
Google Colab
colab.research.google.com
- Reasoning — did the agent reason coherently toward the goal, or get there by luck?
- Tool selection — did it pick the right tools (and skip the wrong ones)?
- Decision path — did it call those tools in a sensible order, with sensible arguments?
- Reconstructing an agent’s decision path (
tool_path) and tool I/O (tool_io) from its spans - Running an endpoint check (recommendation relevance) alongside two intermediate checks (decision path and reasoning/support)
- Seeing each evaluator catch a distinct failure the endpoint check misses
- Logging trace-level evaluations back to Phoenix
Notebook Walkthrough
We will go through key code snippets on this page. To follow the full tutorial, check out the full notebook. After configuring tracing withphoenix.otel.register(...) and building a movie recommendation agent with three tools (movie_selector_llm, reviewer_llm, preview_summarizer_llm), run it against a handful of questions to generate traces, then pull the spans with px_client.spans.get_spans_dataframe(...) into primary_df. See the notebook for the full agent and tool definitions.
Separate the endpoints from the trace
First pull the endpoints — the user’s question and the agent’s final answer. Take the final answer only, not a concatenation of every span’s output: folding in tool outputs would blur the line between “what the user saw” and “what happened inside the trace.”With the OpenAI Agents instrumentation, the root
AGENT span doesn’t record input.value / output.value — those attributes live on the underlying LLM spans, so we read the question and final reply from there with two small helpers. With an instrumentation that populates the root span, you could read input.value / output.value off the agent root directly.Reconstruct the intermediate signals
To evaluate the agent’s process, reconstruct two signals the endpoints never show, both from the trace’sTOOL spans (sorted by start_time):
tool_path— the ordered tool calls the agent made, with their arguments. This is the decision path: tool selection, order, and the arguments each tool was called with.tool_io— what each tool was called with and what it returned, so an evaluator can check whether the final answer is grounded in real tool results.
Define the three evaluators
Each evaluator reads a different column and answers a different question:- Relevance — an endpoint check on
input+output(exactly what end-to-end eval does). - Decision path — an intermediate check on
input+tool_path(right tools, right order, sensible arguments?). - Reasoning / support — an intermediate check on
input+tool_io+output(is the answer grounded in the actual tool results, or does it invent facts no tool produced?).
suppress_tracing() so the judges’ own LLM calls don’t get traced into the same project, then log the results back onto each trace’s root span:
Seeing what each evaluator catches
On well-behaved traces the three evaluators agree. The point of trace-level evaluation is what happens when they don’t. Running the three judges on controlled cases that mirror the real schema — each with a relevant-looking answer, so the endpoint check passes every time — shows each intermediate check catching a distinct failure:
Two intermediate failures, two different lenses — and both invisible to the endpoint check.
After logging the evaluations, each trace’s root span carries all three labels in Phoenix:
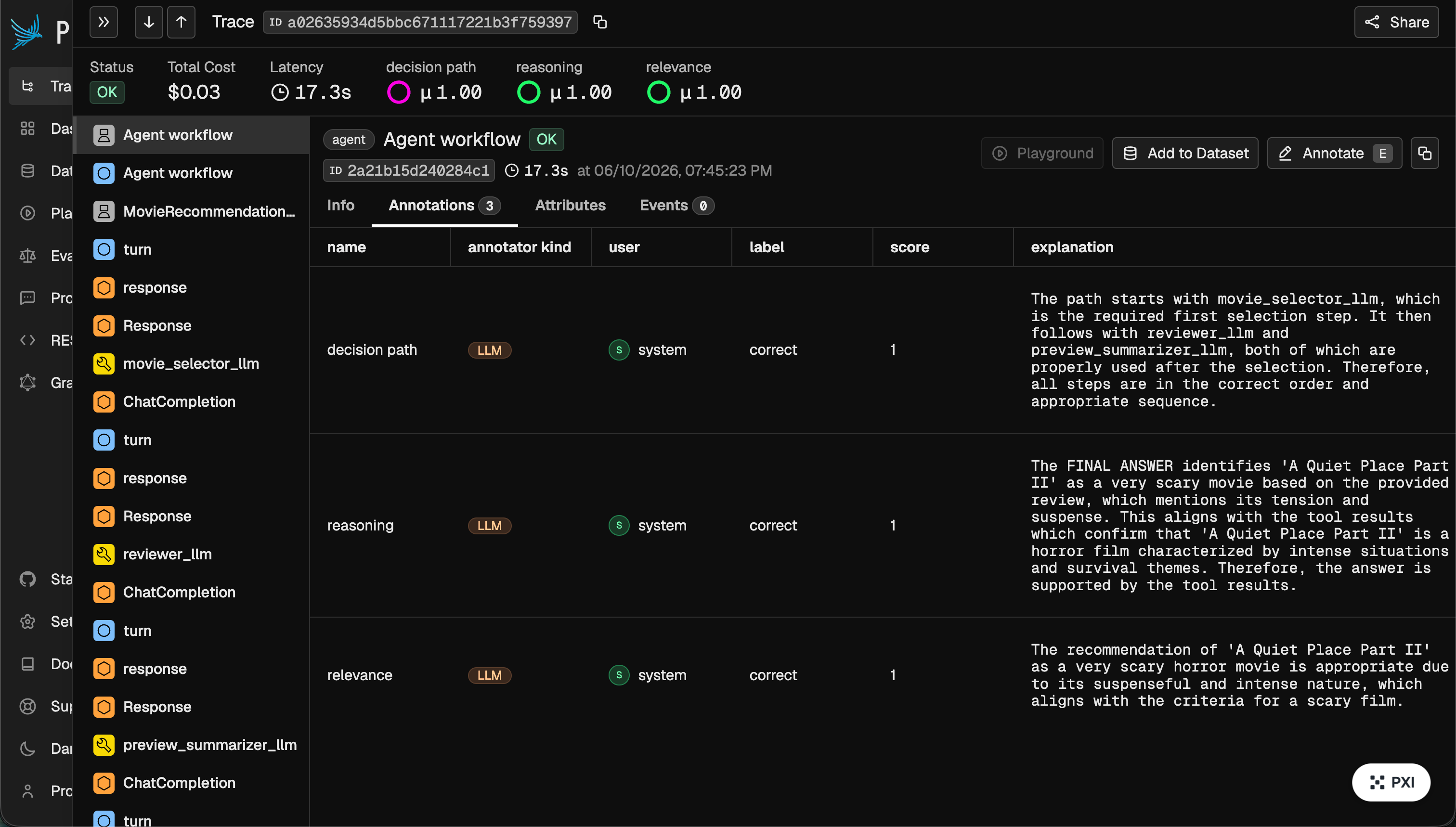
Takeaway
We ran three evaluators over the same traces, each asking a different question and reading a different signal:- relevance (endpoint) — did the final answer look right? Reads only
inputandoutput. - decision path (intermediate) — did the agent pick the right tools, in the right order, with sensible arguments? Reads
tool_path. - reasoning / support (intermediate) — is the answer grounded in what the tools returned? Reads
tool_io.