The three-step pattern
Offline evaluation always follows the same shape: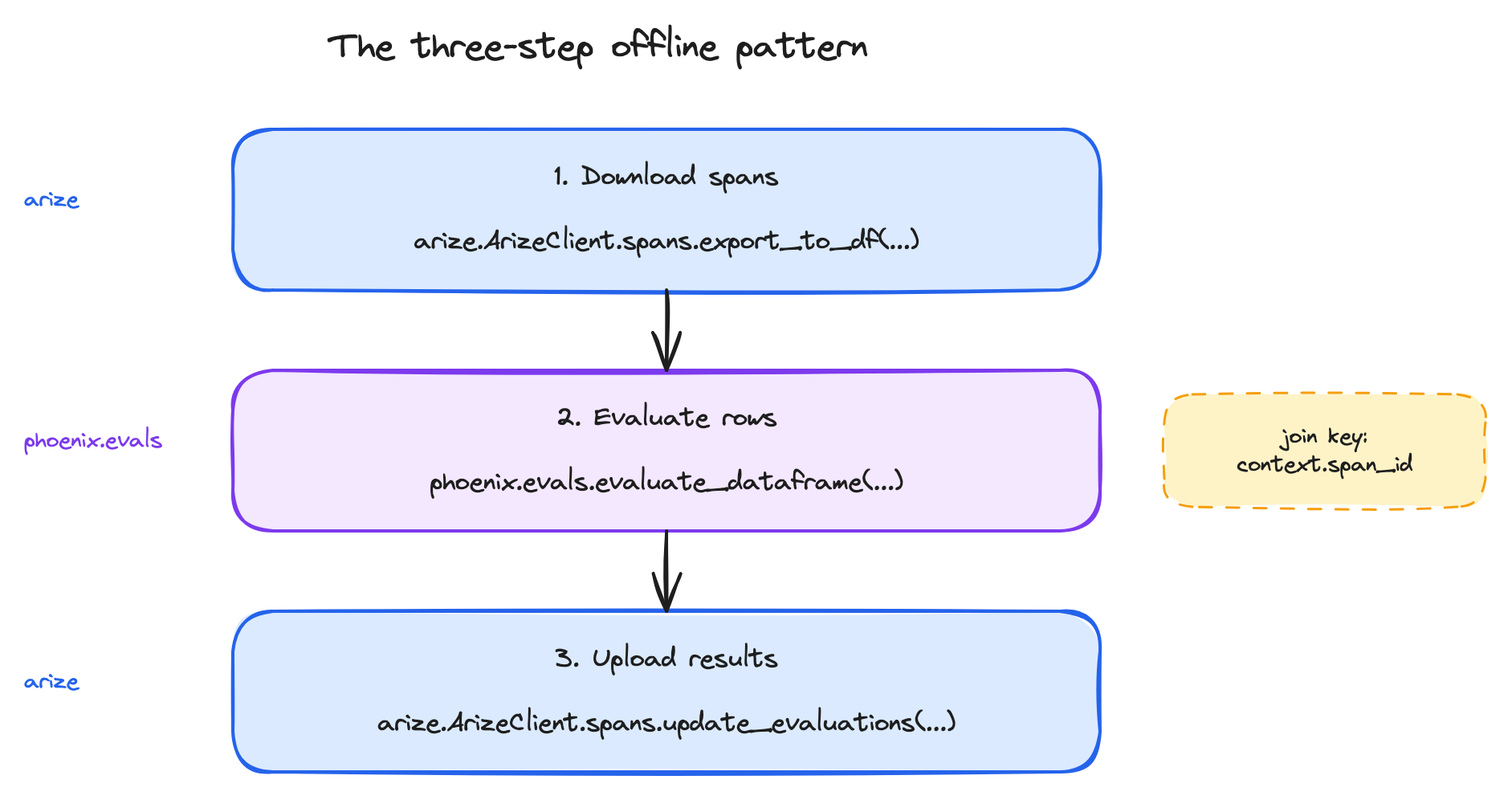
The three-step offline pattern: download spans with arize, evaluate with phoenix.evals, upload back with arize — joined by context.span_id.
Phoenix here is a library, not a separate service. Using
phoenix.evals doesn’t require running a Phoenix server. It’s installed alongside arize and called from your offline script.
Step 1: download the spans
The download step pulls a dataframe of spans from Arize AX into memory. The shape:start_time,end_time— the time window to pull. Required.where— a SQL-like filter expression, the same syntax used in the Spans tab filter bar.columns— restrict the columns returned. Optional, but worth using for two reasons: smaller payloads, and you can drop attributes you don’t need.context.span_idmust be in the columns list. Every OpenTelemetry span has a unique span ID —context.span_idis the join key for step 3, so without it you can’t write results back.
Step 2: evaluate the rows
The evaluation step takes the span dataframe and returns it augmented with evaluator scores. The modern Phoenix eval primitives are class-based — you construct an evaluator, then apply it to a dataframe.LLM(provider=..., model=...)wraps the judge — provider-agnostic, so the same code targets OpenAI, Anthropic, Bedrock, or Vertex AI by changing theproviderstring.create_classifier(...)builds aClassificationEvaluatorobject.choicesis a dict that maps each label to its numeric score;directiontells Arize AX whether higher is better.evaluate_dataframe(...)takes a list of evaluators. To run several scores against the same span batch in one pass, pass them all in the list.- For larger batches,
async_evaluate_dataframe(dataframe, evaluators, concurrency=N)is the async equivalent and significantly faster.
The output shape — flatten before uploading
evaluate_dataframe returns the original dataframe with two new columns per evaluator: <name>_score (a dict containing label, score, explanation, metadata) and <name>_execution_details (status, exceptions, timing). The dict structure is convenient for analysis but not directly uploadable to Arize AX, which expects flat columns. The shape Arize AX expects:
correctness with the evaluator’s name.
Step 3: upload back to Arize AX
The upload step writes the results to the originating spans, joining oncontext.span_id. The shape:
context.span_id column — that’s the only way Arize AX knows which span each result belongs to. The name column becomes the eval.<name>.* prefix on the resulting span attributes; once uploaded, eval.correctness.label, eval.correctness.score, and eval.correctness.explanation are visible in the Arize AX UI just like any other span attribute.
Two transport details worth knowing at the concept level:
- Transport is Arrow Flight (gRPC) by default. Environments that can’t reach Flight (some corporate firewalls, service meshes) can fall back to HTTP via
force_http=True. - The upload validates the dataframe shape before sending. Required columns, types, and join-key presence are checked client-side.
validate=Falseexists for fast batch uploads but is rarely the right default.
The role of EvaluationResult
arize.experiments.EvaluationResult is the canonical Python data class for an evaluator result. Its fields are exactly what an evaluator emits:
EvaluationResult objects by hand in the simple classifier flow above — the result dataframe already contains the same fields. But if you’re writing a custom Python evaluator (subclassing phoenix.evals.LLMEvaluator or arize.experiments.Evaluator), the evaluate() method returns an EvaluationResult. The fields are the same: label, score, explanation, optional metadata.
When the offline path is worth the work
Offline evaluation costs you orchestration — you write the loop, manage the schedule, handle the failures. In exchange, you get:- Multi-stage pipelines. One evaluator’s output feeds another. Cheap pre-filter → expensive LLM-as-a-judge on what passes.
- Parallel evaluators in one batch.
evaluate_dataframe(dataframe, evaluators=[a, b, c, d])runs four scores against the same span batch in one pass. - Custom data shaping. Join span attributes, compute derived fields, look up reference values from a separate source — anything pandas can do.
- Non-platform models. Local Ollama, internal model APIs, or any provider with an OpenAI-compatible interface.
- CI integration. The same script runs in production batch jobs and in your build pipeline against test datasets.
A note on the Arize AX-native eval framework
For completeness: Arize AX has its own native eval primitives inarize.experiments — Evaluator, LLMEvaluator, CodeEvaluator, run_experiment, evaluate_experiment. Those are designed for the experiment-on-dataset workflow, not for scoring existing project spans. If you’re evaluating dataset rows in an experiment, those primitives are what you want; for scoring spans from a production project, the phoenix.evals library above is the recommended path. The (future) Experiments concepts section covers the Arize AX-native experiment evaluators in depth.