When code beats a judge
Code is the right runtime when the question can be expressed as a deterministic check. The litmus test:Could two people, given the same span attributes and the same rubric, ever disagree on the answer?If the answer is no — the check is purely mechanical — then a code evaluator is the right choice. It will be cheaper, faster, more reliable, and easier to debug than an LLM-as-a-judge for the same question. Examples that are deterministic checks:
- Does the response contain any of these forbidden keywords (a competitor’s name, a slur, an internal codename)?
- Does the JSON in the response parse, and does it have the expected shape?
- Does the tool call use the correct parameter names?
- Is the response length under a hard limit?
- Does the SQL the agent generated parse?
- Does the URL the agent emitted resolve to an allow-listed domain?
- Is the response helpful?
- Does the response stay on topic?
- Is the tone professional?
- Is the response factually correct given the retrieved context?
- Is the chain of tool calls coherent?
Two ways to author a code evaluator
The platform exposes two paths for code evaluators:Built-in templates
A library of pre-built code evaluators that cover common deterministic patterns. The most common ones:- Contains any keyword — flags spans whose output (or another attribute) contains any string in a configured list. The classic competitor-name-detector.
- JSON shape validator — flags spans whose output isn’t valid JSON, or doesn’t match a configured schema.
- Regex match — flags spans matching a configured pattern.
- Numeric threshold — flags spans where a numeric attribute is above or below a threshold (latency, token count, custom metrics).
--task-type code_evaluation.
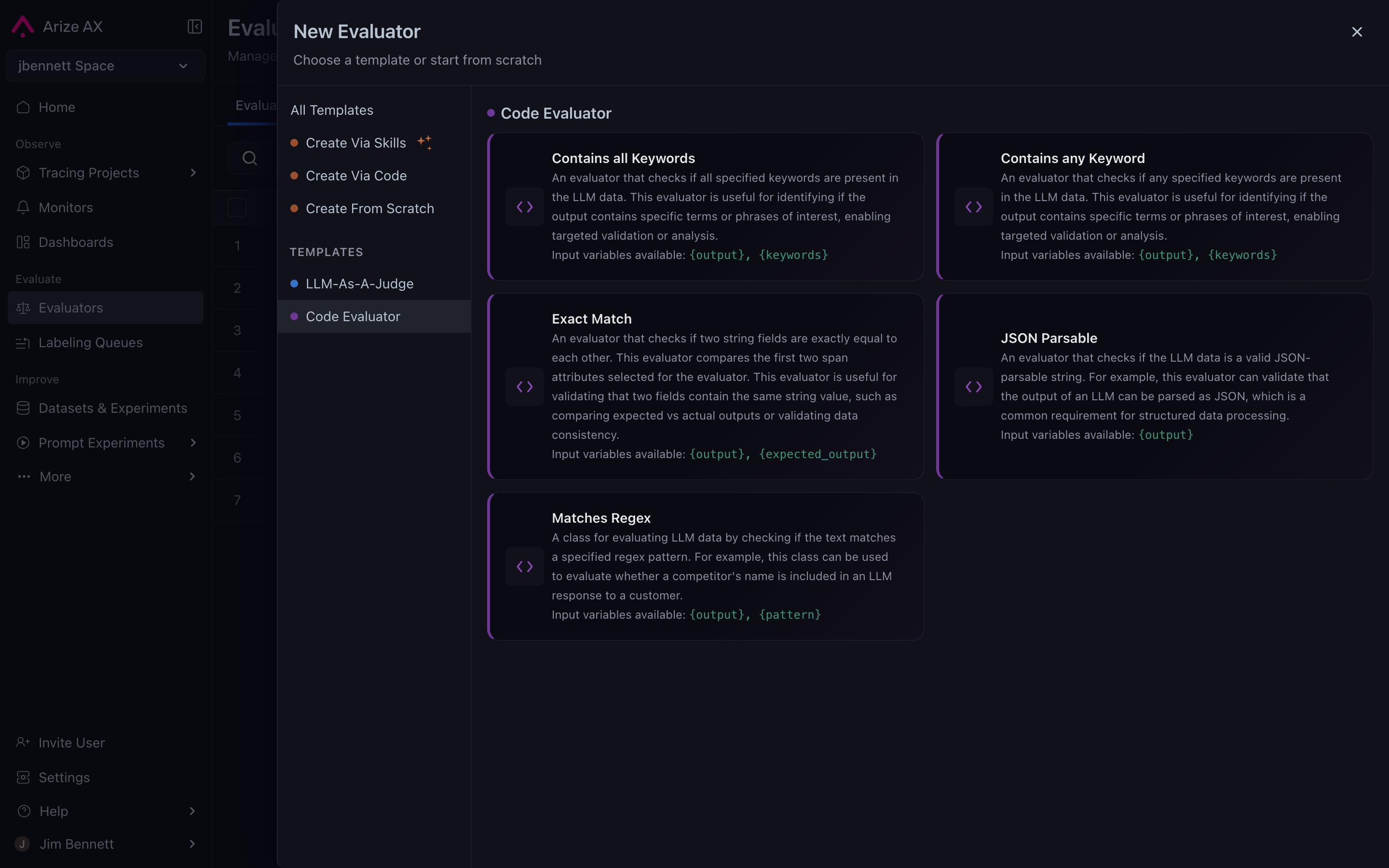
Built-in code evaluator templates — pick a shape, configure it in the UI, no Python required.
Custom Python class
When the built-in templates don’t cover your question, you can write a custom evaluator as a small Python class. The shape of the class is fixed by the platform. The custom path is reached by choosing Create From Scratch from the New Evaluator dialog, which then lets you pick an authoring surface — including handing the work to Alyx if you’d rather describe what you want than write the class by hand: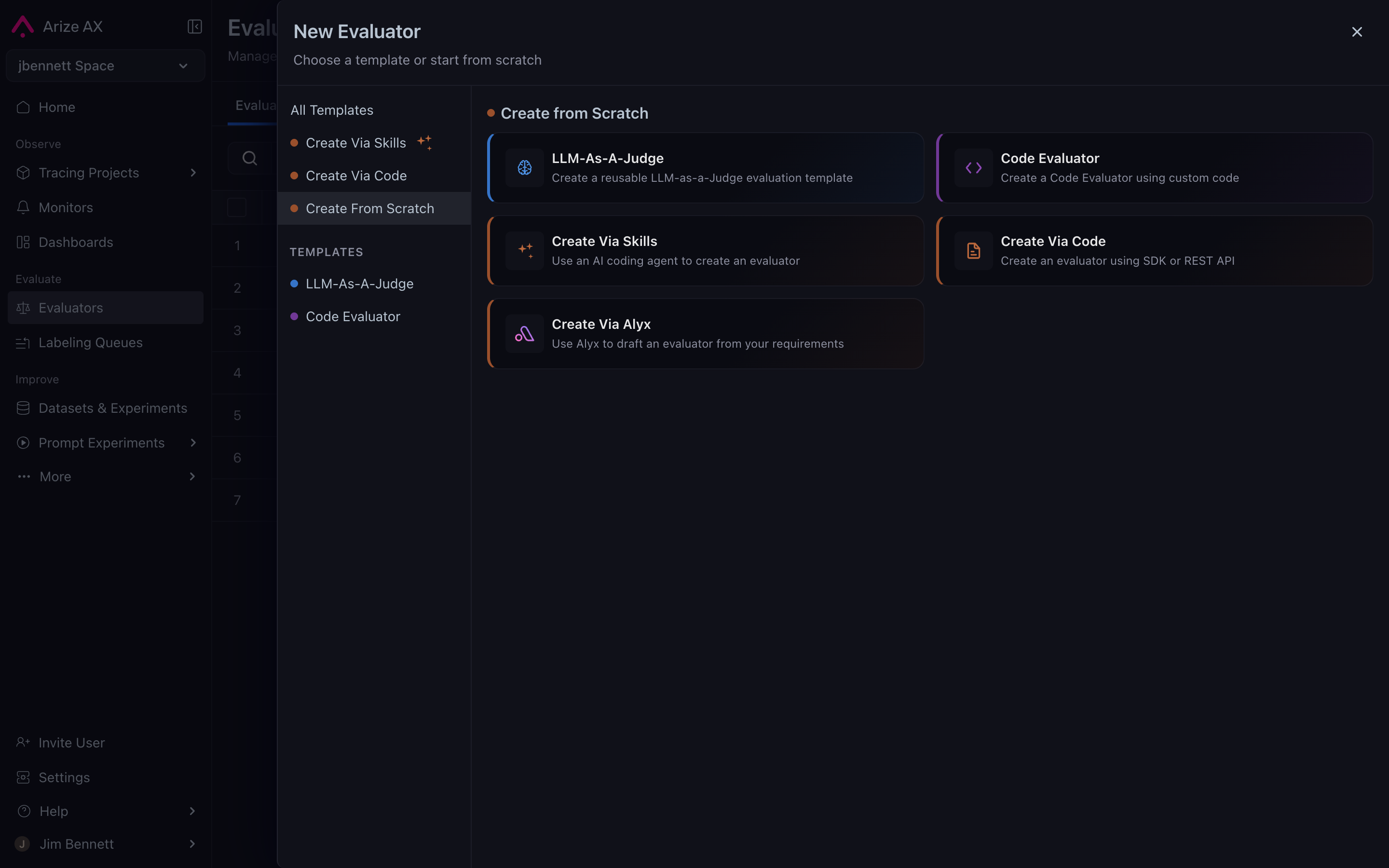
Create From Scratch offers five authoring paths, including handing the work to Alyx.
- Input is a span object. The evaluator reads
span.attributes, which is the same structure that lands in the trace tree. Trace and session evaluators see a wrapper that contains multiple spans, but the principle is the same. - Output is an
EvaluationResult. Same anatomy as every other evaluator — label, score, optional explanation. See Anatomy of an evaluator. - The runtime is the platform’s, not yours. You write the class; Arize AX runs it. The execution environment is platform-managed, so the set of available imports and runtime affordances is constrained — the Code evaluations how-to documents what’s currently available.
What the platform manages
A code evaluator gets the same managed-orchestration story as LLM-as-a-judge:- Triggering on new traces (continuous cadence) or on demand (historical batch).
- Filtering via task and evaluator data filters.
- Sampling.
- Joining results back to the originating span as
eval.<name>.*attributes.
Code evaluators as guardrails
A common pattern: use a code evaluator as a runtime guardrail, not just a post-hoc scoring tool. The evaluator runs continuously on new traces, the score lands as a span attribute, and downstream alerts (in Arize AX or in your alerting system) fire when the score crosses a threshold. The classic example is the competitor-name filter — a code evaluator that scores0 whenever the chatbot mentions a competitor by name. It runs on 100% of production traces; any non-zero count over a five-minute window pages someone. That’s faster, cheaper, and more reliable than asking an LLM-as-a-judge the same question.