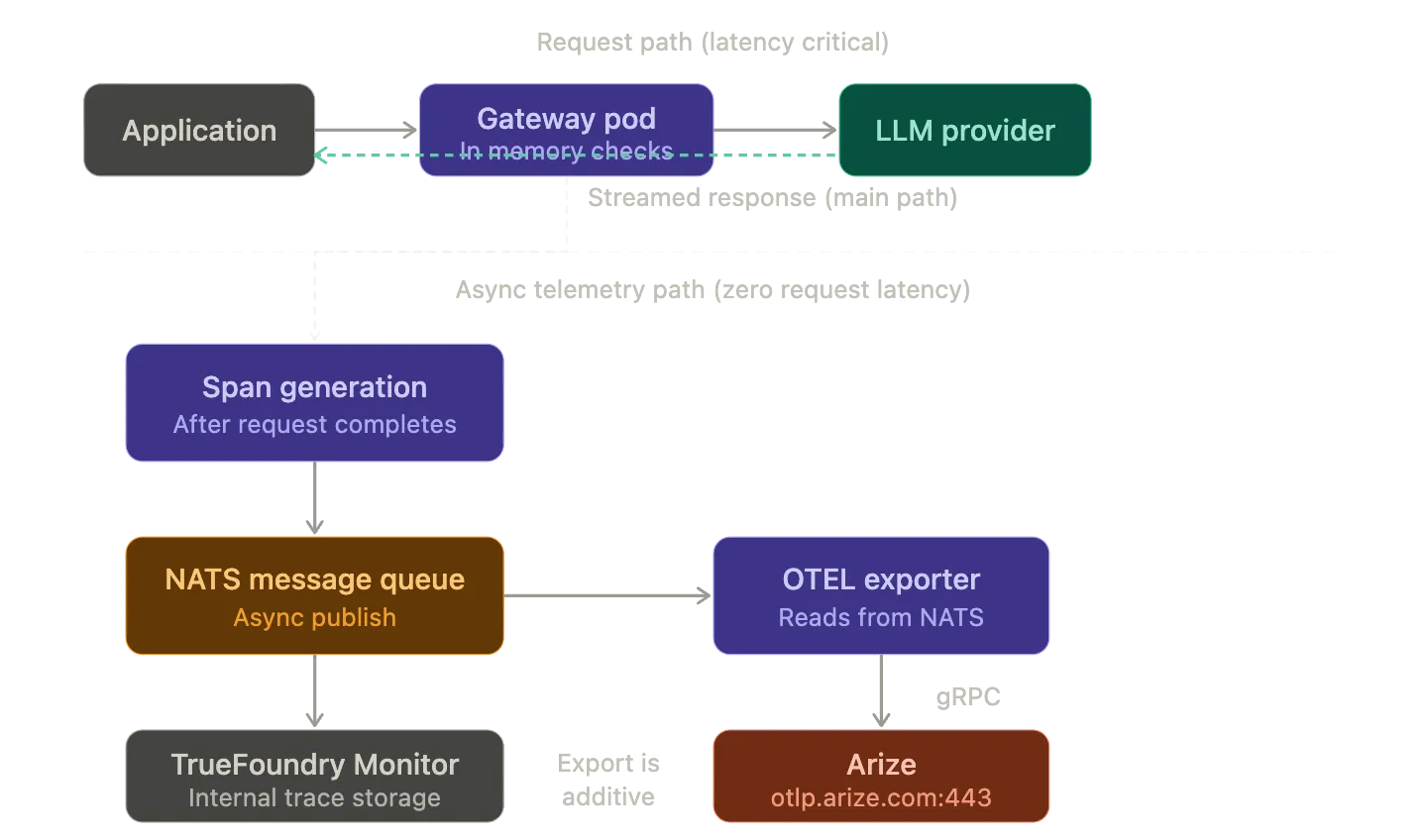
Trace generation happens asynchronously alongside the request flow. The gateway creates OTel spans for each stage of the request lifecycle: the inbound HTTP handler and the authentication check and the model resolution and the outbound provider call and the streaming response. These spans carry attributes that capture token usage and latency and model name and provider and cost estimate and request metadata. After the request completes the gateway publishes the trace data to a NATS message queue.
The OTel exporter picks up trace data from this async path and forwards it to the configured external endpoint. Because trace export is decoupled from the request path it adds zero latency to inference requests. The gateway never fails a request even if the external OTel endpoint is unreachable.
What Arize Does with the Traces
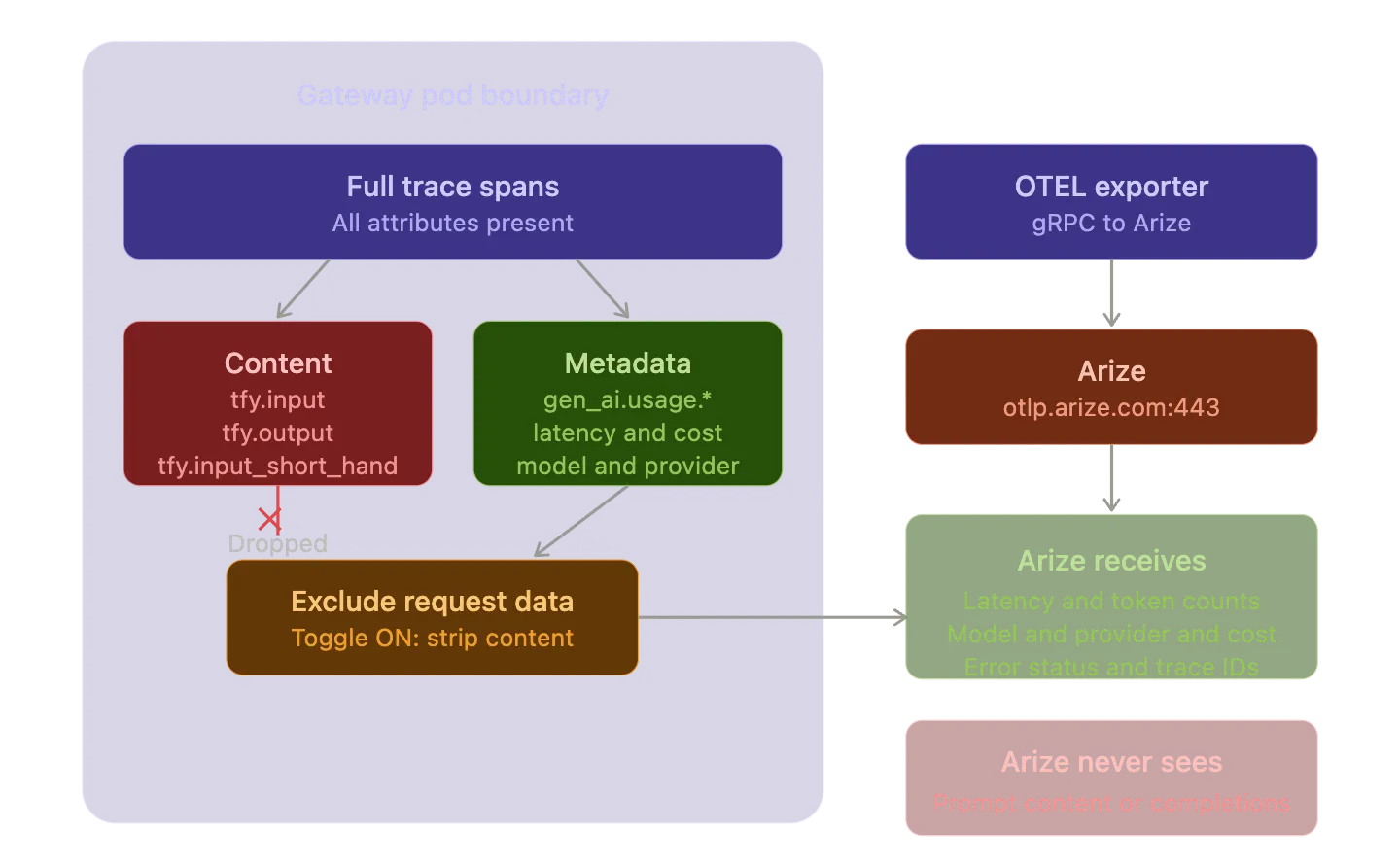
Arize ingests OTel traces over gRPC at otlp.arize.com:443 and recognizes OpenInference attributes natively. On top of the trace stream sit waterfall views and aggregate performance analytics (latency distributions by model and by provider and error rates and throughput) and an evaluation layer that runs LLM-as-a-Judge workflows and human annotation against the same spans. Token counts and model identifiers and prompt content are parsed out and surfaced in LLM-aware views rather than rendered as generic string key value pairs.
The Integration Surface
The integration is a direct gRPC export from the gateway to Arize. No collector sidecar is needed. No custom SDK is involved. You configure the OTel exporter in the TrueFoundry dashboard and traces start flowing.
You can follow the integration steps here: TrueFoundry Arize docs.