


In today’s world, it is all too common to read about AI acting in discriminatory ways. From real estate valuation models that reflect the continued legacy of housing discrimination to models used in healthcare that amplify inequities around access to care and health outcomes, examples are unfortunately easy to find. As machine learning (ML) models get more complex, the true reach of this issue and its impact on marginalized groups is not likely fully known. Fortunately, there are a few simple steps that ML teams can take to uproot harmful model biases across the ML lifecycle.
What Is Algorithmic Bias?
Algorithmic bias is the tendency of a machine learning model to make consistent, systematic errors in its predictions. A model will tend to systematically learn the wrong signals by not considering all the information contained within the data. Model bias may lead an algorithm to miss the relevant relationship between data inputs (features) and targeted outputs (predictions). In essence, bias arises when an algorithm has insufficient capability in learning the appropriate signal from the dataset. For decades, bias in machine learning has been recognized as a potential concern, but it remains a complex and challenging issue for machine learning researchers and engineers when deploying models into production.
How Does Bias Get Introduced Into a Model?
Biases can be introduced into the machine learning process and reinforced by model predictions from a variety of sources. At various phases of the model’s development, insufficient data, inconsistent data collecting, and poor data practices can all lead to bias in the model’s decisions. While these biases are typically unintentional, their existence can have a substantial influence on machine learning systems and result in disastrous outcomes — from employment discrimination to misdiagnosis in healthcare. If the machine learning pipeline you’re using contains inherent biases, the model will not only learn them but will also exacerbate and maybe even amplify them.
Identifying, assessing, and addressing any potential biases that may impact the outcome is a crucial requirement when creating a new machine learning model and maintaining it in production. As machine learning practitioners, it is our responsibility to inspect, monitor, assess, investigate, and evaluate these systems to avoid bias that negatively impacts the effectiveness of the decisions that models drive.
Causes of bias in models span both the data and model itself.
| Bias Types | Application | Examples |
| DATA: Representation bias |
|
|
| DATA: Measurement Bias |
|
|
| MODEL: Aggregation Bias |
|
|
| MODEL: Evaluation Bias |
|
|
Parity Prerequisites
Defining Protected Attributes
Of course, you can’t quantify harmful model bias without first defining who is being protected.
Knowing protected classes under the law is a good first step. Most Americans probably know that the U.S. Civil Rights Act of 1964 precludes discrimination on the basis of race and sex, for example, but fewer may know that other attributes – like genetic information or citizenship – also qualify as protected classes under the law and can result in millions or billions of dollars in fines when violations occur.
Legal compliance is just a starting point. Many large enterprises also go beyond these legal requirements and have additional protected classes or public commitments to diversity and equity.

Defining Fairness
Once you are clear on protected classes in all relevant jurisdictions, the next step is defining what fairness looks like. While this is a complex topic, a few fundamentals can help.
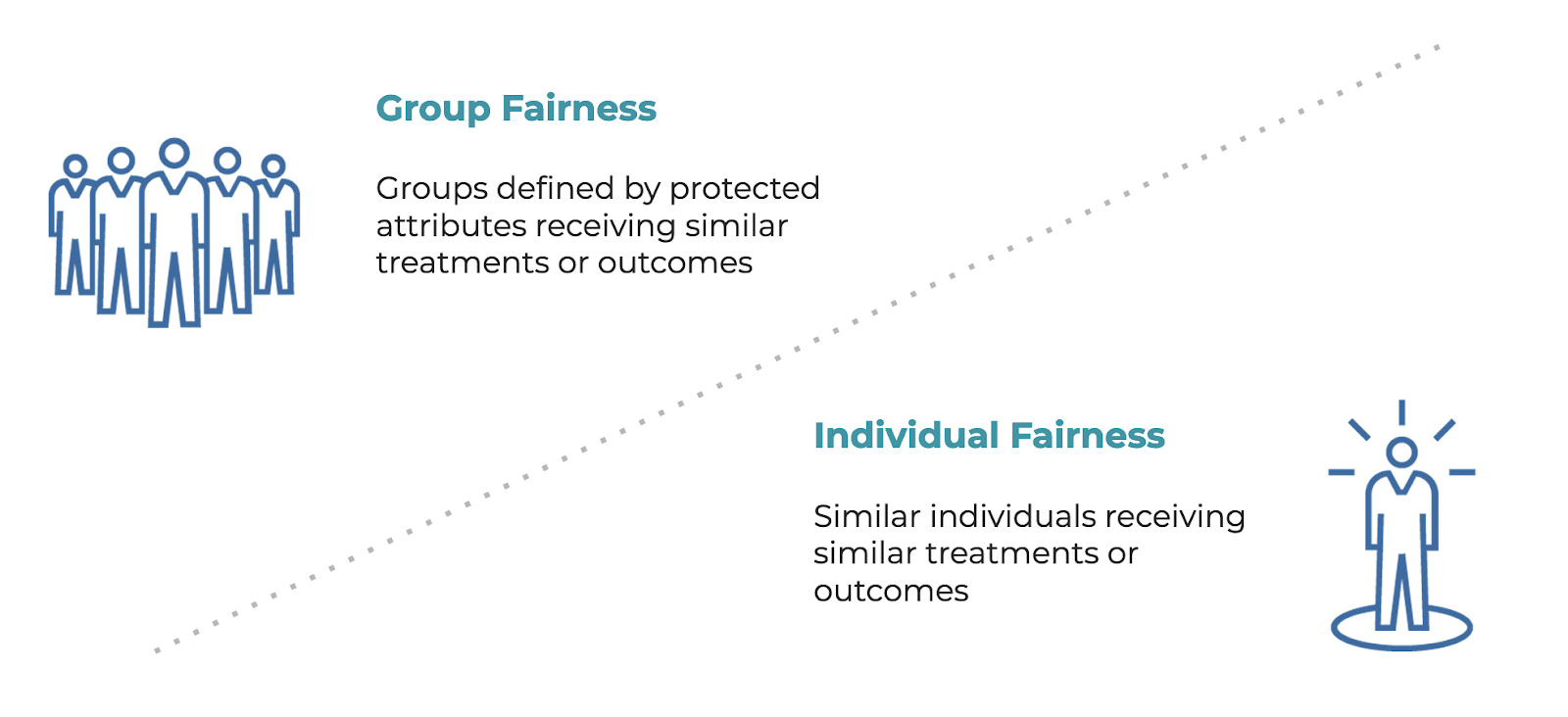
One primary distinction is the difference between group (equal and proportional) fairness and individual fairness.
- Group fairness is defined by protected attributes receiving similar treatments or outcomes
- Individual fairness is defined as similar individuals receiving similar treatments or outcomes
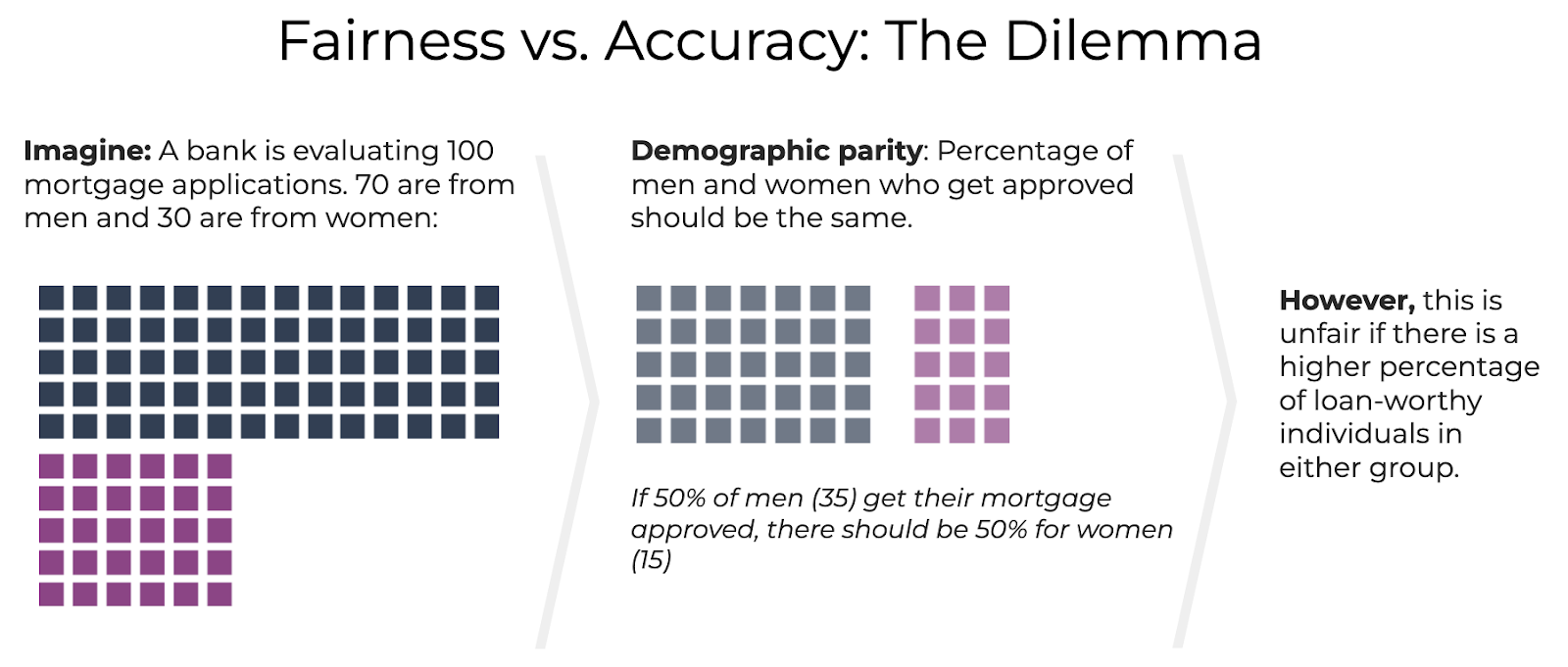
For example, imagine a bank that is evaluating 100 mortgage applications. 70 applications are from men and 30 from women. For group fairness based on equal percentages, you would approve 50% of applications for men (35) and 50% for women (15). For group fairness based on equal numbers, on the other hand, 50 approvals would be spread evenly – 25 for men and 25 for women. Either outcome might be considered unfair if there is a higher percentage of loan-worthy individuals in either group. One prevailing approach in the industry to mitigate model bias is to ensure prediction accuracy is the same for each group – a measure of equal opportunity versus accuracy.
What Are the Data Modeling Stages That Are Vulnerable To Bias?
According to Practical Fairness by Aileen Nielsen, model fairness impacts the pre-processing, in-processing, and post-processing stages of the data modeling pipeline. Fairness interventions, or actions taken to ensure that the model is not biased against certain groups, should be implemented at each stage of this process.
| Stage In Model Lifecycle | What Is It? | Why Intervene On Model Fairness At This Stage? | How can you achieve fairness intervention at this stage? | Examples |
| Pre-processing | Pre-processing is the earliest stage of data processing, during which data is translated into inputs for a machine learning model. | Intervening at this earliest stage in the ML lifecycle can have a big impact on the data modeling process and downstream metrics. |
|
A bank interested in building a model to predict loan defaults might sample data to ensure that it includes a representative mix of applicants from different races, genders, and geographic locations before removing sensitive variables from the data to prevent them from being used in the model. |
| In-processing | In-processing refers to any action that changes the training process of a machine learning model. | If we can’t intervene at the earliest (pre-processing) due to computational constraints or constraints on proprietary or licensed data, the next best option for addressing model fairness is in the training process. Intervening at this stage can allow teams to keep their training data sets raw and unaltered. |
|
A medical provider training a model predicting patient outcomes might create an adversary model to use outputs from the target model to predict for a protected category for the patient. This is to be sure that a patient’s personal information (like, income, race and gender) aren’t predictors of their healthcare outcome. |
| Post-processing | Post-processing takes place after the model has been trained on processed data. | When teams inherit a model from a prior team without any knowledge of that model, this may be their earliest stage of fairness intervention. |
|
A broadband provider with a model that predicts customer churn wants to ensure it does not discriminate in offering discounts to customers. They implement fairness checks with fairness-specific metrics as part of the model deployment process.
Bias tracing then monitors model performance on a diverse set of customers to ensure that it is not biased against any particular group to ensure that outputs remain fair. If there is algorithm bias present, the decisions are equalized. |
What Are Prevailing Model Fairness Metrics?
There are a wealth of model fairness metrics that are appropriate depending on your goal. Here are definitions and recommendations for prevailing metrics and where to use each.
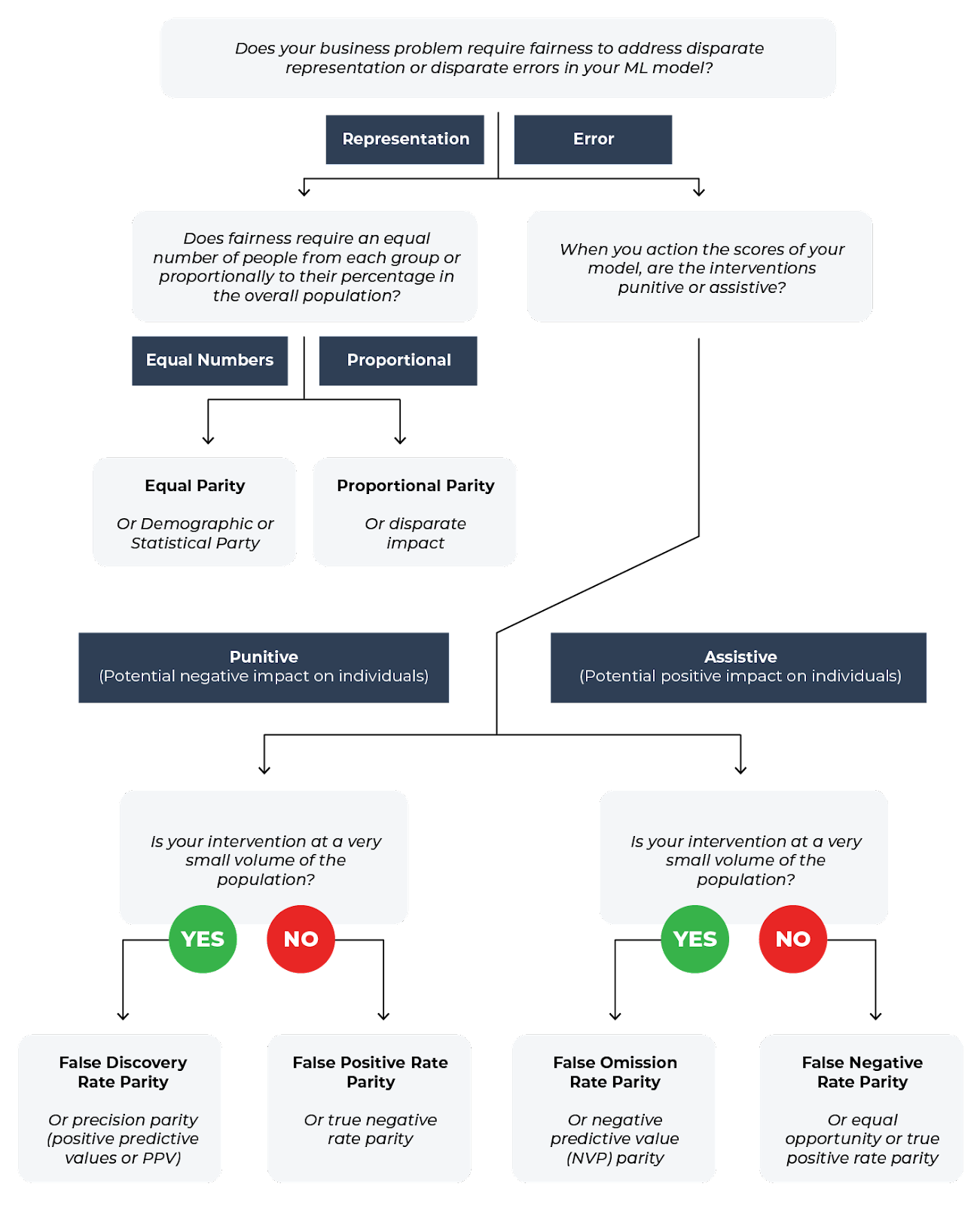
When deciding on which fairness metric or metrics to use, you must think about what insights you need to ensure your model is not acting discriminately. Teams that care about fairness – especially those working in highly regulated industries such as health, lending, insurance, and financial services — typically want to see if their models are fair and unbiased across sensitive attributes (i.e. race or sex). When a model is biased, teams then need to know which group is experiencing the most bias so that action can be taken.
To understand the fairness metric value for the period of time you are evaluating, many companies use the four-fifths rule. The four-fifths rule is a threshold that is used by regulatory agencies like the United States Equal Employment Opportunity Commission to help in identifying adverse treatment of protected classes. Since an ideal parity score is 1, when leveraging the four-fifths rule you typically measure whether your fairness metric parity score falls outside of the 0.8-1.25 threshold. If the parity score is less than 0.8 or greater than 1.25, algorithmic bias against the selected sensitive group may be present in your model.
From the decision tree above, we can see how the fairness metric of choice depends on whether your model is addressing disparate representation, equal numbers or assistive actions.
Let’s look at when and where to use these metrics:
| Metric | Definition | When to use it | How is it calculated |
| Recall Parity | Measures how “sensitive” the model is for one group compared to another, or the model’s ability to predict true positives correctly. | Recall parity is achieved if the recall in the subgroups are close to each other. | Recall Parity = Recall_sensitive / Recall_base
Recall = TP / (TP + FN) |
| False Positive Rate Parity | Measures whether a model incorrectly predicts the positive class for the sensitive group as compared to the base group. | False positive rate parity is achieved if the false positive rates (the ratio between the number of false positives and the total number of negatives) in the subgroups are close to each other. | False Positive Parity = FPR_underprivileged_group / FPR_privileged_group
False Positive Rate = FP / (FP + TN) |
| Disparate Impact | A quantitative measure of the adverse treatment of protected classes | Disparate impact, also known as proportional parity, is used to check whether the ratio of outcomes for different groups is the same as the ratio of their presence in the population. | If a job offer rate for men is 50% and the job offer rate for women is 25%, then the ratio of the two rates is 2, indicating disparate impact. |
Once you have defined fairness in the context of your business problem by consulting the fairness tree, you can calculate your parity scores and use the four-fifths rule to determine if you need to intervene at the pre-processing, in-processing, or post-processing stage in your model development pipeline. For a cheatsheet on the type of parity you want to achieve to demonstrate algorithmic neutrality, see below.
| Parity Check | Description | Calculation |
| Type 1 Parity | Fairness in both false discovery rate (FDR) parity and false positive rate (FPR) Parity | FDR = FP / (TP+FP)
FPR = FP / (TN+FP) |
| Type 2 Parity | Fairness in both false omission rate (FOR) parity and false negative rate (FNR) parity | FOR = FN / (TN + FN)
FNR = FN / ( TP + FN) |
| Equalized Odds | Fairness in both false positive rate (FPR) parity and true positive rate (TPR) parity | FPR = FP / (TN+FP)
TPR = TP / (TP + FN) |
| Supervised Fairness | Fairness in both Type 1 and Type 2 parity | See above |
| Overall Fairness | Fairness across all metrics used in a confusion matrix | FP, TP, FN, TN |
FP = False Positive, TP = True Positive, FN = False Negative, TN = True Negative
Model Bias Tools
There are a variety of tools built to help tackle algorithmic bias across the ML lifecycle.
Model Building & Validation
Most solutions focus on tackling the initial stages of model development, with the goal of providing model fairness checks before a model is shipped.
Examples of tools:
- Arize AI: offers model fairness checks and comparisons across a training baseline and production data; ideal for teams that want root cause workflows and to tackle validation and production monitoring from the same platform.
- Aequitas: an open-source bias audit toolkit to audit machine learning models for discrimination and bias. Useful for basic one-time audits to know if there is a problem; lacks workflows for root cause analysis.
- IBM Fairness 360: an open source toolkit can help you examine, report, and mitigate discrimination and bias in machine learning models. This tool is also more geared toward one-time audits.
- Google’s PAIR AI: offers several tools useful for specific use cases, including a tool for mitigating fairness and bias issues for image datasets supported by the TensorFlow Datasets API.
- Facebook Fairness Flow: an internal toolkit used by Meta assess model fairness and things like potential bias in labels. Not available to external users.
While some of these tools can be used for aggregated fairness metrics and after-the-fact explanations (i.e. model explainability) useful for audits, they are mostly not designed for real-time monitoring in production.
How Should Teams Resolve Model Bias?
Resolving model bias starts with understanding the data, ensuring teams have the right tools, and ensuring organizational governance is set up to ensure fairness. Teams need to be aware of the pre-processing, in-processing, and post-processing stages of the data modeling pipeline that are valuable to bias– therefore fairness intervention needs to be present in one, if not more, of these stages. In order to achieve fairness at these stages we need to:
Step 1: Make protected class data available to model builders and ML teams maintaining models in production.
According to a recent survey, 79.7% of ML teams report that they “lack access to protected data needed to root out bias or ethics issues” at least some of the time, and nearly half (42.1%) say this is an issue at least somewhat often. This needs to change. As one researcher puts it, there is no fairness through unawareness.
Step 2: Ensure you have tools for visibility into fairness in production, ideally before models are shipped.
Coupling fairness checks at the model-building stage with periodic after-the-fact audits is insufficient in a world where model bias can cause real-world harm. Continuous monitoring and alerting can help surface blindspots (unknown unknowns) that inevitably creep up in the real world and speed up time-to-resolution. When model owners and ML engineers maintaining models in production have optimized guidance and tools, good things happen.
Step 3: Be an internal change agent and act with urgency.
Addressing model bias is not merely about machine learning. Many challenges – such as tradeoffs between fairness and business results or diffused responsibility across teams – can only be resolved with multiple teams and executive involvement. ML teams are well-positioned to play a key role in building a multi-pronged approach that combines purpose-built infrastructure, governance, and dedicated working groups for accountability.
Monitoring In Production
Monitoring fairness metrics in production is important for a simple reason: when it comes to deployed AI, it is a matter of when – not if – model bias will occur. Concept drift, new patterns not seen in training, training-serving skew, and outliers challenge even the most advanced teams deploying models that perform flawlessly in training and pass the validation stage.
Here are some platforms that offer real-time fairness monitoring in production:
- Arize: automatic monitors and fairness checks, with multidimensional comparisons to uncover model features and cohorts contributing to algorithmic bias
- DataRobot: monitors fairness metrics like proportional parity with workflows to compare production data tor training
Of course, identifying the problem is only half the battle. ML observability and associated workflows to quickly trace the cause of a model fairness issue at a cohort level is critical in informing when to retrain or revert to a prior model (or no model).
Sign up for a free Arize account and see how the platform can help you monitor fairness metrics in production today.