The split
Most teams start online and graduate to offline only when they hit the flexibility ceiling. Online evaluators get you most of the value with none of the orchestration work; offline evaluators are the escape hatch when you need something the platform doesn’t expose.
Online evaluators
Online evaluators live entirely in Arize. You build them in the UI, the platform runs them, and the results flow back to the originating spans automatically. The platform handles:- Triggering. As traces arrive (continuous cadence) or on demand (historical batch), Arize fires the evaluator.
- Execution. The eval prompt is rendered against the trace data, the model is called, and the output is parsed.
- Joining. The label, score, and explanation are written back as
eval.<name>.*attributes on the originating span. - Sampling, rate-limiting, retries. Production-volume concerns are managed by the platform.
- Online LLM-as-a-judge: an LLM scores each span/trace/session. No code required — the evaluator is a prompt + a model + an output schema, all configured in the UI.
- Online code evaluator: a Python function (or a built-in template like contains-any-keyword) scores each span/trace/session. Code is required, but minimal — the function shape is fixed and the platform runs it for you.
Offline evaluators
Offline evaluators don’t run in Arize. You write the orchestration yourself: download the spans you want to evaluate, score them with whatever pipeline you choose, and upload the results back to Arize so they join their source spans. The shape of an offline evaluator is always the same three steps: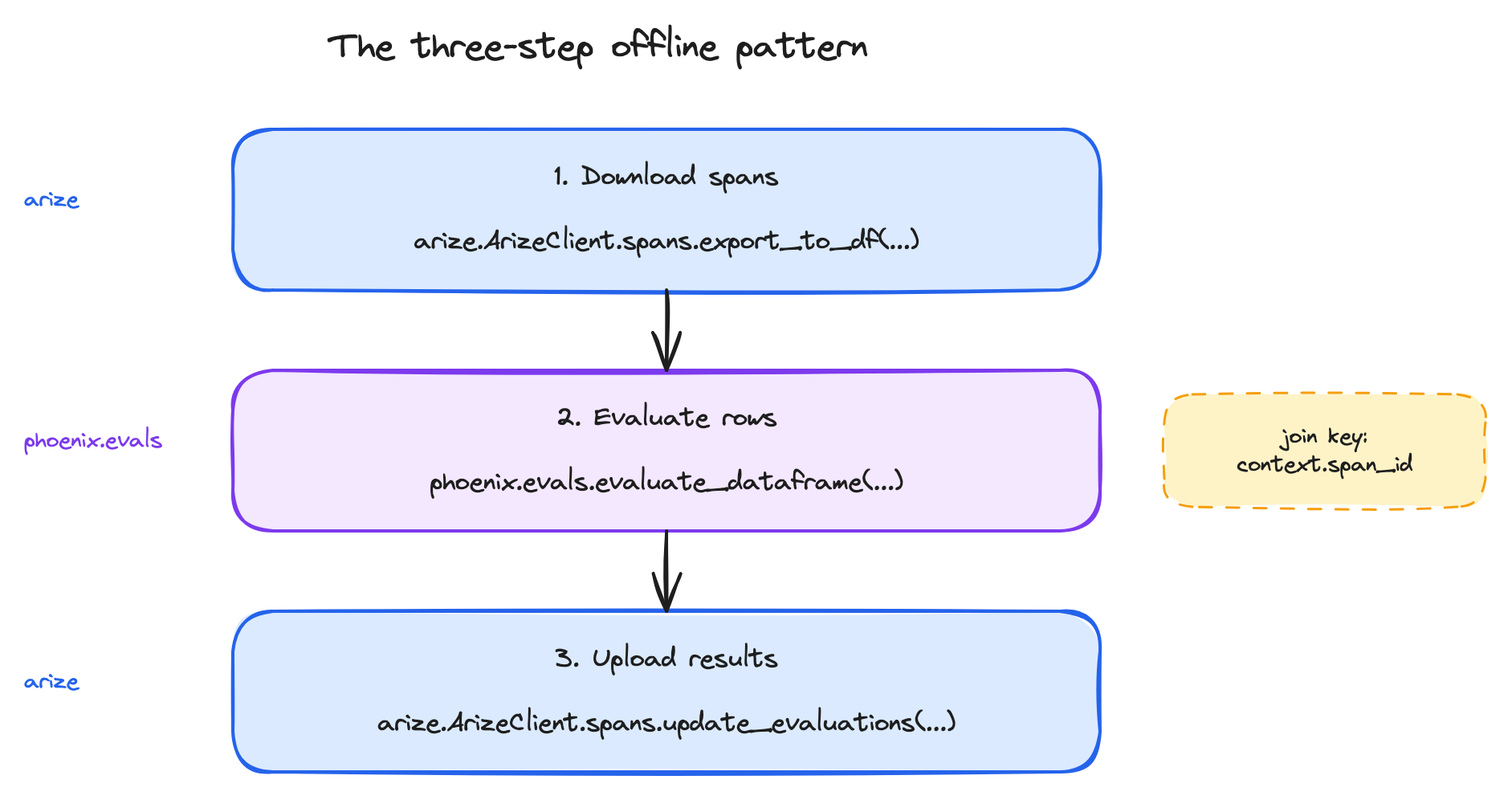 The recommended library for step 2 is
The recommended library for step 2 is phoenix.evals — the open-source Phoenix evaluations library. It handles the LLM call, rate-limiting, structured-output parsing, and concurrency. Using it doesn’t require running a Phoenix server; it’s just a Python library that knows how to call an LLM for classification.
When offline is the right choice:
- Multi-stage pipelines. You want one evaluator’s output to feed another evaluator’s input.
- Parallel evaluation. You want to run a dozen evaluators against the same span batch concurrently.
- Custom data shaping. You need to join multiple span attributes, derive new fields, or compute aggregates before scoring.
- Non-standard models. Your judge isn’t OpenAI, Anthropic, or one of the platform-supported providers.
- CI integration. You want eval results to land in your build artifacts, not just the Arize AX UI.
- One-off analyses. A research question that doesn’t justify creating a long-running evaluator task.
- You just want to score every new trace as it arrives. That’s exactly what online continuous evaluators do, with no orchestration cost.
- You want the platform to handle retries and rate limits. That’s a feature of online.
Both can run on the same spans
Online and offline aren’t mutually exclusive. The same spans can be scored by:- An online evaluator running continuously on new traffic.
- An offline evaluator running monthly across a historical window.
- A human reviewer annotating a sample of edge cases.
eval.<name>.* attributes with different <name> values. The platform merges everything into the same view. This is what makes evaluators a stack rather than a switch — you can layer cheap automated evaluators on top of expensive periodic human-validated ones without picking one strategy.