The three paths
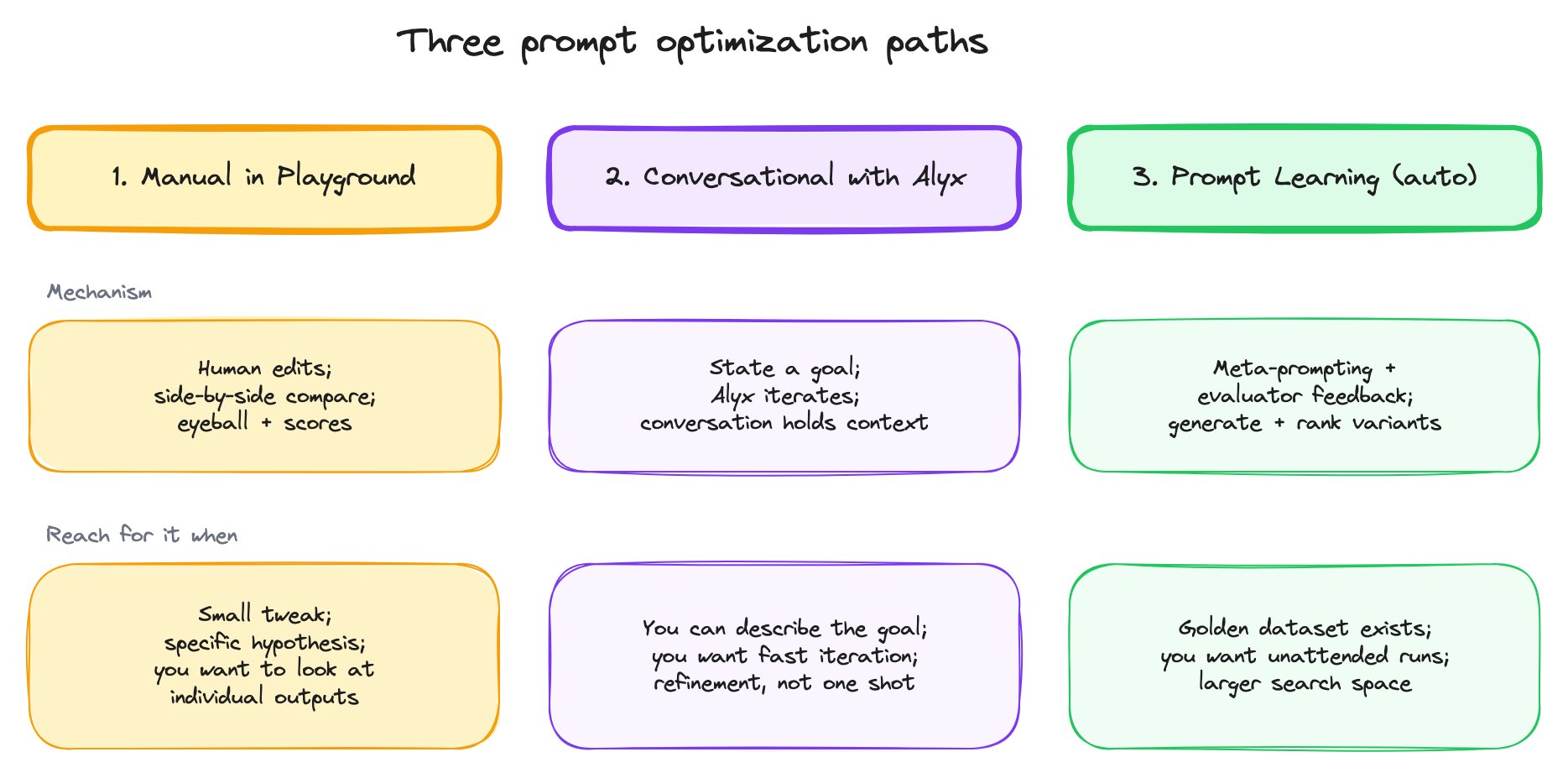
Three optimization paths — manual / Alyx / Prompt Learning — with the conditions each one fits.
Path 1 — Manual in the Playground
The Playground is the workshop. You load a prompt, run it against a dataset, see scores, edit, run again. With side-by-side comparison, you can run up to three variants in parallel and see the deltas immediately. When this is the right path:- Small tweaks — adjusting a sentence in the system message, tightening a constraint.
- Specific hypotheses — “I think temperature 0.3 will be better than 0.7 for this task; let me check.”
- Visual inspection — you want to look at individual outputs and form a judgment, not just look at aggregate scores.
- Exploratory iteration — you don’t know yet what would help; you’re trying things to learn what’s possible.
Path 2 — Conversational with Alyx
Alyx is the AI agent built into Arize AX. For prompt optimization, the workflow is:- “Optimize my prompt to reduce verbosity while keeping the escalation rules.”
- “Make this prompt produce a single tool name with no extra text.”
- “Tighten the prompt against this golden dataset — the scores are too low.”
- You can name the goal. If you can describe what “better” means in a sentence, Alyx can usually iterate toward it.
- You don’t want to write code. Conversational interfaces are faster than code interfaces for goal-driven changes.
- You want refinement, not just one shot. The conversation thread holds context, so each iteration sharpens the previous one.
Path 3 — Prompt Learning (automated)
Prompt Learning is the most hands-off path. It’s an automated loop:- You point it at a starting prompt and a dataset that includes evaluator feedback (labels and explanations) on prior outputs.
- It uses meta-prompting — an LLM analyzes the prompt + the feedback + the data — to propose a revised prompt.
- It runs the revised prompt against the dataset and scores it.
- It repeats, ranking variants by score, converging on the best one.
- Larger-scale optimization. When manual iteration would take too long because the search space is big.
- A golden dataset already exists. Prompt Learning needs labeled examples (or evaluator feedback) as its training signal.
- You want it to run unattended. Fire-and-forget loops are exactly Prompt Learning’s shape.
- Multiple competing objectives. Multi-evaluator feedback can guide the optimization across several criteria at once.
Picking a path
A rough decision tree:- You have a specific small change in mind → manual in the Playground.
- You can describe the goal in a sentence → Alyx.
- You have a golden dataset and want unattended optimization → Prompt Learning.
You’ve reached the end of this section
You now have the conceptual on-ramp for prompts in Arize AX:- Why prompts are engineering artifacts, and the iteration cycle they live inside.
- The five parts of a Prompt Object — template, model, invocation parameters, tools, response format.
- How versioning and tags work, and what that buys you.
- The Hub as the centralized repository, the Playground as the iteration surface.
- How prompts load into your application via the SDK + local cache.
- Datasets, ground truth, and labeling queues.
- Experiments as the unit of comparison; CI/CD as the way to enforce a bar.
- Three optimization paths and when each one fits.